

Índice de contenidos
- 1. Introducción a ToroDB Stampede
- 2. Requisitos previos
- 3. Instalación
- 4. Configuración de PostgreSQL
- 5. Replicación con ToroDB Stampede
- 6. La estructura relacional
1. Introducción a ToroDB Stampede
ToroDB Stampede es una tecnología que permite la replicación de documentos NoSQL de MongoDB en una estructura relacional de PostgreSQL, de forma totalmente transparente al usuario. Para lograrlo lo que hace es monitorizar un replica set de MongoDB y hacer uso del Oplog.

A diferencia de otras soluciones en el mercado, la estructura relacional resultante no es un documento de tipo JSON almacenado en PostgreSQL. Se trata de una descomposición en tablas del documento original, resultando en una estructura que es realmente relacional.
2. Requisitos previos
Para hacer uso de ToroDB Stampede hay una serie de requisitos previos que deben estar correctamente instalados y configurados:
-
Oracle Java 8
-
MongoDB 3.2
-
PostgreSQL
Los pasos descritos a continuación están basados en el uso de Ubuntu 16.04 aunque se puede hacer uso de otros sistemas operativos. Para poder completar el tutorial sin mayores problemas, se recomienda utilizar la siguiente receta de Vagrant, que permite tener un entorno inicial de forma automática.
3. Instalación
Antes de poder utilizar Stampede, es necesario configurar MongoDB y PostgreSQL de forma adecuada.
Configuración de MongoDB como replica set
Para configurar una instancia de MongoDB como un nodo primario del replica set, debemos modificar el fichero /etc/mongod.conf añadiendo las siguientes líneas.
replication:
replSetName: "rs1"En algunas ocasiones se producen problemas si el fichero /etc/hosts no contiene una entrada con el nombre de nuestra máquina. Si se está usando la receta Vagrant provista en el tutorial, hay que añadir la línea indicada a continuación.
127.0.0.1 ubuntu-xenial.localdomain ubuntu-xenialHecho esto, reiniciamos el servicio.
$ sudo service mongod restartAhora podemos acceder haciendo uso de la consola y completar la configuración del replica set.
$ mongo
> rs.initiate()Para comprobar que la configuración del replica set es correcta podemos ejecutar el comando rs.conf().
4. Configuración de PostgreSQL
ToroDB Stampede espera que exista el usuario torodb y la base de datos torod propiedad de dicho usuario, por lo que tenemos que realizar los pasos necesarios para crearlos.
$ sudo -u postgres createuser -S -R -D -P --interactive torodb
$ sudo -u postgres createdb -O torodb torod
$ sudo adduser torodbPara comprobar que todo funciona correctamente podemos conectarnos usando el siguiente comando.
$ sudo -u torodb psql torod5. Replicación con ToroDB Stampede
Llegados a este punto hemos completado los requisitos previos y podemos pasar a ejecutar ToroDB Stampede. Antes de continuar debemos crear el fichero .toropass en nuestra home con los datos de acceso a la base de datos PostgreSQL.
localhost:5432:torod:torodb:torodbAhora ya se puede descargar ToroDB Stampede y ejecutarlo con la configuración por defecto.
$ wget "https://www.torodb.com/stampede/downloads/torodb-stampede-1.0-beta.tar.bz2" -O torodb-stampede-1.0-beta.tar.bz2
$ tar xjf torodb-stampede-1.0-beta.tar.bz2
$ torodb-stampede-1.0-beta/bin/torodb-stampede > toro.log &Para completar el tutorial importaremos un dataset en MongoDB y veremos como este es replicado en PostgreSQL.
$ wget "https://www.torodb.com/stampede/downloads/datasets/primer-dataset.json" -O primer-dataset.json
$ mongoimport -d stampede -c primer primer-dataset.jsonLa importación en MongoDB se realizará en la base de datos stampede y la colección primer, lo que implica que en PostgreSQL la replicación estará localizada en la base de datos torod, esquema stampede y una serie de tablas que comenzarán por el prefijo primer.
6. La estructura relacional
Durante la realización de la replicación, Stampede creará (y actualizará) una serie de tablas en función de la estructura de los documentos de entrada. En este caso la estructura de los documentos coincide con la siguiente.
{
"address": {
"building": "1007",
"coord": [ -73.856077, 40.848447 ],
"street": "Morris Park Ave",
"zipcode": "10462"
},
"borough": "Bronx",
"cuisine": "Bakery",
"grades": [
{ "date": { "$date": 1393804800000 }, "grade": "A", "score": 2 },
{ "date": { "$date": 1378857600000 }, "grade": "A", "score": 6 },
{ "date": { "$date": 1358985600000 }, "grade": "A", "score": 10 },
{ "date": { "$date": 1322006400000 }, "grade": "A", "score": 9 },
{ "date": { "$date": 1299715200000 }, "grade": "B", "score": 14 }
],
"name": "Morris Park Bake Shop",
"restaurant_id": "30075445"
}Por lo tanto se deberían crear cuatro tablas en la réplica relacional. Para comprobarlo podemos acceder a la base de datos mediante el cliente psql e inspeccionar la estructura de tablas creadas.
$ sudo -u torodb psql torod
torod=# set schema 'stampede'
torod=# \d
List of relations
┌──────────┬──────────────────────┬───────┬────────┐
│ Schema │ Name │ Type │ Owner │
├──────────┼──────────────────────┼───────┼────────┤
│ stampede │ primer │ table │ torodb │
│ stampede │ primer_address │ table │ torodb │
│ stampede │ primer_address_coord │ table │ torodb │
│ stampede │ primer_grades │ table │ torodb │
└──────────┴──────────────────────┴───────┴────────┘A su vez, cada una de esas tablas tendrá una distribución de columna equivalente a los campos que contienen cada nivel del documento original. En el siguiente diagrama se puede observar la estructura creada de forma más clara.
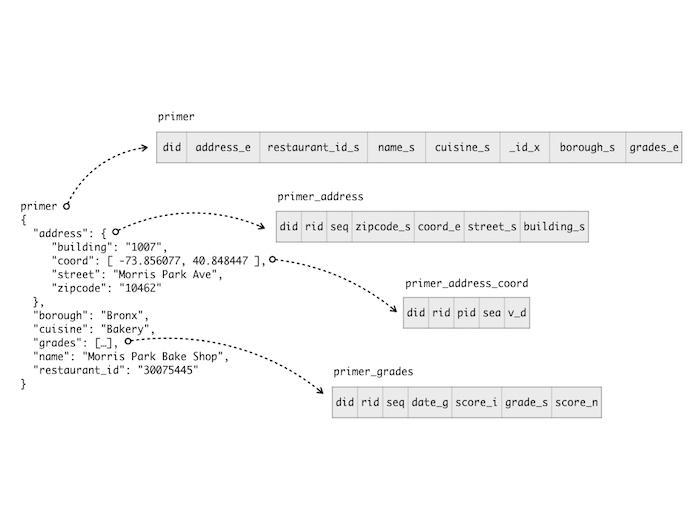
La estructura de tablas no sólo contiene los campos que componen los documentos originales, también poseen columnas de metadatos que permiten gestionar la estructura relacional. Con estos metadatos no sólo se permite la capacidad de hacer queries sino que también se permite el proceso de recomposición del documento original, lo cual permitiría a ToroDB funcionar como un sistema MongoDB.
[custom_table style=»2″]
| Columna | ¿Qué hace? |
|---|---|
| did | Es el identificador único de documento, posee el mismo valor para todas las filas que forman parte de un mismo documento. |
| rid | Es el identificador único de fila. Por ejemplo, si se mapea un array, es necesario este campo porque el did es siempre el mismo y se necesita otro valor para formar una clave única. |
| pid | Es la referencia a rid del padre. Por ejemplo, primer_address_coord posee filas con rid 0 y 1 y pid 0, eso significa que esas filas son hijas de la fila con rid 0 en la tabla primer_address. |
| seq | Representa la posición de un elemento dentro del array original. |
[/custom_table]
Una vez que los datos están en una estructura relacional en PostgreSQL, se puede realizar analítica avanzada de los mismos de una forma más eficiente y sencilla que en su equivalente MongoDB.


Gracias por compartir con todos nosotros su trabajo.