
En este tutorial vamos a dar unas pautas básicas para optimizar consultas pesadas, basándonos en el gestor de bases de datos MySQL.
Índice de contenidos
- 1. Introducción
- 2. Entorno
- 3. Diagnóstico de la consulta con EXPLAIN
- 4. Optimizaciones
- 5. Conclusiones
- 6. Referencias
1. Introducción
Es bastante común que en nuestras aplicaciones haya alguna sección de informes, históricos, búsquedas generales… en la que se acaben consultando una gran cantidad de registros provenientes de varias tablas a la vez. Si estas tablas son grandes (varias centenas de miles de registros, o incluso millones), la optimización de las consultas pesadas supondrá la diferencia entre tener una aplicación fluida o tener una aplicación inmanejable.
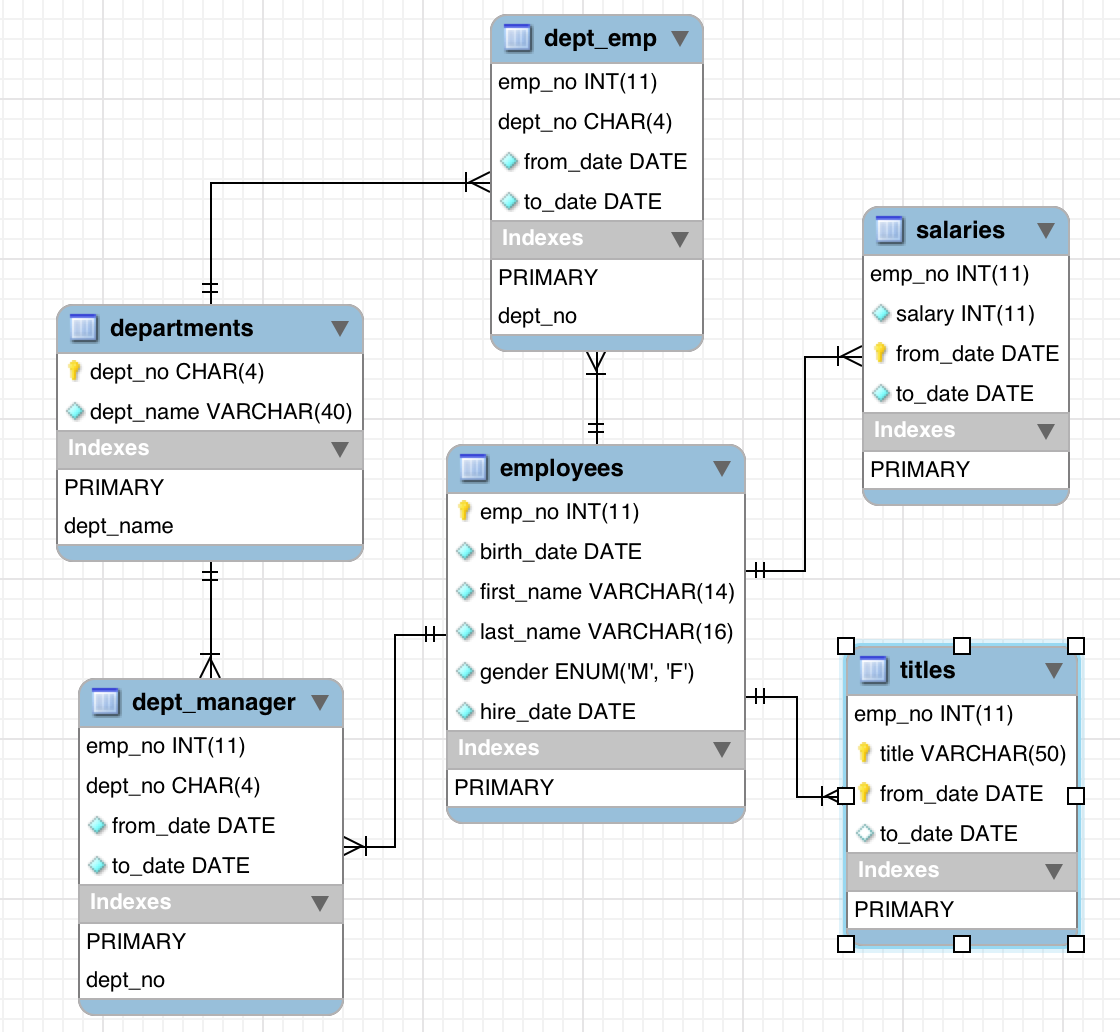
Para los ejemplos de este tutorial hemos empleado una base de datos de testing, que podéis obtener aquí. Se trata de una base de datos con unos 300.000 registros de empleados y alrededor de 2,8 millones de registros de salarios. La estructura de las tablas es la siguiente:
2. Entorno
El tutorial se ha realizado usando el siguiente entorno:
- Hardware: Portátil MacBook Pro Retina 15′ (2,3 GHz Intel Core i7, 16GB DDR3).
- Sistema Operativo: Mac OS El Capitán 10.11.16
- Base de datos: MySQL 5.6.24
- Cliente de MySQL: MySQL Workbench 6.3
3. Diagnóstico de la consulta
Antes de empezar a cambiar nada, lo primero que recomendamos es ejecutar el comando EXPLAIN sobre esa consulta. De esta manera podemos saber qué pasos sigue el gestor de la base de datos para realizarla, y de qué manera accede a las tablas en cada uno de ellos. Con esto podremos identificar posibles cuellos de botella. Si no estáis familiarizados con este comando podéis echar un vistazo a este tutorial de introducción.
Del resultado de este comando, en lo que más nos vamos a fijar en este tutorial es:
- El orden de las filas: es el orden en que la base de datos consulta las tablas.
- La columna Key: indica el índice que se está empleando para acceder a esa tabla concreta (si lo hubiera)
- La columna type: indica el tipo de acceso a la tabla. Los posibles valores, de mejor a peor, son:
- system
- const
- eq_ref
- ref
- fulltext
- ref_or_null
- index_merge
- unique_subquery
- index_subquery
- range
- index
- ALL
Si algún acceso de la consulta es del tipo
indexoALL, deberíamos revisar esa parte de la consulta, a menos que queramos expresamente listar o calcular todos los registros de la tabla.
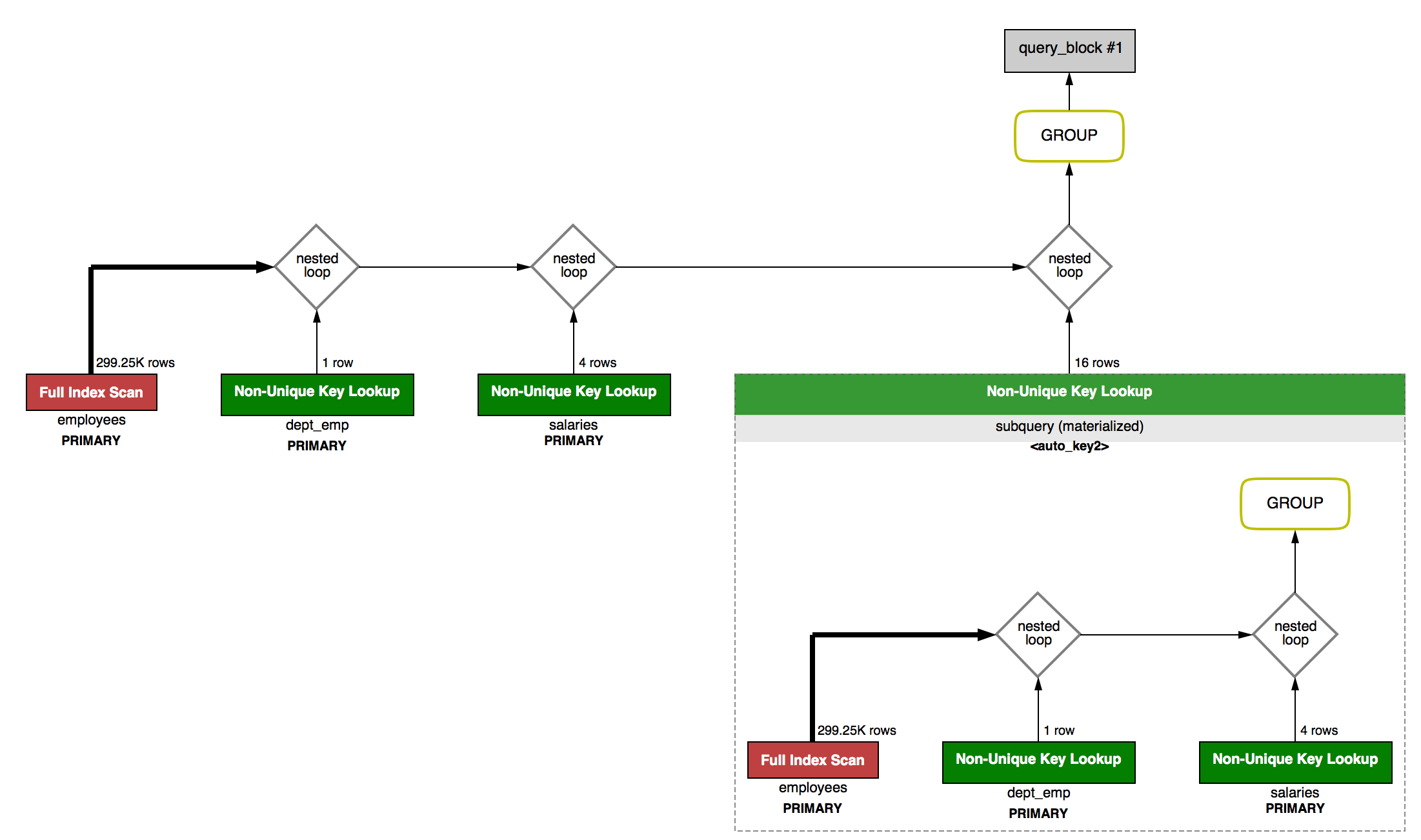
El resultado de la sentencia EXPLAIN puede mostrarse como una tabla (formato tradicional) o como un JSON. La herramienta MySQL Workbench usa este formato JSON para mostrar un diagrama visual del plan (opción visual explain en la sección de resultados del plan), que nos resulta muy útil para detectar los cuellos de botella, ya que los marca en rojo.
4. Optimizaciones
4.1. Evitar FULL SCANS
Si al ejecutar la sentencia EXPLAIN, comprobamos que el tipo de acceso a alguna de las tablas es de ALL, entonces se trata de un FULL TABLE SCAN, quiere decir que se están leyendo todos los registros de dicha tabla. Deberíamos ver si se puede reescribir la consulta para que se acceda por un índice de la tabla, o valorar la posibilidad de crear un índice para las columnas por las que se está buscando. Esto dependerá de lo frecuente o importante que sea esta consulta en nuestra aplicación.
Si el tipo de acceso es INDEX no es mucho mejor, pues nos indica que se están leyendo todos los accesos de un índice. Se le llama FULL INDEX SCAN y no llega a ser tan grave como un FULL TABLE SCAN, porque se suele hacer en memoria y lee menos información por registro, pero igualmente estamos pasando por todos los nodos. Este tipo de acceso se emplea cuando todas las columnas que queremos obtener forman parte del mismo índice, y por tanto, el optimizador de la base de datos entiende que no necesita ir a las tablas para obtener la información, ya que puede sacarla exclusivamente del índice.
4.2. Uso CORRECTO de los índices
¡Pero… si estoy usando un «índice»!
Hay que ver los índices como diccionarios, donde el propio índice es la palabra y el registro entero de la tabla es la definición. Si queremos buscar la definición de “escuela” y tanteamos por palabras que comiencen por “esc”, no iremos mal encaminados, mientras que si queremos encontrarla buscando palabras que terminen por “la” no nos quedará más remedio que empezar por la primera página e ir pasando por todas hasta que demos con nuestra palabra. Esto explica que una búsqueda LIKE ‘prefijo_índice%’ es indexada y otra LIKE ‘%sufijo_índice’ no lo es.
Esto que parece una tontería cobra especial importancia en el caso de los índices compuestos (formados por varias columnas), donde el orden de las columnas que los forman es totalmente determinante. Con este tipo de índices prefiero usar el ejemplo de la guía telefónica: no seremos muy eficientes buscando el teléfono de alguien de quien sólo conocemos su segundo apellido.
Para tener una primera idea del concepto de índice podéis leer este tutorial.
4.3. Sentencias OR
El optimizador de MySQL no puede usar índices si se está empleando la sentencia OR y alguna de sus restricciones es una columna no indexada. Por ejemplo
SELECT * FROM mi_tabla WHERE mi_indice = 'valor1' OR columna_no_indexada = 'valor2'
Deberíamos tratar de evitar las sentencias OR, siempre que sea posible.
4.4. GROUP / ORDER BY
Por simplicidad vamos a referirnos a la cláusula GROUP BY, pero teniendo en cuenta que todo se aplica también a ORDER BY.
Esta cláusula puede suponer un verdadero cuello de botella cuando el número de registros a agrupar es muy elevado (independientemente de que se use la cláusula LIMIT, pues esta se aplica después del GROUP BY).
Hay que procurar que todas las columnas presentes en el GROUP BY formen parte del mismo índice de la tabla que se está consultando, en el mismo orden que en la consulta. Si la consulta es muy importante en nuestra aplicación, podemos valorar la posibilidad de definir un índice para optimizarla. Elegiríamos primero la columna/s filtrada en el WHERE, y después aquellas presentes en el GROUP BY.
4.5. Tablas derivadas vs Subqueries
Una subconsulta no es más que una sentencia SELECT dentro de otra sentencia. Una tabla derivada es un tipo concreto de subconsulta que se caracteriza porque está dentro del FROM de la consulta “padre”. El tratamiento de ambas es diferente:
- En una subconsulta se ejecuta una búsqueda en la base de datos por cada registro de la consulta “padre”
- En una tabla derivada se realiza una sola consulta a la base de datos, almacenándose los resultados en una tabla temporal en memoria. A esta tabla se accede una vez por cada registro de la consulta padre.
Supongamos que queremos hacer una consulta que nos devuelva, para cada empleado, todas las columnas de su tabla y además el número de empleados que han nacido el mismo día.
Así de primeras, se me ocurren dos maneras de hacerlo:
-
Con una tabla derivada
select e.*, e2.cuenta as mismo_dia from employees as e inner join( select e.birth_date, count(*) as cuenta from employees as e group by e.birth_date ) as e2 on e2.birth_date = e.birth_date

-
Con una subconsulta dentro de la sección SELECT
select e.*, ( select count(e2.birth_date) as cuenta from employees as e2 where e2.birth_date = e.birth_date group by e2.birth_date ) as mismo_dia from employees as e

Los resultados revelan una gran diferencia de eficiencia entre ambas consultas. A primera vista puede parecer que, tratando con tablas de muchos registros, siempre va a ser mejor la solución de la tabla derivada, por aquello de que una consulta va a ser más eficiente que varios cientos de miles de consultas. Bueno, pues esto no siempre es cierto. Pongamos un ejemplo.
Puesto que estamos usando la fecha de nacimiento para hacer las consultas, vamos a crear un índice con ese campo
CREATE INDEX employees_birth ON employees(birth_date);
Y para subir la complejidad vamos a aumentar los requisitos de nuestra consulta: Además de todo lo anterior, también queremos tener una columna con el número de empleados que nacieron el día antes y otra con los que nacieron el día después. Veamos cómo quedarían las dos consultas resultantes y, lo más importante, el tiempo de ejecución de las mismas:
-
La tabla derivada
select e.*, e2.cuenta as mismo_dia, e3.cuenta as dia_antes, e4.cuenta as dia_despues from employees as e inner join( select e.birth_date, count(*) as cuenta from employees as e group by e.birth_date ) as e2 on e2.birth_date = e.birth_date inner join( select e.birth_date, count(*) as cuenta from employees as e group by e.birth_date ) as e3 on e3.birth_date = DATE_SUB(e.birth_date , INTERVAL 1 DAY) inner join( select e.birth_date, count(*) as cuenta from employees as e group by e.birth_date ) as e4 on e4.birth_date = DATE_ADD(e.birth_date , INTERVAL 1 DAY)
-
La subconsulta
select e.*, ( select count(e2.birth_date) as cuenta from employees as e2 where e2.birth_date = e.birth_date group by e2.birth_date ) as mismo_dia, ( select count(e3.birth_date) as cuenta from employees as e3 where e3.birth_date = DATE_SUB(e.birth_date , INTERVAL 1 DAY) group by e3.birth_date ) as dia_antes, ( select count(e4.birth_date) as cuenta from employees as e4 where e4.birth_date = DATE_ADD(e.birth_date , INTERVAL 1 DAY) group by e4.birth_date ) as dia_despues from employees as e
¿Por qué oscuro motivo la consulta que realiza 4 accesos a las tablas de la base de datos (tabla derivada) tarda más que la que realiza varios miles de accesos (subconsulta en el SELECT)?
En el primer caso, con tablas derivadas, las tablas que se crean en memoria como resultado de las subconsultas de los INNER JOIN no están indexadas. Esto hace que, para cada registro de la consulta «padre», deban leerse todas las filas de las tablas derivadas para comprobar cual cumple la condición de igualdad. En una tabla de 300.000 registros supone, en el peor de los casos, 300.000 lecturas en memoria.
En el segundo caso, con subconsultas en el SELECT, para cada registro de la tabla «padre» se realizan 3 accesos indexados a las tablas de las subconsultas. Esto supone, debido a la naturaleza de árbol binario del índice, 18 lecturas en cada una de las 3 subconsultas. En total 54 lecturas contra la base de datos.
Este es otro ejemplo de la importancia de los índices en nuestras consultas.
4.6. INNER JOIN con GROUP / ORDER
Este es un caso digno de mención. En una consulta con varios INNER JOIN es el optimizador quien decide el orden de consulta de las tablas, dependiendo de las restricciones y el uso de los índices. Esta decisión suele ser acertada, con una excepción: puede no ser el orden óptimo para efectuar el GROUP BY (o el ORDER BY).
En este caso necesitamos colocar primero la tabla sobre la que se está haciendo el GROUP BY y forzar al optimizador a que lea primero esa tabla. De esta manera, el GROUP BY se realizará de una sola pasada, debido a que los resultados ya estarán ordenados con respecto al índice. Esto lo conseguimos con STRAIGHT_JOIN, que no es más que un INNER JOIN con la particularidad de que fuerza la lectura de la tabla de la izquierda antes que la de la derecha.
Con los LEFT JOIN no ocurre este problema, pues en este caso la tabla de la izquierda SIEMPRE se leerá antes que su tabla dependiente.
4.7. La sentencia EXISTS, esa gran olvidada
Supongamos que tenemos dos tablas: BIG y HUGE. La tabla BIG tiene miles de registros, y la tabla HUGE tiene miles de millones de registros. La relación entre ambas es tal que para cada registro de BIG puede haber de cero a varios millones de registros en HUGE.
Si queremos obtener los registros de BIG para los cuales se cumplen ciertas condiciones en HUGE, puede que nuestra primera aproximación sea realizar un INNER JOIN de esta forma:
SELECT BIG.*
FROM BIG INNER JOIN HUGE ON HUGE.fk_big = BIG.id_big
WHERE HUGE.campo_huge_1 = 'valor1'
GROUP BY BIG.id_big
Esta consulta tardará más de la cuenta, pese a estar ordenada «de serie» por el id de BIG, debido a que se tienen que recorrer todos los registros resultantes para agruparlos. Esto puede suponer recorrer varios cientos de millones de registros, para mostrar unas miles de agrupaciones. A primera vista parece que estamos realizando muchas lecturas innecesarias.
Una manera mejor de realizar nuestra consulta sería con una subconsulta que emplee la cláusula EXISTS
SELECT BIG.*
FROM BIG
WHERE EXISTS (
SELECT (*) FROM HUGE
WHERE HUGE.fk_big = BIG.id_big
AND HUGE.campo_huge_1 = 'valor1'
)
¿Cual es la principal ventaja? Las consultas con EXISTS suelen ser muy eficientes, ya que mysql interrumpe la consulta cuando encuentra la primera coincidencia. Así evitamos recorrer todos los registros de HUGE que cumplen la condición.
Obviamente, esto sólo es aconsejable cuando estemos accediendo a la tabla HUGE por algún índice.
5. Conclusiones
Como hemos podido ver a lo largo del tutorial, nuestra primera acción ante una consulta pesada deberá ser analizarla con la sentencia EXPLAIN. Después del análisis, intentaremos que todos los accesos (los que se pueda) se realicen a través de índices. Finalmente, si la consulta sigue siendo lenta, intentaremos detectar si el tiempo se nos está yendo en alguna operación innecesaria o mejorable.
Ante todo, no hay mejor estrategia que usar el sentido común.


Muchas gracias , muy informativo
Excelente articulo Eduardo, sin embargo quería aprovechar y sugerirte a vos o alguno de tus colegas si pueden escribir acerca del uso de los stored procedure, en el reflexionar de cuando es bueno hacer uso de estos o cuando es preferible realizar las operaciones desde el lenguaje de programación donde se este desarrollando la aplicación.
Ejemplo, estoy trabajando una aplicación X (con Java y BD Oracle) donde se debe cargar un combo en base a opciones en una tabla de BD, estas opciones es mejor hacer el select desde Java o llamar a un stored procedure en BD
Ejemplo 2, estoy trabajando una aplicación X (con Java y BD Oracle) donde se debe realizar una operación que interviene con diferentes tablas, estas opciones es mejor hacer los select desde Java o llamar a un stored procedure en BD
Saludos,
Esto va a salvar muchas vidas!!
Muy bien explicado, la verdad es que muchos desarrolladores no tienen en cuenta la eficiencia de sus consultas SQL, porque realizan aplicaciones con pocas trafico, volumen de datos y operaciones. Pero cuando estas en aplicaciones importantes, esto te puede hacer variar de tener la CPU relajada o en porcentajes altos de ocupación.
hola buen dia , disculpa, tengo un problema con java ee y netbeans 8.2 con el servidor glassfish 4.1.1, y necesito a ver si me puedes ayudar a corregir ese error porfavor
un aplauso, excelente la explicación, este es un tema muy bueno, ya que cuando se toma experiencia en el rubro, se comienza a mejorar características que en un principio un piensa son automáticas.
Excelente chamo! Creo q me servira de mucho. No sabia lo de las secuencias de ejecucion
MUCHAS GRACIAS EDUARDO, MUY DIDÁCTICO PARA PODER ADENTRARNON EN EL MUNDO DE LAS CONSULTAS. MI PROFESOR ESTA ENCANTADO CON TU TRABAJO.