
En este tutorial realizaremos un benchmarking de todos los ejemplos de la primera parte, descubriendo las ventajas y desventajas que las Lambdas y Streams nos proporcionan.
Índice de contenidos
1. Introducción
Esta es la segunda parte del tutorial sobre Java 8 que he realizado. En esta segunda parte me centraré en comprobar cuales son las ventajas y desventajas de usar Streams y Lambdas, sacando en conclusión cuándo y cómo usar cada una de las herramientas que nos aportan. Para este tutorial he contado con David Gómez para ayudarme a realizar benchmarking lo más fiable posible.
2. Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 17′ (3 Ghz Intel Core 2 Duo, 8GB DDR3).
- Sistema Operativo: Mac OS El Capitán 10.11
- Entorno de desarrollo: IntelliJ Idea 2016.2
- JavaSE build 1.8.0_77-b03
- Apache Maven 3.1.1
3. Microbenchmarking a mano
Las modificaciones que van a aparecer respecto al ejemplo anterior son las siguientes:
1ª setUp() y testWith()
public static final long LOAD_LEVELX2 = 1_000L;
private static CarritoDeLaCompra carritoCompra;
@BeforeClass
public static void setUp() {
CarritoBuilder builder = new CarritoBuilder(LOAD_LEVELX2,1000000L);
builder.add(-1L);
builder.addMultiple(LOAD_LEVELX2,1000000L);
carritoCompra = builder.build();
}
private long testWith(Supplier method) {
System.gc();
System.out.println("Start----------------------");
long start = System.currentTimeMillis();
method.get();
long end = System.currentTimeMillis();
System.out.println("End----------------------");
System.out.println(errors);
return end - start;
}
El método testWith nos permitirá pasar por parámetro el método en forma de Lambda (Proveedor) que queremos realizar para aplicar una serie de acciones antes y después de ejecutar el test, entre ellas la línea System.gc();. Esta se utiliza para ejecutar el Garbage Collector antes del test para evitar que cualquier GC se ejecute en medio de un test y pueda modificar nuestro benchmark.
Para monitorizar el GC y asegurarnos de que no se ejecuta entre las marcas Start – End editamos la Run/Debug configuration y en VM options debemos usar el parámetro -XX:+PrintGC. Además, configuraremos el tamaño inicial del heap para que tenga 4GB con el parámetro -Xms4092m. Para saber más acerca del GC, podéis ver este tutorial de adictos que habla de ello.

El setUp creará el mismo carrito antes de cada test y así probar la misma carga en todos ellos.
2ª Contador
private AtomicLong counter = new AtomicLong();
public long getCounter() {
return counter.get();
}
public void resetCounter() {
counter.set(0L);
}
Este contador nos permitirá saber el número de iteraciones que hacen cada uno de los diferentes tipos de recorrer un stream
Lo siguiente que debemos hacer, es crear unos nuevos test para cada método. El código es el siguiente:
Nuevos test
@Test
public void testAnyMatch() {
System.out.println("anyMatch = "
+ testWith(() -> carritoCompra.detectarErrorAnyMatch()));
}
@Test
public void testAnyMatchParallel() {
System.out.println("anyMatchParallel = "
+ testWith(()-> carritoCompra.detectarErrorAnyMatchParallel()));
}
@Test
public void testFindAny() {
System.out.println("findAny = " +
+ testWith(() -> carritoCompra.detectarErrorFindAny()));
}
@Test
public void testFindAnyParallel() {
System.out.println("findAnyParallel = "
+ testWith(() -> carritoCompra.detectarErrorFindAnyParallel()));
}
@Test
public void testFindFirst() {
System.out.println("findFirst = "
+ testWith(() -> carritoCompra.detectarErrorFindFirst()) );
}
@Test
public void testFindFirstParallel() {
System.out.println("findFirstParallel = "
+ testWith(() -> carritoCompra.detectarErrorFindFirstParallel()));
}
@Test
public void testImperative(){
System.out.println("imperative = "
+ testWith(() -> carritoCompra.detectarError()));
}
3.1. Resultados individuales
Una vez creados, empezamos el primer benchmark. A continuación dejaré varios logs con los resultados que he recibido, empezando por el LOAD_LEVEL que había en cada log.
Nota: LOAD_LEVEL se llama en el código LOAD_LEVELX2 ya que el valor negativo lo incluyo justo en la mitad, por lo que añado un LOAD_LEVEL al principio y otro al final.
LOAD_LEVEL = 2_000L; anyMatch = 3ms anyMatchParallel = 22ms findAny = 25ms findAnyParallel = 7ms findFirst = 8ms findFirstParallel = 3ms imperative = 1ms
LOAD_LEVEL = 20_000L; anyMatch = 6ms anyMatchParallel = 103ms findAny = 7ms findAnyParallel = 8ms findFirst = 5ms findFirstParallel = 17ms imperative = 5ms
LOAD_LEVEL = 200_000L; anyMatch = 24ms anyMatchParallel = 43ms findAny = 21ms findAnyParallel = 22ms findFirst = 10ms findFirstParallel = 21ms imperative = 26ms
LOAD_LEVEL = 2_000_000L; anyMatch = 43ms anyMatchParallel = 72ms findAny = 54ms findAnyParallel = 36ms findFirst = 50ms findFirstParallel = 54ms imperative = 57ms
LOAD_LEVEL = 20_000_000L; anyMatch = 331ms anyMatchParallel = 100ms findAny = 252ms findAnyParallel = 137ms findFirst = 449ms findFirstParallel = 243ms imperative = 375ms
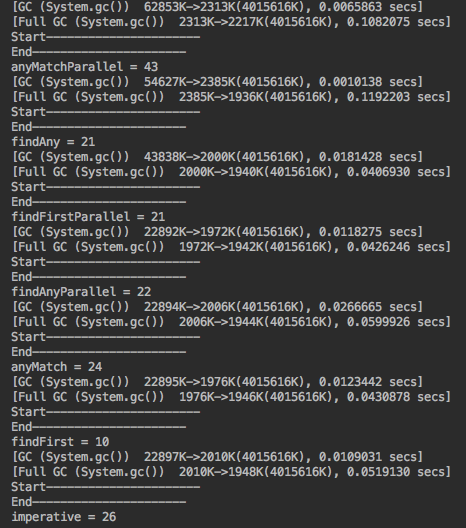
Como podéis observar, entre las marcas Start – End no se ejecuta ningún Garbage Collector, evitando así falsear los tiempos de ejecución.
A continuación realizaré las pruebas con más LOAD_LEVEL con un ordenador más potente para ver los resultados. El hardware utilizado para los siguientes benchmarks es:
- Macbook Pro 15′ Intel core i5 2’4GHz, 8GB DDR3
LOAD_LEVEL = 2_000_000L; anyMatch = 36ms anyMatchParallel = 87ms findAny = 33ms findAnyParallel = 47ms findFirst = 18ms findFirstParallel = 95ms imperative = 27ms
LOAD_LEVEL = 20_000_000L; anyMatch = 70ms anyMatchParallel = 114ms findAny = 69ms findAnyParallel = 105ms findFirst = 121ms findFirstParallel = 116ms imperative = 62ms
LOAD_LEVEL = 200_000_000L; anyMatch = 541ms anyMatchParallel = 379ms findAny = 417ms findAnyParallel = 795ms findFirst = 1139ms findFirstParallel = 591ms imperative = 412ms
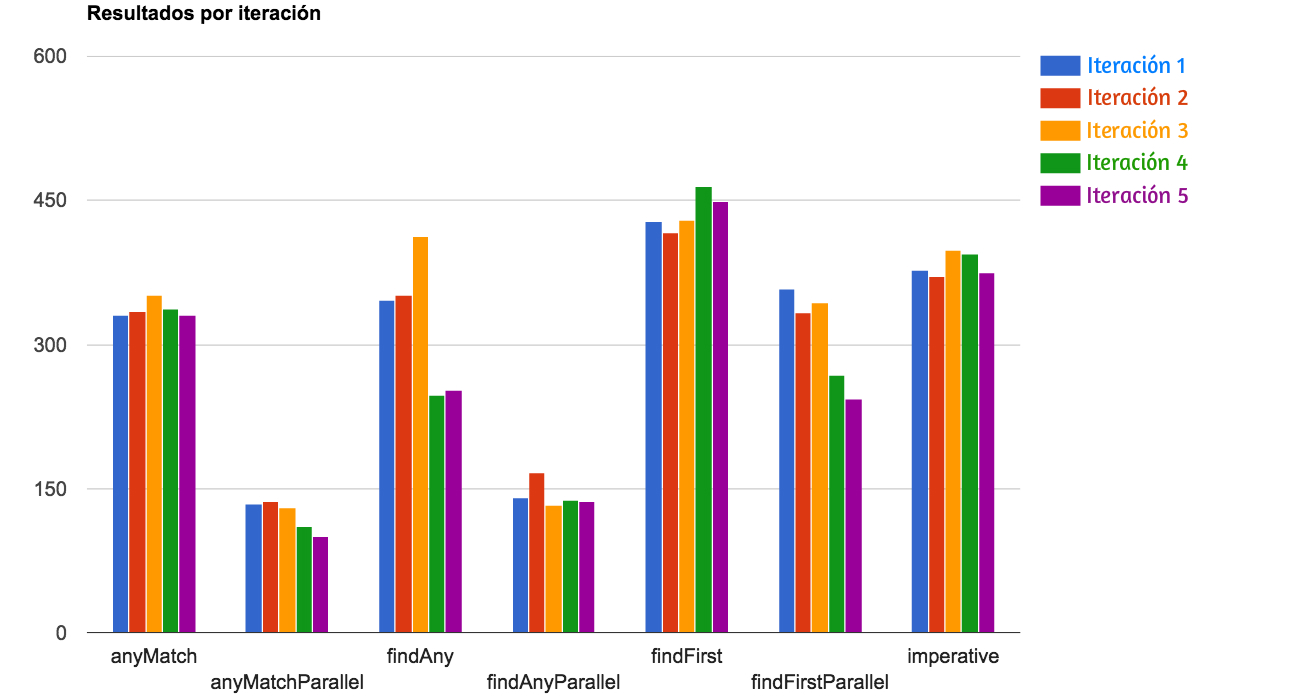
3.2. Resultados por iteración
Las cinco iteraciones mostradas en los gráficos son con LOAD_LEVEL= 2000L y LOAD_LEVEL= 20_000_000L
LOAD_LEVEL= 2000L

LOAD_LEVEL= 20_000_000L
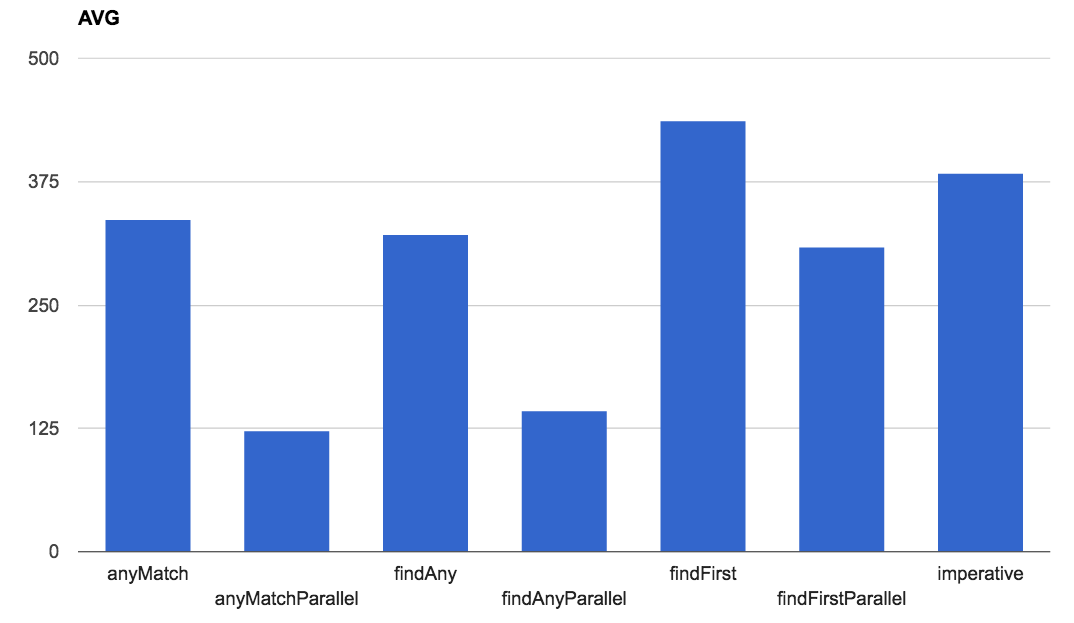
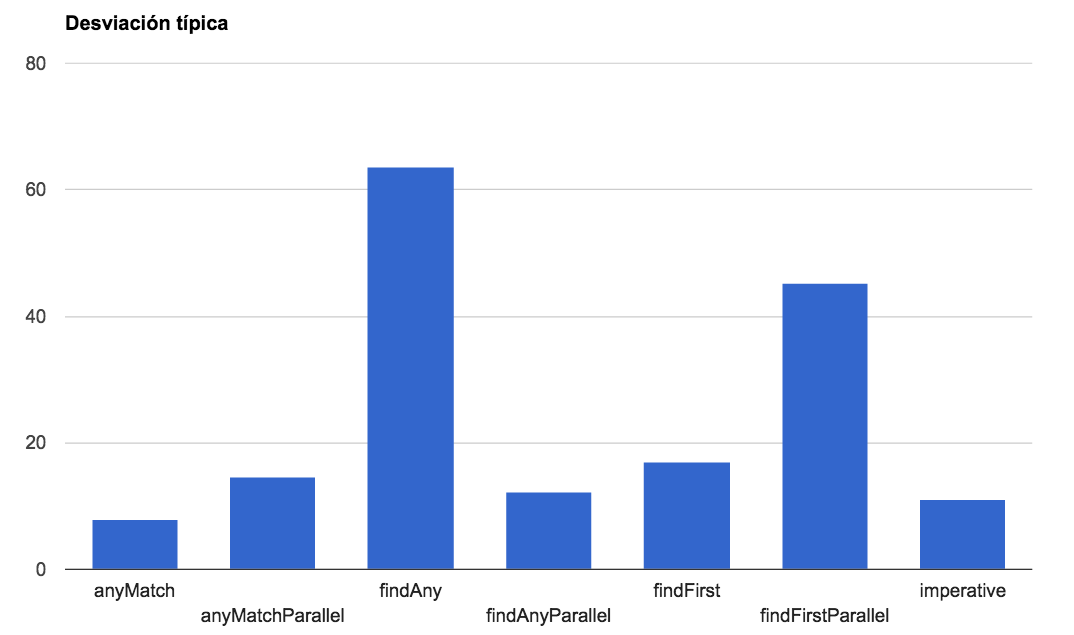
3.3. Media y Desviación típica
La media está realizada con la siguiente fórmula en cada LOAD_LEVEL:
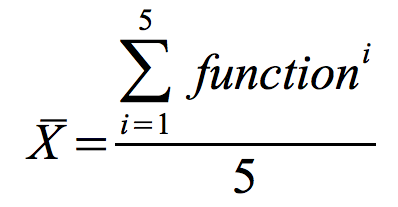
3.4. Curva de respuesta
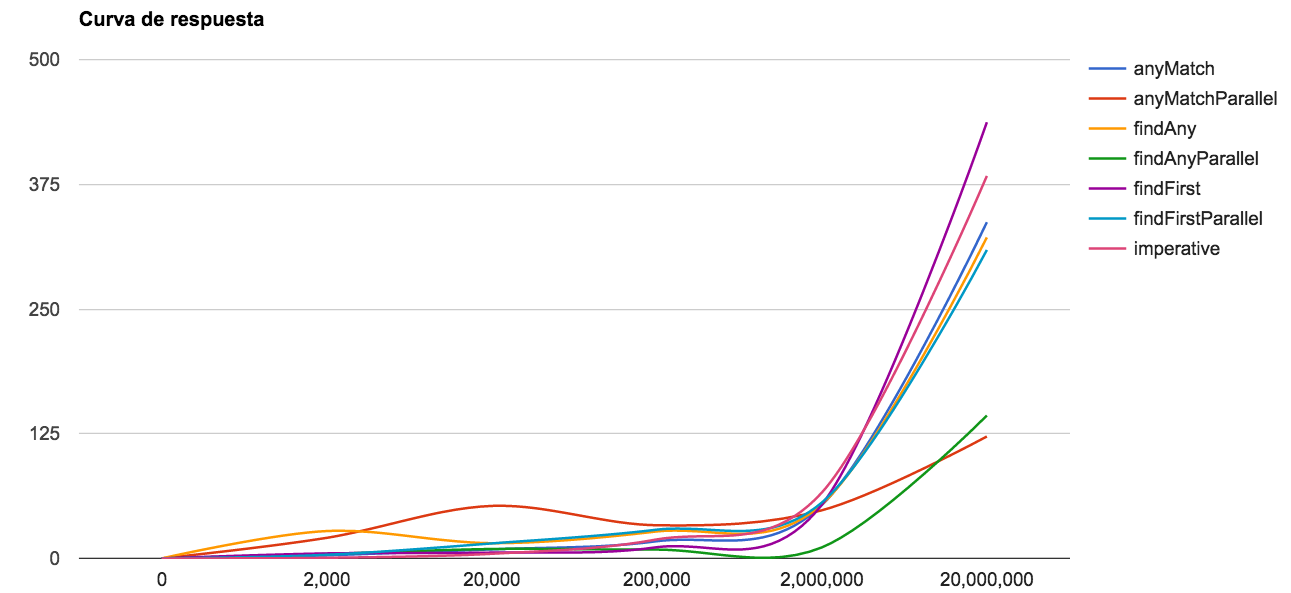
Gracias a los gráficos se puede comprobar que hay dos métodos cuya curva de respuesta y resultados son mucho mejores que los demás: anyMatchParallel y findAnyParallel. Si bien se puede observar que en valores bajos es incluso más pesado el trabajo que realizan las lambdas y streams que un bucle for.
Hay un resultado que me gustaría remarcar también y es el de findAny, cuya Desviación típica es la más grande, lo que viene a traducirse que sus resultados son menos uniformes y por lo tanto más inestables.
4. ¿Por qué?
Una vez obtenidos los resultados, vamos a averiguar el por qué de estos contando el número de iteraciones que realizan. Para ello modificamos los métodos y test para que usen el counter que ya teníamos creado.
¡OJO! El código que a continuación pongo solo debe usarse para el contador, no para el benchmark. Esto podría falsear mucho los resultados.
Añadimos el método peek() el cual recibe un consumidor. El método peek realiza un método pasado como una lambda pero no afecta a ninguna otra parte del stream. Es decir, es una operación intermedia cuya acción es invisible al resto de métodos. En este caso lo usamos para lanzar el método incrementAndGet() de AtomicLong, con el cual evitaremos una condición de carrera al contar iteraciones con multihilo
public boolean detectarErrorAnyMatch() {
return this.precios.stream()
.peek(precio -> counter.incrementAndGet())
.anyMatch(precio -> precio.intValue() < 0);
}
public boolean detectarErrorFindAny() {
return this.precios.stream().peek(precio -> counter.incrementAndGet())
.filter(precio -> precio.intValue() < 0)
.findAny()
.isPresent();
}
public boolean detectarErrorFindFirst() {
return this.precios.stream().peek(precio -> counter.incrementAndGet())
.filter(precio -> precio.intValue() < 0)
.findFirst()
.isPresent();
}
public boolean detectarErrorAnyMatchParallel() {
return this.precios.parallelStream().peek(precio -> counter.incrementAndGet())
.anyMatch(precio -> precio.intValue() < 0);
}
public boolean detectarErrorFindAnyParallel() {
return this.precios.parallelStream().peek(precio -> counter.incrementAndGet())
.filter(precio -> precio.intValue() < 0)
.findAny()
.isPresent();
}
public boolean detectarErrorFindFirstParallel() {
return this.precios.parallelStream().peek(precio -> counter.incrementAndGet())
.filter(precio -> precio.intValue() < 0)
.findFirst()
.isPresent();
}
@Test
public void testXXXX() {
carritoCompra.resetCounter();
testWith(()-> carritoCompra.detectarErrorXXXX());
long counter = carritoCompra.getCounter();
System.out.println("Iteraciones XXXX = " + counter);
}
El resultado:
LOAD_LEVEL = 200_000L Iteraciones anyMatch = 100_001 Iteraciones anyMatchParallel = 50_001 Iteraciones findAny = 100_001 Iteraciones findAnyParallel = 50_001 Iteraciones findFirst = 100_001 Iteraciones findFirstParallel = 100_001 Iteraciones imperative = 200_001
Solamente el ejemplo de Programación imperativa recorre todos los datos. Para dicho ejemplo necesitaríamos poner una comprobación más con un break y dicha práctica no es muy recomendable. Los métodos anyMatch, findAny, findFirst y findFirstParallel recorren hasta la primera coincidencia. anyMatchParallel y findAnyParallel recorren 1/4 del total ya que divide la carga por hilos, en mi caso 2 hilos. Cuando uno de esos hilos encuentra alguna (any) coincidencia se paran los demás.
Tanto findAnyParallel como anyMatchParallel hay veces que muestran los siguientes resultados:
LOAD_LEVEL = 200_000L Iteraciones anyMatchParallel = 50_001 Iteraciones anyMatchParallel = 150_002 Iteraciones anyMatchParallel = 100_001 Iteraciones findAnyParallel = 1 Iteraciones findAnyParallel = 125_002
Como ya dije, estos métodos se dividen por hilos y dependiendo de en qué momento el hilo esté más o menos ocupado, así se repartirán la carga recogiendo unos hilos más carga que otros.
A continuación dejo los resultados que he obtenido en otro ordenador
- Macbook Pro 15' Intel core i5 2'4GHz, 8GB DDR3
LOAD_LEVEL = 200_000L Iteraciones anyMatch = 100_001 Iteraciones anyMatchParallel = 175_002 Iteraciones findAny = 100_001 Iteraciones findAnyParallel = 125_001 Iteraciones findFirst = 100_001 Iteraciones findFirstParallel = 175_002 Iteraciones imperative = 200_001
LOAD_LEVEL = 200_000L Iteraciones anyMatchParallel = 162_502 Iteraciones anyMatchParallel = 187_502 Iteraciones findAnyParallel = 162_502 Iteraciones findAnyParallel = 162_501
5. Conclusiones
Una vez hechas todas las pruebas incluso en difrentes hardwares queda claro que, si se trata de grandes volúmenes de información, anyMatchParallel y findAnyParallel suponen una ventaja absoluta en cuanto a claridad y sencillez del código y rapidez de ejecución. Hemos visto que incluso en volúmenes muy pequeños sería hasta contraproducente usar streams y lambdas. Cuándo usarlos depende de muchos factores que cada desarrollador debe valorar por sí mismo.
6. Enlaces
Repositorio de github
Documento pdf con los resultados

