
Aunque el marco apropiado para profundizar en Elasticsearch sería un curso completo, en este tutorial se
intentará entrar lo máximo posible en las cuestiones más importantes del caso de uso planteado en el
primer tutorial
de esta serie y que consiste en recoger, almacenar y explotar logs de aplicaciones.
Este tutorial ocupa la tercera posición; aquí está el segundo.
Índice de contenidos
- 1. Introducción
- 2. Entorno
- 3. Instalación y configuración
- 4. Mappings
- 5. Montaje y administración de un cluster
- 6. Conclusiones
- 7. Referencias
1. Introducción
Elasticsearch es una base de datos distribuida totalmente enfocada a búsquedas sobre documentos estructurados.
Su capacidad de distribución la hace altamente escalable y tolerante a fallos, siendo además muy sencillo
gestionar un cluster de servidores.
La potencia de las búsquedas está apoyada por un lado por un completísimo API REST y por otro por el motor
Apache Lucene.
En este tutorial veremos cómo instalar, configurar y administrar un cluster de Elasticsearch.
Al mismo tiempo iremos repasando los conceptos más importantes de esta plataforma.
2. Entorno
Este tutorial utiliza el mismo entorno que la
introducción a ELK.
3. Instalación y configuración
3.1. Con Ansible
Los ejemplos mostrados aquí utilizarán el entorno virtual montado con Vagrant y Ansible para el
primer tutorial
de la serie.
Según esto, la configuración de Elasticsearch se basará en los valores de un diccionario llamado elasticsearch
definido en las variables del grupo de servidores stats, que es el grupo donde se instala Elasticsearch.
Actualmente el contenido de ese fichero es el siguiente:
ansible/environments/tutorial/group_vars/stats (fragmento)
# ElasticSearch
elasticsearch:
version: 2.2.0
cluster_name: "tutorial-stats"
index_number_of_shards: 1
index_number_of_replicas: 1
minimum_master_nodes: 1
http_host: "0.0.0.0"
network_host: "0.0.0.0"
http_publish_host: "10.0.2.2"
http_publish_port: "{{ es_http_port }}"
transport_publish_host: "10.0.2.2"
transport_publish_port: "{{ es_transport_port }}"
unicast_nodes: "{{ es_unicast_nodes }}"
plugins:
- { name: "kopf", path: "lmenezes/elasticsearch-kopf/2.0" }
Estos valores sobreescriben los valores por defecto asignados dentro del rol de Ansible elasticsearch,
que están definidos en el fichero siguiente:
ansible/roles/elasticsearch/defaults/main.yml
---
# Define custom settings in a dictionary called "elasticsearch".
_es_default:
version: 2.2.0
user: elasticsearch
group: elasticsearch
nofile: 32000
cluster_name: ""
node_name: "{{ ansible_fqdn }}"
is_node_master: yes
is_node_data: yes
index_number_of_shards: 5
index_number_of_replicas: 1
bootstrap_mlockall: yes
http_host: _local_
network_host: _local_
http_publish_host: ""
http_publish_port: 0
transport_publish_host: ""
transport_publish_port: 0
unicast_nodes: []
minimum_master_nodes: 1
java_opts: ""
# Taken from rack-roles elasticsearch:
# Use 40% of memory for heap, ES will also use large amount of
# direct memory allocation, hopefully ending with a total around 50%
# of the whole available system memory.
java_heap_size: "{{ (ansible_memtotal_mb * 0.4) | round | int }}m"
path_conf: /etc/elasticsearch
path_data: /var/lib/elasticsearch
path_home: /usr/share/elasticsearch
path_logs: /var/log/elasticsearch
path_plugins: /usr/share/elasticsearch/plugins
plugins:
- { name: head, path: mobz/elasticsearch-head}
# Combines default and custom settings.
_es_combined: "{{ _es_default | combine(elasticsearch) }}"
Cuando se cambie algún valor se debe forzar el provisionamiento de la máquina virtual donde se ejecuta
Elasticsearch:
Terminal
$ vagrant provision statsserver
3.2. Instalación manual
La instalación manual de Elasticsearch es muy sencilla gracias a los repositorios para Debian y RedHat disponibles en
la web oficial.
Se requiere una versión moderna de Java 7 o Java 8 hasta el punto de que la aplicación no se ejecutará si
detecta una versión con problemas conocidos.
Por otro lado, la configuración del servidor está repartida en los ficheros siguientes:
- /etc/default/elasticsearch contiene las opciones de arranque del servicio en Debian y derivados.
- /etc/sysconfig/elasticsearch se utilizará para configurar el arranque del demonio en RedHat y derivados.
- /etc/elasticsearch/elasticsearch.yml configura el comportamiento del servicio, principalmente cuestiones de
clustering y comunicaciones. Es necesario ser root para entrar a este directorio. - /etc/elasticsearch/logging.yml sirve para personalizar el sistema de logs de Elasticsearch. Hay que
ser root incluso para poder verlo.
3.3. Ajustes de configuración
Elasticsearch es tan flexible que dispone de innumerables opciones de configuración repartidas a lo largo de los módulos listados
en la documentación de referencia.
3.3.1. Cluster
El cluster es la unidad de servicio en Elasticsearch, es decir, es una base de datos completa a la que se conectan
los clientes para almacenar documentos y realizar búsquedas.
Lo mínimo recomendable es asignar un nombre al cluster y a cada nodo para poder identificarlos fácilmente
durante las tareas de administración.
Obviamente, todos los nodos del cluster deben usar el mismo nombre de cluster y diferente nombre de nodo.
También es muy recomendable fijar otros parámetros con un gran impacto sobre los recursos del nodo,
pero para saber cómo hacerlo a continuación explicaré algunos conceptos fundamentales.
Un cluster está estructurado a lo largo de dos ejes que podemos llamar «lógico» y «físico».
3.3.2. Índices
El eje lógico está representado por los índices, que no son más que particiones lógicas de los datos
basadas en los criterios de las aplicaciones que almacenan la información.
Un mismo dato (registro, documento, objeto o como nos apetezca llamarlo) no puede existir en dos índices
en el sentido de identidad; por supuesto sí que pueden existir dos documentos iguales en contenido.
En esta serie de tutoriales, Logstash reparte los mensajes de log por meses, es decir, existe un índice por mes.
Criterios válidos para saber cómo repartir los índices son: no mezclar en un índice datos de dominios dispares y
no tener índices muy pequeños ni excesivamente grandes (los detalles más abajo).
3.3.3. Nodos
El eje físico son los nodos del cluster, donde cada nodo es una máquina virtual Java ejecutando una instancia del servicio.
Por motivos de rendimiento de la JVM, el heap no debe superar el 40% de la RAM del servidor con un límite «hard»
de 32 GB que en la práctica queda reducido a unas 24 GB.
Es por esto que en servidores con más de 32 GB de memoria se ejecutan dos o más instancias de Elasticsearch teniendo
en cuenta que bajo ningún concepto deben compartir los directorios de configuración, datos y logs.
Elasticsearch distingue varios tipos de nodos:
- master, tienen como responsabilidad gestionar el cluster y asegurar su integridad.
Para que un cluster pueda funcionar debe tener al menos minimum_master_nodes nodos de este tipo (por defecto 1). - master-eligible son nodos candidatos a ser maestro en caso de que sea necesario, por ejemplo si se cae
algún maestro activo o el cluster está inicializándose y aún no se han seleccionado qué nodos van a actuar como maestros. - data, son los nodos normales que contienen los datos y ejecutan las búsquedas.
- client es un nodo que ni es maestro ni contiene datos, así que su única función es enrutar peticiones
dentro del cluster y como mucho agregar datos de consultas distribuidas. - tribe, cumplen una función de fachada, agregando varios clusters de manera transparente.
Los tipos de nodo master-eligible, data y client se consiguen combinando los parámetros de configuración
node.master (is_node_master en Ansible) y node.data (is_node_data en Ansible).
Los nodos tribe requieren configuración especial.
En el capítulo 5 vamos a añadir un segundo nodo al cluster básico del ejemplo de los tutoriales.
3.3.4. Shards
Las shards es donde realmente se realizan las operaciones de indexación y búsqueda en Elasticsearch y
es la unidad de distribución de trabajo en el cluster.
Internamente es una instancia de Apache Lucene con sus datos, metadatos e índices (no confundir con el
concepto de índice de Elasticesarch).
Cuando se busca, Elasticsearch lanza la consulta en todas las instancias de Lucene implicadas y después
combina los resultados y puntuaciones.
Cada índice tiene un número fijo y predeterminado de shards primarias, que son las fuentes que contienen la
información almacenada e indexada en Elasticsearch.
La única manera de añadir o quitar shards primarias es recrear el índice (reindexar), que puede ser bastante costoso.
Otra cosa son las shards de respaldo: copias que se distribuyen por los nodos del cluster para conseguir mayor
rendimiento, alta disponibilidad y backup y que sí se pueden añadir y quitar en cualquier momento.
Entonces ¿cuántas shards primarias por nodo se deben tener?
Esto depende mucho de cómo responda el servidor ante la carga de trabajo que se le va a dar, así que la recomendación es
hacer pruebas de carga y rendimiento con un conjunto de datos representativo (hablamos de gigas) en un índice con una shard.
Esto nos dirá cuántas shards primarias puede soportar el nodo y el tamaño de una shard (número de documentos indexados)
antes de que el servidor muera o el rendimiento caiga por debajo de lo que se considere aceptable.
A falta de pruebas que aporten datos realistas, hay que tener en cuenta que la configuración óptima es
una shard primaria por nodo e índice. Sin embargo esto depende mucho de:
- El crecimiento esperado de los datos y concretamente cuántos índices van a existir.
- La potencia de los equipos en los que se ejecutan los nodos, en concreto cuánta memoria y cuántos núcleos tienen.
- Y el número de usuarios que van a explotar el sistema de manera concurrente y con qué tipo de consultas.
Así que si esto tampoco está muy claro, la recomendación es simplemente dos shards primarias por nodo.
Esto permitirá en el futuro duplicar el tamaño del cluster sin necesidad de reindexar.
4. Mappings
Elasticsearch con Lucene por debajo estará encantado de indexar cualquier tipo de documento con la configuración por defecto,
que básicamente consiste en tokenizar los textos e intentar detectar otros valores primitivos como los números enteros.
En los casos más simples esto será suficiente, pero lo normal y más conveniente es especificar la
estructura de los registros que se van a almacenar y cómo queremos que Elasticsearch indexe los valores.
Por ejemplo, en el caso de uso de este tutorial, Logstash hace dos cosas (la primera automática y la segunda manual):
- Por cada campo del registro, genera un subcampo con el sufijo raw que Lucene no debe analizar y
sobre el que sólo se pueden buscar cadenas exactas. - El valor del campo @timestamp es una fecha por el que se pueden hacer ordenaciones y filtrados por intervalos.
4.1. Mapping como tipo de documento
Cada documento de Elasticsearch tiene asociado un tipo, una idea equivalente a la de tabla en bases de datos relacionales.
El tipo se define a través de su mapping, el cual determina la estructura del documento (campos), el tipo de valores
de los campos y el modo en que deben indexarse esos valores de cara a posteriores búsquedas (o sea, el analizador
que controla la tokenización, stemming y otros procesamientos del texto).
La mayoría de APIs REST de Elasticsearch pueden seleccionar los documentos de un tipo determinado sin más que indicarlo
en la segunda posición del path de la URL (la primera posición es para el índice).
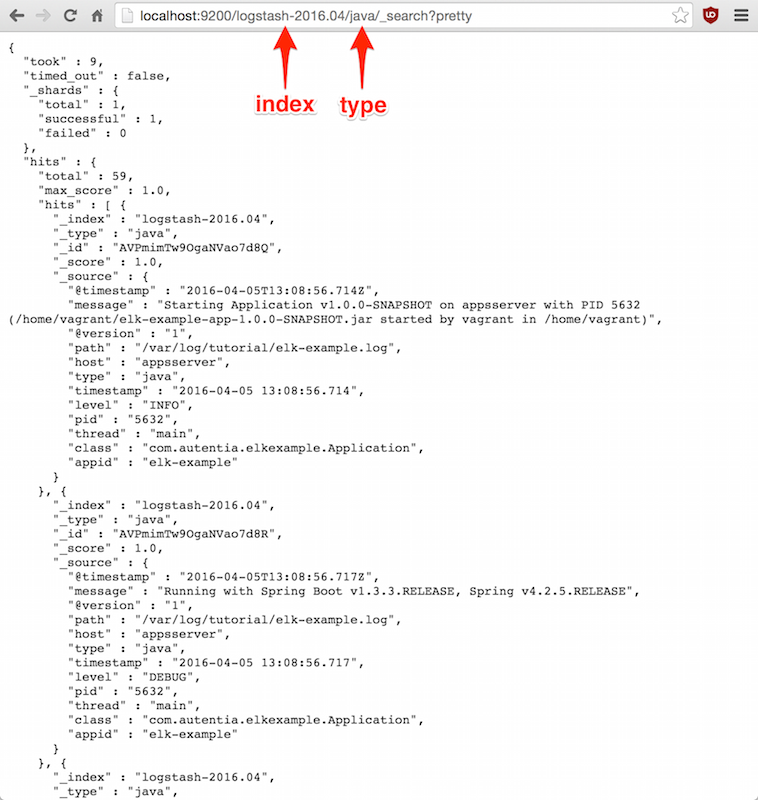
Por ejemplo, en la base de datos de estos tutoriales, el tipo de los documentos es java, así que para obtener
los mensajes de log Java de Abril de 2016 podríamos hacer la siguiente llamada REST GET
(recordar que los índices siguen el patrón de nombrado logstash-YYYY.MM):
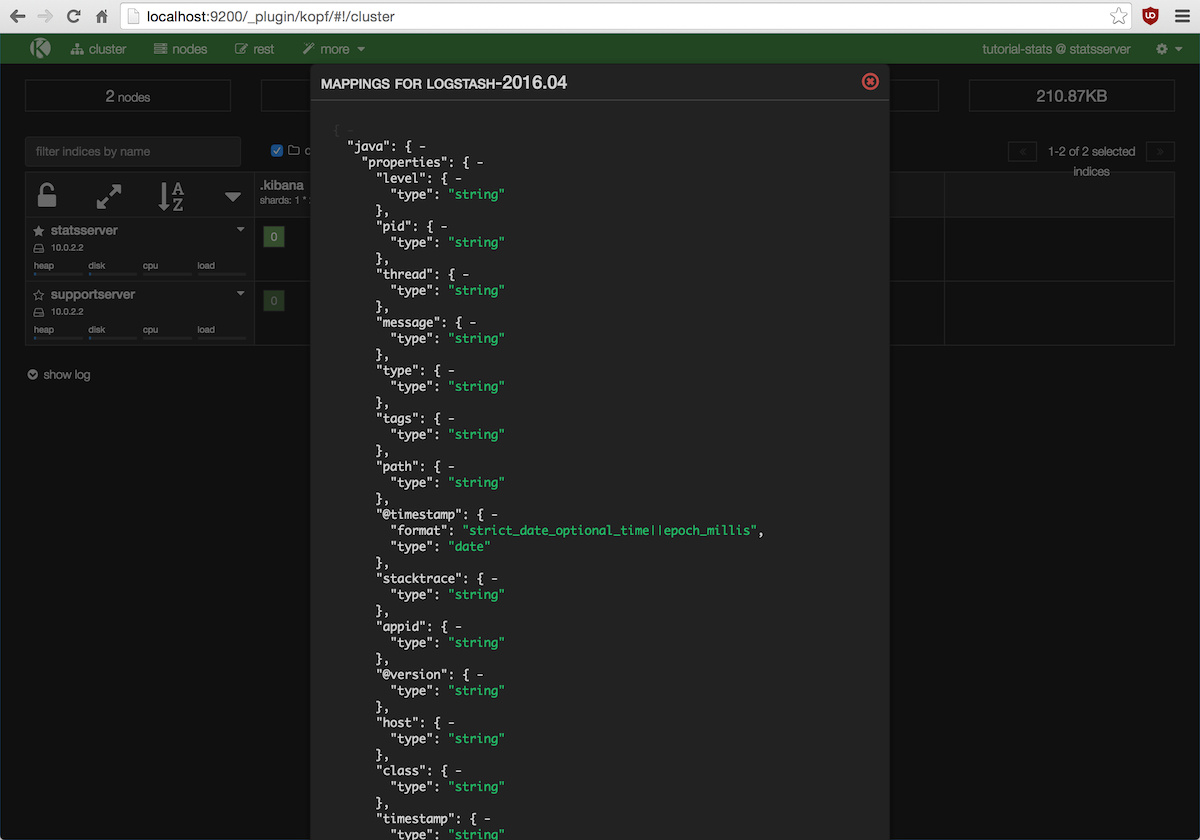
Por otro lado, se puede utilizar el plugin Kopf para ver los mappings de un índice haciendo clic sobre él y
seleccionando la opción show mappings. Por ejemplo, este es el mapping de los mensajes de log de tipo java
creados por Logstash:
4.2. Definición de mappings
Es importante definir los mappings aceptados por un índice antes de almacenar en ellos el primer documento.
Si el cliente no lo hace explícitamente, el propio Elasticsearch creará un mapping dinámico con el comportamiento
por defecto que se describió al principio de este capítulo.
Además, una vez se asocia un mapping a un tipo (ya sea de forma manual o dinámica), ya no es posible cambiarlo
aunque sí ampliarlo.
La razón es que los cambios seguramente afectarán al modo en que se indexan los datos, requiriendo por tanto
recrear los índices de las shards.
Entonces ¿cómo se lleva a cabo un cambio de mapping?
La solución es reindexar los documentos moviéndolos a otro índice donde esté definido el nuevo mapping.
Dada la importancia de asociar mappings a un índice antes de guardar nada en él, Elasticsearch permite definir
plantillas de mappings.
La plantilla, llamada template, consta de un patrón de nombre de índice y uno o más mappings asociados
a tipos de documentos.
Con esto, cuando algún cliente crea un índice que cumple el patrón, Elasticsearch asocia los mappings al índice
de manera automática.
El plugin Kopf incluye una opción para gestionar las templates del cluster en la opción index templates
del menú more….
5. Montaje y administración de un cluster
En este capítulo vamos a ampliar el cluster de Elasticsearch utilizado como ejemplo de esta serie de tutoriales
(ver el primer tutorial
para más información).
Originalmente, sólo existe un nodo de Elasticsearch en el servidor statsserver.
Ahora vamos a añadir otro servidor llamado supportserver exactamente con las mismas características.
5.1. Despliegue del segundo servidor
Como el ejemplo utiliza Vagrant y Ansible para la creación y provisionamiento de las máquinas virtuales, este
proceso va a ser muy sencillo:
- Editar el fichero Vagrantfile para añadir un tercer servidor a la lista de máquinas virtuales.
Esto se consigue añadiendo un tercer elemento a cada uno de los arrays servers, ssh_ports,
kibana_ports, es_http_ports y es_transport_ports.
Los valores son respectivamente: «supportserver», 2225, 5602, 9201 y 9301. - Editar el fichero ansible/environments/tutorial/inventory para indicar que supportserver debe
provisionarse igual que el otro servidor de estadísticas: - Aunque esto no es imprescindible, aprovecharemos para instalar el plugin
ElasticHQ para monitorizar los recursos consumidos por Elasticsearch.
Para ello, añadiremos un nuevo elemento al diccionario plugins de la configuración elasticsearch
en el grupo de hosts stats: - Desde una terminal en el directorio elk-tutorial ejecutar los comandos siguientes:
Vagrantfile (fragmento)
servers = ["appsserver", "statsserver", "supportserver"]
ssh_ports = [2223, 2224, 2225]
kibana_ports = [0, 5601, 5602]
es_http_ports = [0, 9200, 9201]
es_transport_ports = [0, 9300, 9301]
ansible/environments/tutorial/inventory
[apps]
appsserver
[stats]
statsserver
supportserver
ansible/environments/tutorial/group_vars/stats (fragmento)
---
# ElasticSearch
elasticsearch:
...
plugins:
- { name: "kopf", path: "lmenezes/elasticsearch-kopf/2.0" }
- { name: "hq", path: "royrusso/elasticsearch-HQ" }
Terminal
$ vagrant up
$ vagrant provision
5.2. Monitorización del cluster
Tras el despliegue, los dos nodos deberían sincronizarse rápidamente, y la primera consecuencia es que el estado
del cluster pasará de amarillo a verde como se puede ver en la siguiente captura del
plugin Kopf:
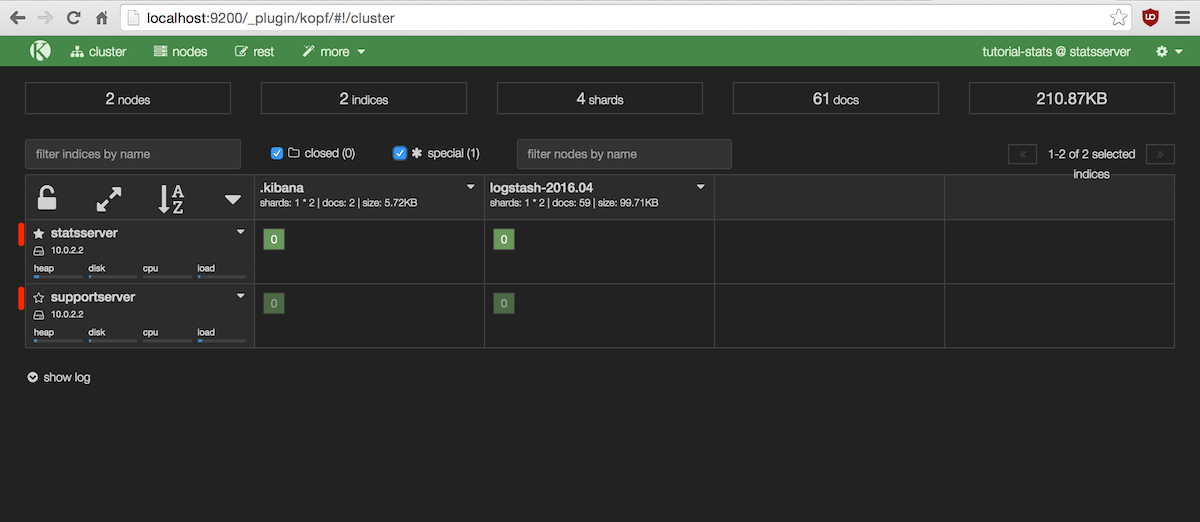
El código de color en Elasticsearch releja el estado de las shards.
Rojo significa que al menos una shard primaria no está disponible; amarillo que alguna shard de respaldo
no está asignada a ningún nodo y verde que todas las shards están activas.
También es interesante fijarse en las estrellas a la izquierda del nombre de los nodos.
Una estrella sólida significa que ese nodo es el master y una estrella hueca que el nodo es
master-eligible; si no hay estrella es que el nodo no puede ser elegido master.
Como en este despliegue minimum_master_nodes es 1, sólo uno de los nodos elegibles es maestro.
Bajo los iconos de estrella también aparece uno de un disco duro que significa que ese nodo puede almacenar datos,
es decir, es un nodo data.
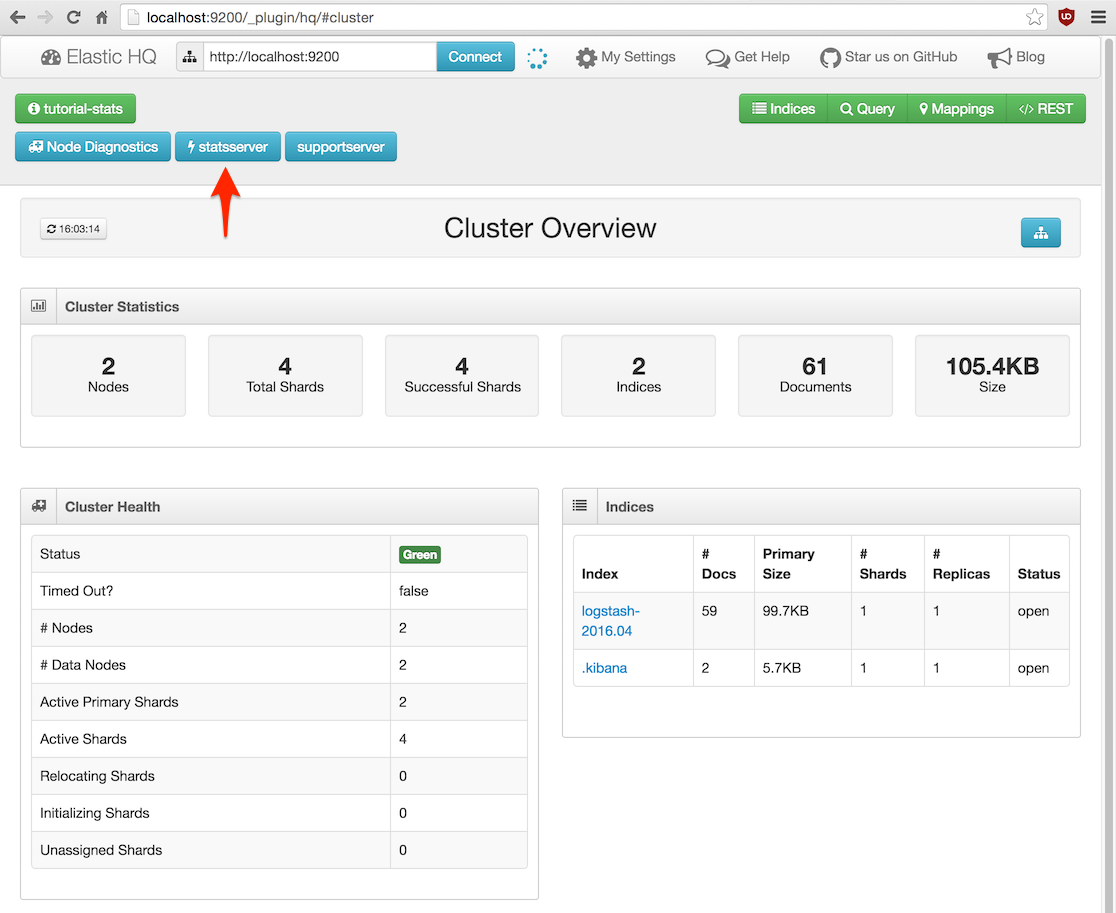
Aparte de esto, en la dirección http://localhost:9200/_plugin/hq/#cluster
podemos acceder a ElasticHQ para monitorizar los recursos consumidos por el cluster y los nodos.
Pulsar el botón Connect para cargar la información:
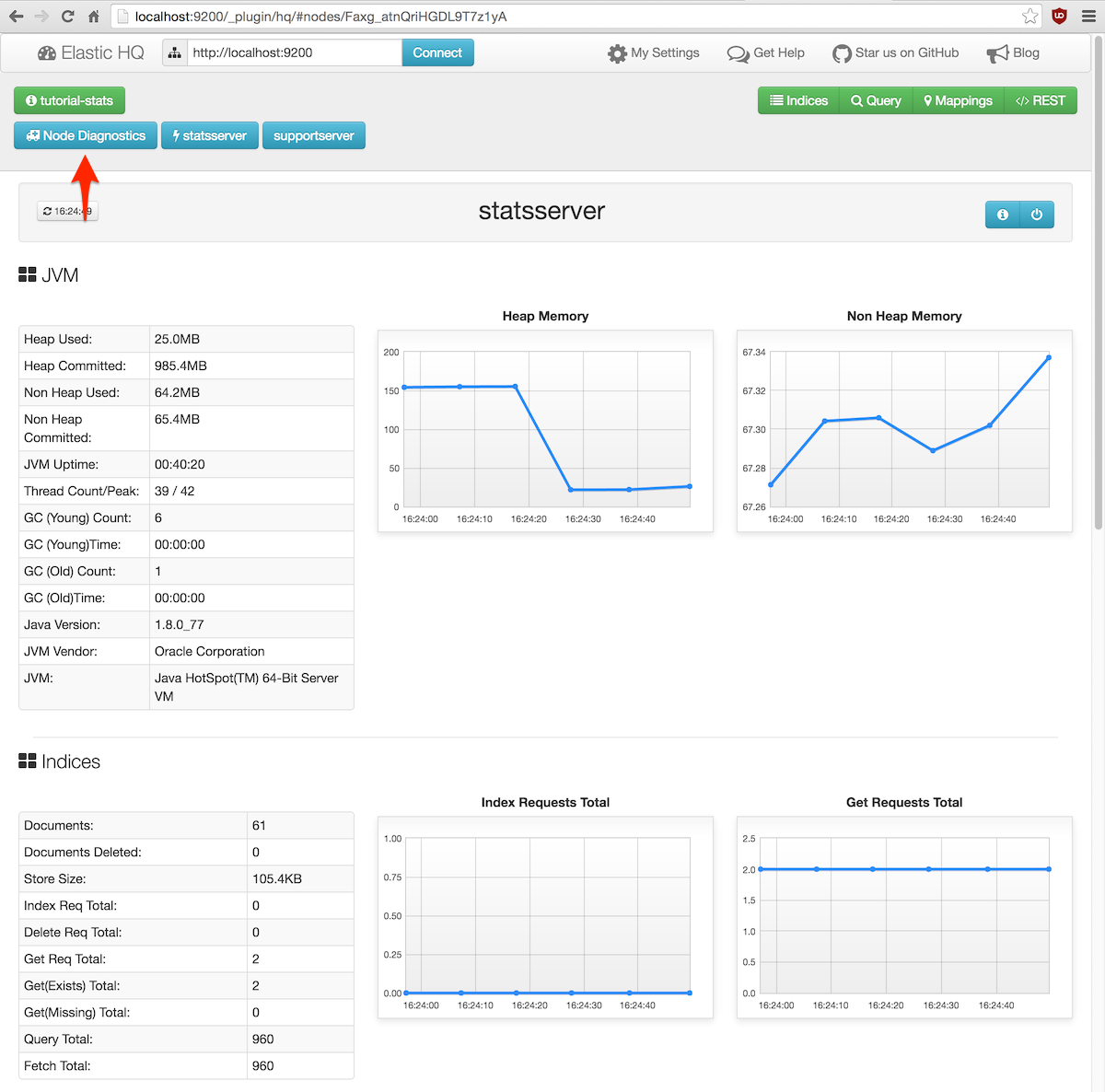
Se puede entrar a ver el estado de un servidor concreto pulsando sobre el botón con su nombre, por ejemplo statsserver:
Pero lo más interesante son los indicadores del cluster, a los que se llega pulsando el botón Node diagnostics:
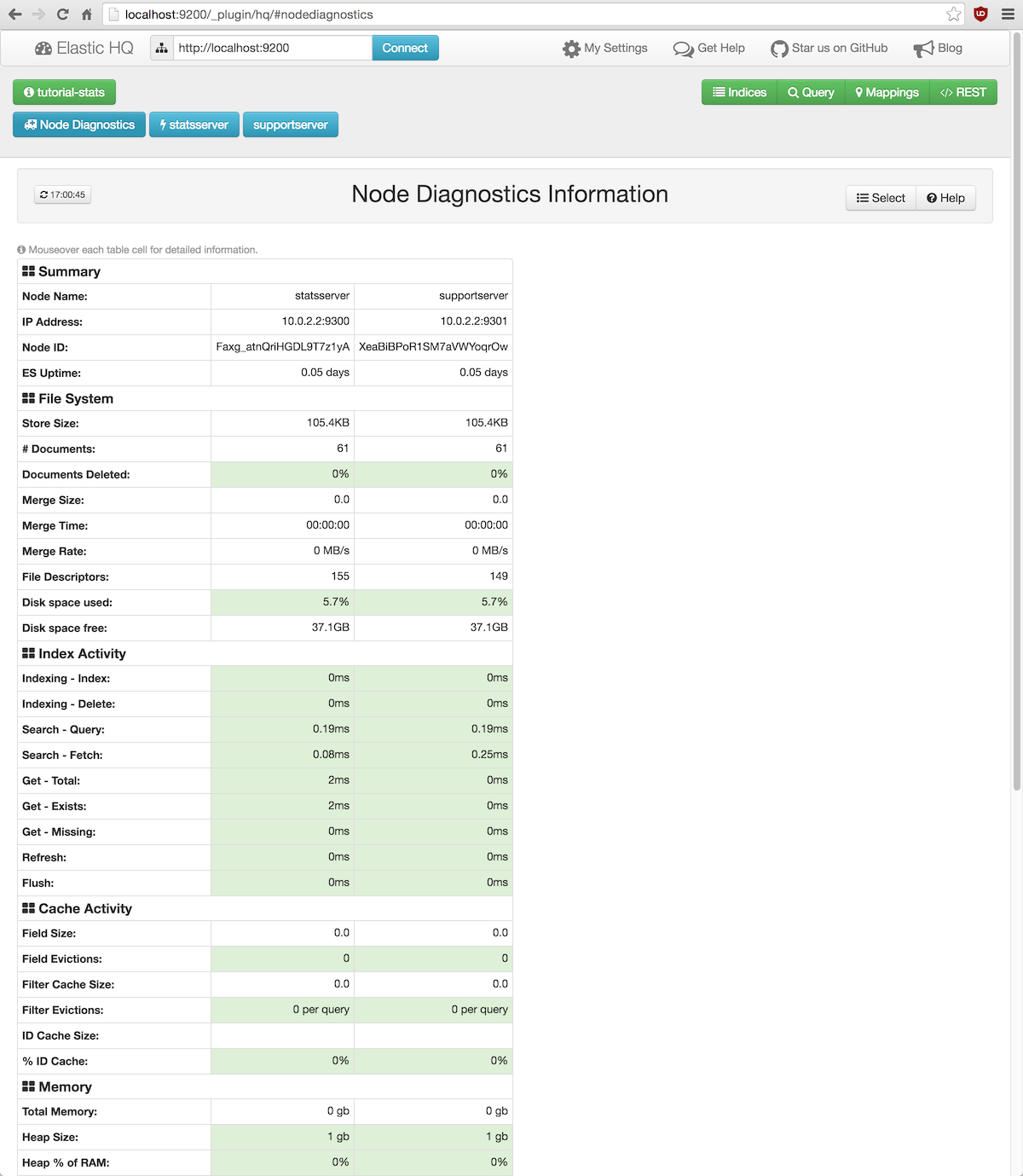
ElasticHQ tiene una serie de umbrales preestablecidos para estos indicadores que nos permiten averiguar de un
vistazo la salud general del cluster a partir de los colores verde, amarillo y rojo.
Los problemas pueden venir por diferentes frentes:
- Si se están indexando muchos documentos Lucene puede no tener tiempo de compactar y mezclar sus índices.
Esto provoca «throttling», es decir, una disminución de la velocidad de almacenamiento de los documentos que
influye mucho en el tiempo de ejecución de las consultas porque los índices no están optimizados.
Indicadores a vigilar: Documents Deleted, Indexing – Index e Indexing – Delete. - Cuando las consultas implican muchos datos y transformaciones, Elasticsearch puede llegar a consumir
enormes cantidades de memoria y CPU, pudiendo llegar a provocar la caída del servicio.
Los indicadores que dan pistas sobre esta situación son: Search – Query, Search – Fetch,
Field Evictions y Filter Evictions.
6. Conclusiones
No hay recetas mágicas para la administración de un servidor Elasticsearch y la recomendación general pasa
por evaluar las necesidades en función del uso, a ser posible con un entorno de pruebas realista.
Si esto no es posible, entonces dimensionar el cluster pensando en el futuro y monitorizarlo continuamente
para descubrir desviaciones y comportamientos indeseables lo antes posible.
Lo normal es que antes de caerse, el servicio dé señales de fatiga, por ejemplo con una bajada importante del rendimiento.
Si no estamos atentos, al final puede que nos encontremos con una caída que quedará registrada en el syslog
del servidor como puede verse aquí:
/var/log/syslog (fragmento)
Apr 6 11:42:04 vagrant-ubuntu-trusty-64 kernel: [31483.385167] Out of memory: Kill process 6321 (java) score 524 or sacrifice child Apr 6 11:42:04 vagrant-ubuntu-trusty-64 kernel: [31483.385503] Killed process 6321 (java) total-vm:3306088kB, anon-rss:1051848kB, file-rss:20928kB
Otra cuestión pendiente es la seguridad, que no es que haya sido ignorada aquí sino que es tan importante que en sí
misma daría materia para otro tutorial (tomo nota mental para el futuro).
Básicamente tendríamos dos opciones:
- Autenticación externa mediante un proxy inverso Apache o Nginx con posibilidad de autorizar según patrones de URLs.
- O uno de los varios plugins de autenticación y autorización disponibles, incluyendo Shield que es el producto que vende Elastic.
Recordar que si no se adopta ninguna medida, cualquier cliente puede acceder a Elasticsearch a través de su API REST
sin ningún tipo de restricción.
Por último recordar que el próximo y último tutorial de la serie abordará la explotación de datos con Kibana.


excelente los artículos y ojalá vengas más sobre todo tips para no cometer errores en producción