
Índice de contenidos
1. Introducción
En este tutorial vamos a explicar el stack tecnológico ofrecido por InfluxData que sirve para procesar,
analizar y almacenar datos de series temporales.
Ofrece las principales piezas del stack como Open Source y un servicio administrado en la nube de pago.
InfluxData es una plataforma completa para el tratamiento de grandes cantidades de datos temporales desde su recolección hasta su análisis final.
Puede ser así una alternativa muy útil y completa para trabajar en escenarios de BigData de series temporales consiguiendo una gran optimización en su almacenamiento y su acceso.
2. Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 15′ (2,2 GHz Intel Core i7, 16GB DDR3).
- Sistema Operativo: Mac OS High Sierra
- Entorno de desarrollo: Visual Studio Code
- Software: InfluxData stack con Telegraf (1.7), InfluxDB (1.5), Chronograph (1.5), y Kapacitor (1.5)
3. Piezas
El stack de InfluxData está divido en 4 piezas principales: Telegraf, InfluxDB, Chronograf y Kapacitor.
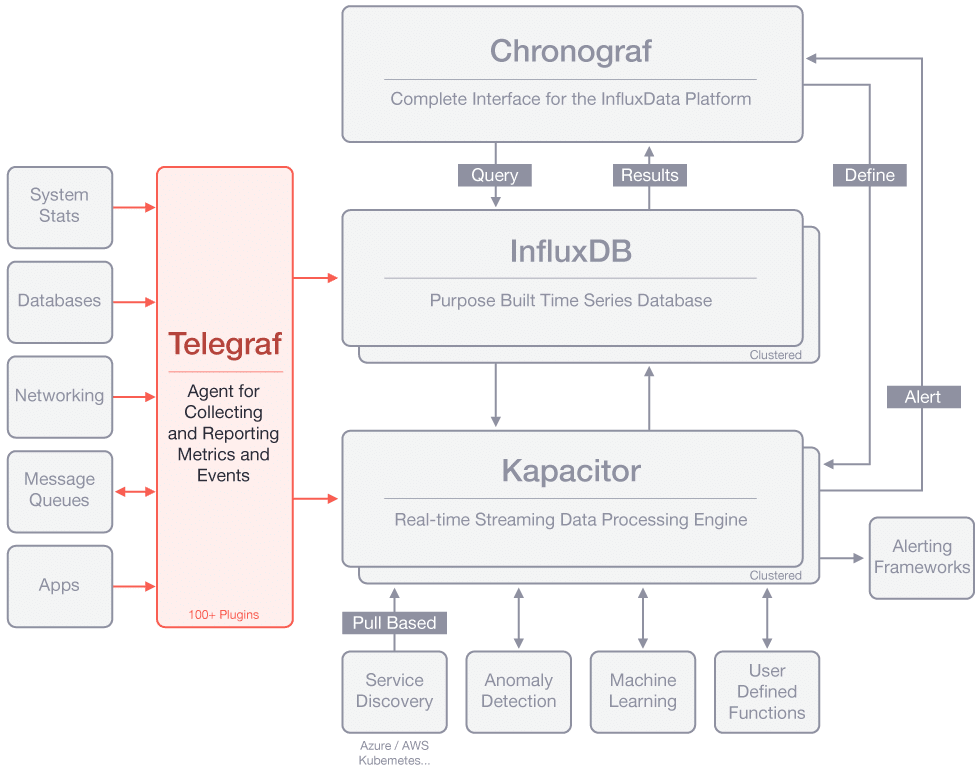
Telegraf
Telegraf es un agente que se encarga de recopilar y reportar métricas y/o eventos desde cualquiera de las fuentes posibles.
Cuenta con más de 100 plugins o integraciones para diferentes origenes de datos.
Permite fácilmente añadir nuevos orígenes de datos ya sean con los plugins existentes para orígenes de datos muy conocidos, o hechos a medida.
Puedes ver la documentación oficial en https://docs.influxdata.com/telegraf/
InfluxDB
InfluxDB es la base de datos encargada de la persistencia, indexación y búsqueda de datos;
está especializada en tratamiento de datos de series temporales.
Puede manejar gran cantidad de inserciones y búsquedas.
También está pensada para tratar datos de métricas, monitoreo, sensores IoT, y análisis en tiempo real.
Ofrece un API http y otros protocolos para consumir sus datos como Graphite, collectd, y OpenTSDB.
Permite la configuración de políticas de retención (RP) de datos para expirar automáticamente datos antiguos o modificar el número de réplicas.
También se pueden lanzar queries continuas (CQ) para reducir la resolución de los datos,
cambiando por ejemplo el cálculo de la media de un valor con una resolución cada 10 minutos a una resolución cada 30 minutos para datos de hace más de un mes.
Puedes ver la documentación oficial en https://docs.influxdata.com/influxdb/
Chronograf
Chronograf es la parte del stack de InfluxData para visualizar y monitorizar datos fácilmente.
Permite ver y controlar el estado de todos los servidores del clúster.
Ofrece una interfaz gráfica para configurar alertas, ejecutar «jobs» y detectar anomalías en los datos utilizando las funcionalidades de Kapacitor.
Permite crear dashboards personalizados para visualización de datos con distintos tipos de gráficos.
Permite administrar la base de datos y las políticas de retención, ver las queries en curso y cancelarlas, y administrar usuarios.
Puedes ver la documentación oficial en https://docs.influxdata.com/chronograf/
Kapacitor
Kapacitor es la pieza que facilita la configuración de alertas, ejecución de «jobs» y detección de anomalías en los datos.
Permite tratar datos en «streaming» o en «batch».
Permite ejecutar transformaciones de datos y guardarlos en InfluxDB.
Permite configurar funciones personalizadas para detección de anomalías en los datos.
Se integra con sistemas de alertas y chats como: HipChat, OpsGenie, Alerta, Sensu, PagerDuty, Slack, etc.
Puedes ver la documentación oficial en https://docs.influxdata.com/kapacitor/
4. Instalación
Esto se puede instalar libremente pero hay ciertas funcionalidades que no están incluidas en la versión Open Source.
Una gran desventaja de esta solución es que la versión que permite alta disponibilidad en la base de datos no es Open Source.
Ofrecen todo el stack como SaaS con el nombre «InfluxCloud».
Puedes consultar los precios en https://cloud.influxdata.com/plan-picker
Si quieres instalar la versión completa por tu cuenta tienes que contratar «InfluxEnterprise».
Más información en https://www.influxdata.com/influxenterprise/
Descargando y arrancando
Vamos a instalar sobre dockers la versión Open Source.
Clonaros el repositorio git https://github.com/influxdata/TICK-docker
Acceder a la última versión disponible (actualmente la 1.3).
Arrancar los dockers definidos en el fichero docker-compose.yml
> git clone https://github.com/influxdata/TICK-docker > cd TICK-docker/1.3 > docker-compose up
Telegraf
Se ha lanzado telegraf con una configuración establecida en el fichero «etc/telegraf.conf» que explicaremos en el próximo apartado. En estos momentos ya se encuentra recopilando datos básicos sobre uso de cpu, ram, etc.
InfluxDB
Docker también ha levantado el servidor de InfluxDB en el puerto 8086.
Puedes verificarlo comprobando que http://localhost:8086/ping te devuelve un 20x.
Puedes arrancar un cliente de InfluxDB que hay como docker para ejecutar comandos con:
> docker-compose run influxdb-cli
Y ejecutar algunos comandos básicos como los siguientes:
> show databases > show stats
Chronograf
Tambien tendrás desplegado chronograf en el puerto 8888.
Puedes verlo accediendo a: http://localhost:8888/
Kapacitor
Por último dispondrás también de Kapacitor en el puerto 9092.
Puedes verificarlo comprobando que http://localhost:9092/kapacitor/v1/ping te devuelve un 20x.
Puedes arrancar un cliente de kapacitor que hay como docker para ejecutar comandos con:
> docker-compose run kapacitor-cli
Y ejecutar algunos comandos básicos como los siguientes:
> kapacitor list tasks > kapacitor list recordings > kapacitor list topics > kapacitor list topic-handlers
5. Ejemplo
Telegraf
En el fichero /etc/telegraf.conf podréis ver que está configurado como destino influxdb «[[outputs.influxdb]]» con sus datos de conexión. Entre estos datos está seleccionada la base de datos «telegraf».
Se han configurado también distintos inputs como: [[inputs.cpu]], [[inputs.disk]], [[inputs.mem]], …
# Telegraf configuration # Telegraf is entirely plugin driven. All metrics are gathered from the # declared inputs, and sent to the declared outputs. # Plugins must be declared in here to be active. # To deactivate a plugin, comment out the name and any variables. # Use 'telegraf -config telegraf.conf -test' to see what metrics a config # file would generate. # Global tags can be specified here in key="value" format. [global_tags] # dc = "us-east-1" # will tag all metrics with dc=us-east-1 # rack = "1a" # Configuration for telegraf agent [agent] ## Default data collection interval for all inputs interval = "10s" ## Rounds collection interval to 'interval' ## ie, if interval="10s" then always collect on :00, :10, :20, etc. round_interval = true ## Telegraf will cache metric_buffer_limit metrics for each output, and will ## flush this buffer on a successful write. metric_buffer_limit = 10000 ## Flush the buffer whenever full, regardless of flush_interval. flush_buffer_when_full = true ## Collection jitter is used to jitter the collection by a random amount. ## Each plugin will sleep for a random time within jitter before collecting. ## This can be used to avoid many plugins querying things like sysfs at the ## same time, which can have a measurable effect on the system. collection_jitter = "0s" ## Default flushing interval for all outputs. You shouldn't set this below ## interval. Maximum flush_interval will be flush_interval + flush_jitter flush_interval = "10s" ## Jitter the flush interval by a random amount. This is primarily to avoid ## large write spikes for users running a large number of telegraf instances. ## ie, a jitter of 5s and interval 10s means flushes will happen every 10-15s flush_jitter = "0s" ## Run telegraf in debug mode debug = false ## Run telegraf in quiet mode quiet = false ## Override default hostname, if empty use os.Hostname() hostname = "" ############################################################################### # OUTPUTS # ############################################################################### # Configuration for influxdb server to send metrics to [[outputs.influxdb]] # The full HTTP or UDP endpoint URL for your InfluxDB instance. # Multiple urls can be specified but it is assumed that they are part of the same # cluster, this means that only ONE of the urls will be written to each interval. # urls = ["udp://localhost:8089"] # UDP endpoint example urls = ["http://influxdb:8086"] # required # The target database for metrics (telegraf will create it if not exists) database = "telegraf" # required # Precision of writes, valid values are "ns", "us" (or "µs"), "ms", "s", "m", "h". # note: using second precision greatly helps InfluxDB compression precision = "s" ## Write timeout (for the InfluxDB client), formatted as a string. ## If not provided, will default to 5s. 0s means no timeout (not recommended). timeout = "5s" # username = "telegraf" # password = "metricsmetricsmetricsmetrics" # Set the user agent for HTTP POSTs (can be useful for log differentiation) # user_agent = "telegraf" # Set UDP payload size, defaults to InfluxDB UDP Client default (512 bytes) # udp_payload = 512 ############################################################################### # INPUTS # ############################################################################### # Read metrics about cpu usage [[inputs.cpu]] # Whether to report per-cpu stats or not percpu = true # Whether to report total system cpu stats or not totalcpu = true # Comment this line if you want the raw CPU time metrics fielddrop = ["time_*"] # Read metrics about disk usage by mount point [[inputs.disk]] # By default, telegraf gather stats for all mountpoints. # Setting mountpoints will restrict the stats to the specified mountpoints. # mount_points=["/"] # Ignore some mountpoints by filesystem type. For example (dev)tmpfs (usually # present on /run, /var/run, /dev/shm or /dev). ignore_fs = ["tmpfs", "devtmpfs"] # Read metrics about disk IO by device [[inputs.diskio]] # By default, telegraf will gather stats for all devices including # disk partitions. # Setting devices will restrict the stats to the specified devices. # devices = ["sda", "sdb"] # Uncomment the following line if you do not need disk serial numbers. # skip_serial_number = true # Read metrics about memory usage [[inputs.mem]] # no configuration # Read metrics about swap memory usage [[inputs.swap]] # no configuration # Read metrics about system load & uptime [[inputs.system]] # no configuration ############################################################################### # SERVICE INPUTS # ###############################################################################
InfluxDB
Ejecuta desde la consola de influxdb-cli unas consultas sobre la base de datos de «telegraf»:
> show databases # verás que existe una llamada Telegraf > use telegraf # seleccionamos la base de datos Telegraf para las siguientes sentencias > SHOW MEASUREMENTS # mostramos las mediciones existentes name: measurements name ---- cpu disk diskio mem swap system > SHOW FIELD KEYS # mostramos los distintos fields para cada tipo de medición name: cpu fieldKey fieldType -------- --------- usage_guest float usage_guest_nice float usage_idle float usage_iowait float usage_irq float usage_nice float usage_softirq float usage_steal float usage_system float usage_user float name: disk fieldKey fieldType -------- --------- free integer inodes_free integer inodes_total integer inodes_used integer total integer used integer used_percent float name: diskio fieldKey fieldType -------- --------- io_time integer iops_in_progress integer read_bytes integer read_time integer reads integer weighted_io_time integer write_bytes integer write_time integer writes integer name: mem fieldKey fieldType -------- --------- active integer available integer available_percent float buffered integer cached integer free integer inactive integer total integer used integer used_percent float name: swap fieldKey fieldType -------- --------- free integer in integer out integer total integer used integer used_percent float name: system fieldKey fieldType -------- --------- load1 float load15 float load5 float n_cpus integer n_users integer uptime integer uptime_format string > SELECT usage_idle FROM cpu WHERE cpu = 'cpu-total' LIMIT 5 # consultamos datos sobre uso de cpu name: cpu time usage_idle ---- ---------- 1529153390000000000 99.87437185932569 1529153400000000000 95.53001277139474 1529153410000000000 99.26952141063127 1529153420000000000 99.6485943774752 1529153430000000000 99.67369477910451
Chronograf
Acede a la url de Chronograf y prueba a lanzar queries básicas sobre el uso de cpu o el nivel de ram desde «Data Explorer».
Puedes configurar tu primer dashboard y añadirle un par de gráficos para ver cómo funciona y las facilidades que te da para explotar y visualizar fácilmente los datos de InfluxDB.
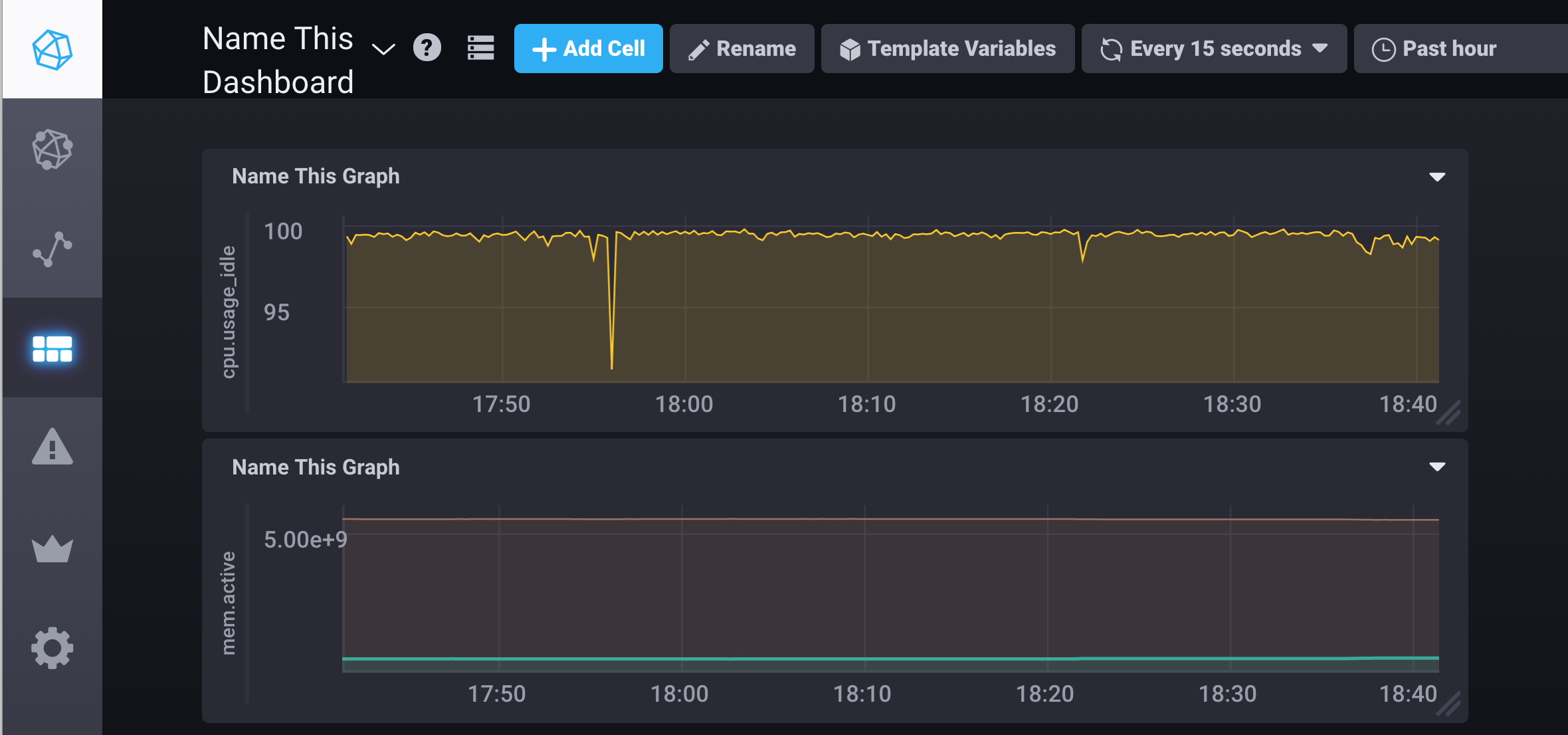
Puedes incluso configurar fácilmente alertas para Kapacitor creando una nueva regla en el apartado «Alerting», configurando simplemente el field de una serie temporal y una condición de lanzamiento. Del mismo modo puedes configurar el mensaje y suceso que lanza esa alerta que puede ser una simple escritura en un log, un webhook, etc.
6. Conclusiones
Hemos visto que InfluxDB ofrece una plataforma muy completa
para el tratamiento óptimo de datos de series temporales permitiéndonos fácilmente entre otras cosas:
su procesamiento y recepción,
su posterior almacenamiento,
configurar políticas para que este almacenamiento sea óptimo y escalable en el tiempo,
configurar dashboards y gráficas para poder visualizar estos datos,
y configurar alertas para detectar anomalías en los datos.

