

Una alternativa de más alto nivel que el TDD pero más sencilla que el ATDD, enfocada en el comportamiento visible e implementada como tests unitarios.
Índice de contenidos
- 1. Introducción
- 2. Entorno
- 3. Enfoque
- 4. A programar
- 5. Conclusiones
- 6. Referencias
1. Introducción
Recientemente, Uncle Bob daba a conocer en un tweet la que según él era “una de las mejores charlas que había visto en la última década”.
La charla se titula “TDD, where did it all go wrong” y en ella Ian Cooper razona sobre el estado actual del TDD y cómo solucionar sus problemas volviendo a las raíces tal y como las planteó Kent Beck en “Test-Driven Development by example”.
1.1. BDD
No voy a resumir aquí toda la charla, lo mejor es verla por ti mismo.
Y ya existe un tutorial para conocer más detalles sobre BDD y qué aporta sobre TDD.
Básicamente, Ian Cooper propone usar tests unitarios para hacer BDD, es decir, que nuestros tests unitarios validen el comportamiento visible de nuestros componentes como si fueran una caja negra.
Esto es ni más ni menos que testear el contrato del API de los componentes.
En la sección de Conclusiones puedes leer sobre el por qué de esta elección y qué alternativas hay.
En la charla también se dice cómo encajan los tests de integración en este modelo, sobre todo con una arquitectura hexagonal.
El tutorial también cubrirá esa parte.
1.2. Microservicios hexagonales
Tampoco voy a explicar aquí en qué consiste una arquitectura de microservicios.
Sólo me interesa poner sobre el escenario un tipo de aplicación que tiene unas APIs bien definidas para exponer una funcionalidad.
Una buena manera de diseñar un microservicio es mediante arquitectura hexagonal:
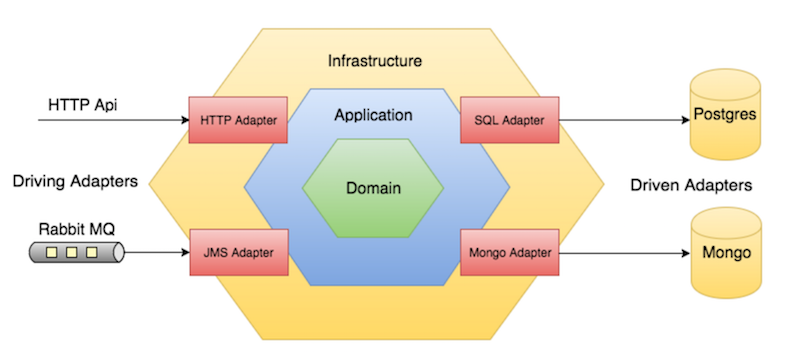
En el núcleo del hexágono está el modelo del dominio.
El dominio está envuelto por la lógica de aplicación, a la que se enganchan adaptadores para los puertos que dan acceso al mundo exterior: bases de datos, clientes o servicios REST, colas de mensajes o buses de eventos.
Lo más importante es la dirección de las dependencias, de fuera hacia dentro. Por ejemplo, el modelo del dominio no puede depender del adaptador REST pero al revés sí.
1.3. Caso práctico
En este tutorial vamos a desarrollar un microservicio con Spring Boot 2.0 que permite recuperar perfiles de clientes a través de un API REST.
Además, el servicio expone un puerto Kafka para ser notificado cuando se crea un nuevo cliente y otro puerto hacia una base de datos relacional donde guardar una copia de los perfiles.
Seguiremos la técnica BDD para validar que el microservicio cumple los requisitos funcionales especificados.
El código completo del tutorial está disponible en GitHub: https://github.com/dav-garcia/bdd-spring-boot
2. Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 15′ (2.5GHz Intel Core i7, 16GB DDR3).
- Sistema Operativo: MacOS High Sierra 10.13.6
- Oracle Java: 1.8.0_161
- Apache Maven: 3.6.0
- Spring Boot: 2.0.5.RELEASE
3. Enfoque
¿Cómo proceder según el enfoque de Ian Cooper?
Primero, haremos un test unitario del servicio que recupera el perfil de un cliente del repositorio.
El componente a probar (SUT – System Under Test) es la lógica de aplicación y el modelo, así que habrá que mockear el repositorio de base de datos.
Después, otro test unitario validará que cuando se crea un cliente, su perfil se envía al repositorio.
El SUT aquí es otra parte de la lógica de aplicación y el modelo, mientras que el repositorio es sólo un mock.
Por último, haremos tres tests de integración, uno por cada adaptador:
- Verificar que el repositorio guarda y recupera perfiles de usuario de la base de datos.
- Verificar que el endpoint REST llama al servicio de recuperación del perfil.
- Verificar que al recibir un evento de Kafka se llama al servicio que guarda el perfil del cliente.
Así, con 5 tests bastante sencillos tenemos cubierto todo el comportamiento del «happy path».
A partir de aquí, se añadirían los caminos alternativos y el manejo de las situaciones de fallo.
4. A programar
4.1. Creación del proyecto
Ve a https://start.spring.io/ y crea un proyecto Maven con Java y la última versión estable de Spring Boot.
Puedes poner com.autentia.tutoriales como groupId y bdd-spring-boot como artifactId.
No añadas ningún starter por ahora, en teoría aún no sabemos qué vamos a necesitar.
4.2. Test unitario de recuperación de perfil
4.2.1. Primeros pasos
Empezamos probando un servicio bajo la interfaz ServicioConsultaPerfilCliente, definiendo esta interfaz en el subpaquete servicio:
public interface ServicioConsultaPerfilCliente {
RespuestaPerfilCliente consultar(UUID idCliente);
}De ahí nos surge la necesidad de definir la clase vacía RespuestaPerfilCliente en el subpaquete vo.
Volviendo a la clase de servicio, crearemos el test unitario.
En cualquier IDE suele haber una opción para navegar entre clase de test y clase testeada que genera el test la primera vez.
En IntelliJ pulsamos Cmd + Mayúsculas + T y aceptamos el nombre sugerido ServicioConsultaPerfilClienteTest.
Ahora añadimos el primer test para el camino feliz:
public class ServicioConsultaPerfilClienteTest {
private final ServicioConsultaPerfilCliente sut = null;
@Test
public void dadoIdClienteExistenteEntoncesDevuelvePerfilCliente() {
// Given
UUID id = UUID.randomUUID();
// When
RespuestaPerfilCliente result = sut.consultar(id);
// Then
assertThat(result, is(not(nullValue())));
}
}Recuerda que los matchers que estamos usando en el assert vienen de Hamcrest:
import static org.hamcrest.Matchers.*;4.2.2. El servicio devuelve algo
Como es normal, el test lanzará NullPointerException porque aún no existe ninguna implementación del servicio, así que vamos a añadir ServicioConsultaPerfilClienteImpl en el subpaquete servicio.impl:
public class ServicioConsultaPerfilClienteImpl implements ServicioConsultaPerfilCliente {
@Override
public RespuestaPerfilCliente consultar(UUID idCliente) {
return new RespuestaPerfilCliente();
}
}Y cambiar una línea en el test:
private final ServicioConsultaPerfilCliente sut = new ServicioConsultaPerfilClienteImpl();Ahora el test debería pasar. Si usas git, este es un buen momento para subir tu cambio.
4.2.3. El contenido devuelto es válido
Vamos a ponernos serios y a validar el contenido de la respuesta.
Primero añadimos a RespuestaPerfilCliente los atributos id, nombre, fechaNacimiento, email y telefono.
Después ampliamos los asserts del test:
// Then
assertThat(result, is(not(nullValue())));
assertThat(result.getId(), is(id));
assertThat(result.getNombre(), is("David"));
assertThat(result.getFechaNacimiento(), is(LocalDate.of(1976, 2, 28)));
assertThat(result.getEmail(), is("dgarciagil@autentia.com"));
assertThat(result.getTelefono(), is("+34 123456789"));Ejecutamos el test y volvemos al rojo.
Para arreglarlo hacemos lo mínimo necesario en ServicioConsultaPerfilClienteImpl:
@Override
public RespuestaPerfilCliente consultar(UUID idCliente) {
return new RespuestaPerfilCliente.Builder()
.withId(idCliente)
.withNombre("David")
.withFechaNacimiento(LocalDate.of(1976, 2, 28))
.withEmail("dgarciagil@autentia.com")
.withTelefono("+34 123456789")
.build();
}Fíjate que he definido un Builder dentro de RespuestaPerfilCliente. No es obligatorio pero facilita las cosas.
Toca hacer otro commit.
4.2.4. El perfil se recupera del repositorio
El criterio de aceptación dice que el perfil devuelto debe recuperarse de un repositorio.
Esto significa que ServicioConsultaPerfilClienteImpl llamará a un método de búsqueda sobre una interfaz RepositorioPerfilCliente que definiremos en el subpaquete repositorio:
public interface RepositorioPerfilCliente {
PerfilCliente findById(UUID id);
}También tenemos la entidad PerfilCliente como parte de nuestro modelo del dominio y también modelo de persistencia.
Defínela en el subpaquete modelo con el mismo contenido que RespuestaPerfilCliente.
Volvemos a ampliar el test con un nuevo atributo:
private final RepositorioPerfilCliente repositorio = null;Y más validaciones a continuación de las anteriores:
ArgumentCaptor idCaptor = ArgumentCaptor.forClass(UUID.class);
verify(repositorio).findById(idCaptor.capture());
assertThat(idCaptor.getValue(), is(id));
El test falla porque la variable repositorio es null.
Crearemos un mock en Spring, para lo cual tenemos que hacer dos cambios:
- Declarar el test como un test de Spring Boot:
@RunWith(SpringRunner.class) @SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.NONE) @DirtiesContext(classMode = DirtiesContext.ClassMode.BEFORE_CLASS) public class ServicioConsultaPerfilClienteTest { - Declarar que el atributo repositorio es un mock de Spring:
@MockBean private RepositorioPerfilCliente repositorio;
Ahora el test falla porque nadie llama al repositorio (“wanted but not invoked”).
- NOTA: Se puede pensar que hemos transformado el test unitario en un test de integración, pero lo que pasa es que nuestro SUT es la lógica de aplicación inicializada dentro de un contexto de Spring.
La anotación @DirtiesContext nos asegura la unicidad del test al menos a nivel de clase de test. Es un buen compromiso entre la velocidad de ejecución y el aislamiento, aunque siendo puristas deberíamos limpiar el contexto a nivel de método.
Volviendo al código, hay que inyectar el repositorio en ServicioConsultaPerfilClienteImpl y delegar a él la recuperación del perfil. Entonces, ese PerfilCliente hay que convertirlo a RespuestaPerfilCliente con un ConversorPerfilCliente que implementa Converter de Spring.
@Service
public class ServicioConsultaPerfilClienteImpl implements ServicioConsultaPerfilCliente {
private final RepositorioPerfilCliente repositorio;
private final ConversorPerfilCliente conversor;
@Autowired
public ServicioConsultaPerfilClienteImpl(RepositorioPerfilCliente repositorio, ConversorPerfilCliente conversor) {
this.repositorio = repositorio;
this.conversor = conversor;
}
@Override
public RespuestaPerfilCliente consultar(UUID idCliente) {
PerfilCliente perfil = repositorio.findById(idCliente);
return conversor.convert(perfil);
}
}El requisito de inyectar el repositorio y el conversor nos ha llevado a que el servicio ahora sea un bean de Spring con la anotación @Service.
El test sigue en rojo porque tenemos que entrenar el mock:
// Given
UUID id = UUID.randomUUID();
PerfilCliente perfil = new PerfilCliente.Builder()
.withId(id)
.withNombre("David")
.withFechaNacimiento(LocalDate.of(1976, 2, 28))
.withEmail("dgarciagil@autentia.com")
.withTelefono("+34 123456789")
.build();
doReturn(perfil).when(repositorio).findById(id);Ahora ya debería funcionar, momento de hacer commit.
4.3. Test unitario de registro de perfil
Para cumplir el requisito de registrar un nuevo perfil de cliente seguiremos unos pasos similares a los del apartado anterior, pero con otras clases:
- Definir el esqueleto del test sobre la interfaz ServicioEventoClienteCreado.
La interfaz tiene un método registrar() que recibe un EventoClienteCreado con las mismas propiedades que la entidad PerfilCliente. - Añadir un método save() a la interfaz RepositorioPerfilCliente para guardar el PerfilCliente.
- En el test, verificar que el servicio lo llama para guardar el perfil (verify() y ArgumentCaptor).
- Implementar ServicioEventoClienteCreadoImpl con la conversión del evento a PerfilCliente y posterior guardado en el repositorio.
4.4. Test de integración del adaptador de base de datos
- NOTA: Para correr los tests de integración he añadido el plugin Maven Failsafe en el POM.
Ha llegado la hora de conectarse a una base de datos y para ellos vamos a usar Spring Data JPA, Liquibase y H2 como motor para los tests.
Se escapa al ámbito de este tutorial entrar en estos temas, pero puedes encontrar todos los detalles en el código fuente de referencia.
Además, aquí estoy arrancando una base de datos H2, pero en un proyecto real el test de integración debería correr contra el SGBD que se vaya a utilizar.
La forma en que he abordado la verificación de esta integración es:
- Añadir las dependencias de spring-boot-starter-data-jpa, liquibase-core y h2 (en scope test).
- Definir el esquema de base de datos con Liquibase.
Aquí ya puedes hacer commit. - Hacer que la interfaz RepositorioPerfilCliente extienda JpaRepository.
- Cambiar los usos del método findById(), que en Spring Data devuelve un Optional.
En el mock del repositorio, simplemente hay que envolver el PerfilCliente en un Optional. - Anotar la clase del modelo de dominio PerfilCliente como entidad persistente.
La aplicación debería pasar los tests existentes; puedes hacer commit.
- NOTA: Aquí se podría abrir el debate sobre si vale la pena separar el modelo del dominio de las entidades persistentes.
Teniendo en cuenta que la base de datos es interna al microservicio y su estructura no está condicionada por ningún factor externo más allá del propio modelo del dominio, no veo que la separación aporte ninguna ventaja.
- Especificar el test de integración, que guardará un PerfilCliente y luego lo cargará:
@RunWith(SpringRunner.class) @SpringBootTest public class RepositorioPerfilClienteIT { @Autowired private PlatformTransactionManager platformTransactionManager; @Autowired private RepositorioPerfilCliente sut; @Test public void dadoQueGuardoUnRegistroEntoncesPuedoRecuperarlo() { // Given TransactionTemplate transactionTemplate = new TransactionTemplate(platformTransactionManager); UUID id = UUID.randomUUID(); PerfilCliente perfil = new PerfilCliente.Builder() .withId(id) .withNombre("David") .withFechaNacimiento(LocalDate.of(1976, 2, 28)) .withEmail("dgarciagil@autentia.com") .withTelefono("+34 123456789") .build(); // When transactionTemplate.execute(s -> sut.save(perfil)); Optional resultOpcional = transactionTemplate.execute(s -> sut.findById(id)); // Then PerfilCliente result = resultOpcional.orElse(null); assertThat(result, is(not(nullValue()))); assertThat(result.getId(), is(id)); assertThat(result.getNombre(), is("David")); assertThat(result.getFechaNacimiento(), is(LocalDate.of(1976, 2, 28))); assertThat(result.getEmail(), is("dgarciagil@autentia.com")); assertThat(result.getTelefono(), is("+34 123456789")); } }
Todo listo, hora de hacer commit.
4.5. Test de integración del adaptador REST
El siguiente adaptador a integrar es el endpoint REST.
Para ello, añadiremos la dependencia spring-boot-stater-web.
Entonces seguiré un enfoque más TDD para el test de integración:
4.5.1. Preparar el entorno del test
Primero definir la clase del test PerfilClienteControllerIT en el paquete rest.
Ejercitaremos el endpoint REST y pondremos un mock en la capa de servicio:
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class PerfilClienteControllerIT {
@MockBean
private ServicioConsultaPerfilCliente servicio;
@Autowired
private TestRestTemplate restTemplate;
@Test
public void dadoIdClienteExistenteEntoncesDevuelvePerfilCliente() {
// Given
// When
// Then
}
}4.5.2. Ejercitar el endpoint REST
La implementación inicial del test es sencilla: hacer un GET para recuperar un perfil de cliente:
// Given
UUID id = UUID.randomUUID();
// When
ResponseEntity result = restTemplate.getForEntity("/cliente/perfil/{id}", RespuestaPerfilCliente.class, id);
// Then
assertThat(result.getStatusCode(), is(HttpStatus.OK));
RespuestaPerfilCliente respuesta = result.getBody();
assertThat(respuesta.getId(), is(id));El test falla porque devuelve HTTP 404 en vez de 200.
4.5.3. Implementar controller del adaptador REST
Para ponerlo en verde primero implementamos el controller:
@RestController
public class PerfilClienteController {
private final ServicioConsultaPerfilCliente servicio;
@Autowired
public PerfilClienteController(ServicioConsultaPerfilCliente servicio) {
this.servicio = servicio;
}
@GetMapping("/cliente/perfil/{id}")
public RespuestaPerfilCliente get(@PathVariable String id) {
return servicio.consultar(UUID.fromString(id));
}
}4.5.4. Entrenar mock y validar respuesta
Y después configuramos el mock del servicio para que devuelva un objeto RepuestaPerfilCliente.
También sería bueno ampliar los asserts para validar los campos de la respuesta.
Tarea terminada y todo listo para hacer commit.
4.6. Test de integración del adaptador de Kafka
La validación de la integración con Kafka es similar a la anterior.
En este caso debemos añadir 3 dependencias: jackson-datatype-jsr310, spring-kafka y spring-kafka-test (en scope test).
La primera es para la serialización de fechas a JSON.
Los pasos a seguir son:
4.6.1. Preparar el entorno del test
Declarar la clase de test ConsumidorEventoClienteCreadoIT en el subpaquete bus.
@RunWith(SpringRunner.class)
@SpringBootTest
@EmbeddedKafka(topics = EventoClienteCreado.TOPIC,
brokerProperties = {"listeners=PLAINTEXT://localhost:9092", "auto.create.topics.enable=false"})
public class ConsumidorEventoClienteCreadoIT {
}4.6.2. Definir clase del evento
De aquí surge la necesidad de definir la clase EventoClienteCreado en el subpaquete evento.
Tendrá las mismas propiedades que PerfilCliente y como detalle extra, me gusta definir una constante con el nombre del topic donde se publicará.
4.6.3. Ejercitar consumo de eventos
En el test se definirá un productor de eventos EventoClienteCreado para verificar que dichos eventos son consumidos y pasados al ServicioEventoClienteCreado:
@Test
public void dadoEventoClienteCreadoEntoncesRegistraPerfilCliente() {
// Given
UUID id = UUID.randomUUID();
EventoClienteCreado evento = new EventoClienteCreado.Builder()
.withId(id)
.withNombre("David")
.withFechaNacimiento(LocalDate.of(1976, 2, 28))
.withEmail("dgarciagil@autentia.com")
.withTelefono("+34 123456789")
.build();
// When
kafkaTemplate.send(EventoClienteCreado.TOPIC, id, evento);
// Then
ArgumentCaptor eventoCaptor = ArgumentCaptor.forClass(EventoClienteCreado.class);
verify(servicio, timeout(10000)).registrar(eventoCaptor.capture());
EventoClienteCreado result = eventoCaptor.getValue();
assertThat(result, is(not(nullValue())));
assertThat(result.getId(), is(id));
assertThat(result.getNombre(), is("David"));
assertThat(result.getFechaNacimiento(), is(LocalDate.of(1976, 2, 28)));
assertThat(result.getEmail(), is("dgarciagil@autentia.com"));
assertThat(result.getTelefono(), is("+34 123456789"));
}Fíjate cómo se captura el objeto EventoClienteCreado pasado como parámetro al mock de ServicioEventoClienteCreado.
Debido al procesamiento asíncrono de eventos, esta captura tiene un timeout de 10 segundos.
En los fuentes del proyecto puedes ver más detalles sobre la configuración del test y la serialización de eventos.
4.6.4. Implementar consumidor de eventos
El test falla porque no hay ningún consumidor, así que vamos a definirlo en el subpaquete bus:
@Component
public class ConsumidorEventoClienteCreado {
private final ServicioEventoClienteCreado servicio;
@Autowired
public ConsumidorEventoClienteCreado(ServicioEventoClienteCreado servicio) {
this.servicio = servicio;
}
@KafkaListener(topics = EventoClienteCreado.TOPIC, groupId = "bdd-spring-boot")
public void procesarEvento(Acknowledgment ack, @Payload EventoClienteCreado evento) {
servicio.registrar(evento);
ack.acknowledge();
}
}4.6.5. Pasos finales
Aparte de esto, es necesario configurar algunos parámetros de Kafka en un fichero application.properties y definir los deserializadores de eventos.
El test ahora debería pasar, hemos terminado.
5. Conclusiones
5.1. Beneficios
¿Qué hemos conseguido con este enfoque?
Por un lado, tenemos tests de comportamiento funcional escritos en nuestro lenguaje de programación, que son rápidos de escribir y ejecutar.
Por otro lado, estos tests son independientes de la implementación porque sólo validan a nivel de interfaz externa.
El código resultante es mucho más mantenible y facilita futuras refactorizaciones que evolucionen la implementación sin cambiar el comportamiento visible.
También hemos conseguido verificar funcionalmente todo un microservicio con unos pocos tests.
Otro detalle interesante es que el test de integración que ejercita el adaptador REST es en realidad una manera sencilla de hacer contract testing.
Podríamos cambiarlo por otra herramienta más potente que haga formalmente “consumer-driven contract testing” como manera de validar esa capa REST.
5.2. Alternativas
Aparte de BDD, las otras principales técnicas de desarrollo guiado por pruebas son TDD y ATDD.
Vamos a comparar las tres desde varios puntos de vista para ver dónde queda BDD.
5.2.1. Cercanía a negocio
Aunque no debería, en la práctica TDD acaba estando muy centrado en la implementación (el cómo) en vez del comportamiento (el qué).
Por otro lado, ATDD permite a negocio junto con el resto del equipo definir los criterios de aceptación de una historia de usuario con un lenguaje natural estructurado.
BDD se queda en medio, porque usando el lenguaje de desarrollo nos permite definir una validación funcional.
Ojo, esto lo hace el desarrollador en base a los criterios de aceptación informales de la historia de usuario, así que existe el riesgo potencial de que los interprete mal.
5.2.2. Complejidad
En TDD solemos acabar un poco enfangados con los mocks de las dependencias de nuestro componente.
En ATDD, traducir los criterios de aceptación en código de verificación es tedioso y bastante complejo.
BDD en este caso simplifica las cosas, porque usando las mismas técnicas y librerías que TDD, trabaja a un nivel más alto y necesita menos código de configuración y preparación del test.
5.2.3. Velocidad de ejecución
Los test unitarios de TDD son pequeños y no requieren otros componentes a su alrededor, así que son los más rápidos.
El extremo opuesto es ATDD, que requiere levantar la aplicación completa y a veces incluso dependencias externas como la base de datos.
BDD está otra vez en medio porque en la práctica nos va a obligar a levantar el contenedor de Spring, aunque con mocks de los adaptadores.
5.2.4. Mantenibilidad
Aquí es donde BDD se sale por las razones expuestas en el apartado 5.1. Beneficios.
TDD en la práctica entorpece los refactorings porque los tests por desgracia suelen atarse demasiado a la implementación.
En ATDD la fragilidad se desplaza al otro extremo: pequeños cambios en los criterios de aceptación suelen tener un gran impacto en la implementación de los tests.
5.2.5. Especificación
Se dice que la documentación de referencia más fiel a la realidad es los propios tests.
En ese sentido, ATDD es una especificación de muy alta calidad, con un lenguaje entendible por todos pero con suficiente formalidad para evitar malentendidos.
En TDD, los tests unitarios documentan cómo funcionan los componentes, pero es código fuente y suele definir comportamientos de muy bajo nivel.
BDD es un término medio.
Tenemos código fuente que especifica el comportamiento externo de nuestro sistema.
En teoría, esto debería ser una traducción cercana de los criterios de aceptación aunque en la práctica sigue siendo código por y para los desarrolladores.
5.3. Punto final
¿Merece la pena? Pues como pasa con todo, a veces sí a veces no, según el caso.
Lo importante es conocer los pros y los contras con respecto a otras alternativas.
Y a ti, ¿qué te parece? Por favor comparte tu opinión y experiencias similares en los comentarios.
6. Referencias
- Kent Beck, “Test Driven Development: by example”, Addison-Wesley Professional, 2002
- Ian Cooper, “TDD, where did it all go wrong”: https://www.youtube.com/watch?v=EZ05e7EMOLM
- CodeUtopia, “What’s the difference between Unit Testing, TDD and BDD”: https://codeutopia.net/blog/2015/03/01/unit-testing-tdd-and-bdd/


Hola David,
Buen aporte, con respecto a las pruebas de integracion si es correcto realizar mock en dichas pruebas? Tengo entendido que estas pruebas deben ser lo mas reales con el negocio. Y por ende no usar tanta validacion con mock.
Hola Jose,
Tu test de integración puede (y de hecho *debe*) centrarse en un aspecto de la integración de la aplicación con la infraestructura del entorno.
Obviamente esa parte debe ser lo más real posible, por eso en el test de la base de datos digo que aunque haya usado H2, en un proyecto real se debería usar el mismo SGBD que en producción. Hoy día con Docker e iniciativas como https://www.testcontainers.org/ no hay excusas.
El resto de dependencias sí se pueden inyectar como mocks, no son el objetivo del test así que cuantas menos interferencias mejor.
Otra cosa son los tests E2E o End-to-end, ahí sí que no se deben usar mocks. De hecho, lo suyo sería levantar la aplicación completa, a ser posible el mismo binario (imagen de Docker por ejemplo) que luego irá a producción.
Esto mismo es aplicable a los tests de aceptación, que deben ver la aplicación como una caja negra.