
Después de la visión general
de la plataforma ELK para extracción y análisis de logs de aplicaciones, aquí podrás conocer en profundidad
las posibilidades que ofrece Logstash para extraer y transformar mensajes de log.
Índice de contenidos
- 1. Introducción
- 2. Entorno
- 3. Instalación y configuración de Logstash
- 4. Procesando logs de Spring Boot
- 5. Generando alertas por errores
- 6. Conclusiones
- 7. Referencias
1. Introducción
Aunque en esta serie de tutoriales Logstash se utiliza para recoger logs, procesarlos y almacenarlos en
Elasticsearch, esta aplicación es una solución flexible de agregación y normalización de información
de fuentes diversas.
2. Entorno
Este tutorial utiliza el mismo entorno que la
introducción a ELK.
- Hardware anfitrión: Portátil MacBook Pro Retina 15′ (2.5 Ghz Intel Core i7, 16GB DDR3)
- Hardware huesped: dos servidores con 2,5 GB RAM y 2 CPUs
- Sistema operativo anfitrión: Mac OS Yosemite 10.10
- Sistema operativo huesped: Ubuntu Server 14.04.4 LTS 64 bits
- Elasticsearch 2.2.1
- Logstash 2.2.2
- Kibana 4.4.2
- Ansible 2.0.1
- Vagrant 1.8.1
- VirtualBox 5.0.14
- Maven 3.3.9
3. Instalación y configuración de Logstash
3.1. Con Ansible
Este tutorial utiliza Ansible para instalar y configurar Logstash, así que para personalizarlo solamente
hay que preocuparse de sobreescribir los valores por defecto del rol logstash.
Esto se consigue añadiendo los nuevos valores a un diccionario logstash en el fichero de variables
del grupo apps (que es donde se instala Logstash).
En este tutorial en concreto se redefinen las claves inputs, filters y outputs tal que así:
ansible/environments/tutorial/group_vars/apps (fragmento)
---
# Logstash
logstash:
inputs: |-
file {
type => "java"
path => ["/var/log/tutorial/*.log"]
codec => multiline {
pattern => "^%{TIMESTAMP_ISO8601}"
negate => "true"
what => "previous"
}
sincedb_path => ["/var/lib/logstash/sincedb"]
start_position => "beginning"
}
filters: |-
grok {
match => {
"message" =>
"^%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:level}\s+%{NUMBER:pid}\s+---\s+\[\s*%{USERNAME:thread}\s*\]\s+%{JAVAFILE:class}\s*:\s*%{DATA:themessage}(?:\n+(?<stacktrace>(?:.|\r|\n)+))?$"
}
}
date {
match => [ "timestamp" , "yyyy-MM-dd HH:mm:ss.SSS" ]
}
mutate {
rename => {
"themessage" => "message"
}
add_field => {
"appid" => "%{[path]}"
}
}
mutate {
gsub => [ "appid", "^.+/([^.]+)\..+$", "\1" ]
}
outputs: |-
elasticsearch {
index => "logstash-%{+YYYY.MM}"
# This is the host's ip address under VirtualBox.
hosts => ["10.0.2.2"]
}
Aunque las mencionadas inputs, filters y outputs son las variables más importantes,
se puede consultar todos los valores por defecto en el siguiente fichero:
ansible/roles/logstash/defaults/main.yml (fragmento)
---
# Define custom settings in a dictionary called "logstash".
_logstash_default:
version: "{{ _logstash_version }}"
apt_repo: "deb http://packages.elasticsearch.org/logstash/{{ _logstash_version }}/debian stable main"
repo_key: "http://packages.elasticsearch.org/GPG-KEY-elasticsearch"
yum_repo_dest: "/etc/yum.repos.d/logstash.repo"
inputs: ""
filters: ""
outputs: ""
conf_dir: "/etc/logstash/conf.d/"
home_dir: "/opt/logstash/"
options: ""
user: "logstash"
group: "logstash"
# Required to avoid recursive reference within dictionary.
_logstash_version: "{{ logstash.version | default(2.2) }}"
3.2. Manualmente
En caso de no utilizar Ansible, lo más cómodo es instalar el paquete desde el
repositorio oficial de Elastic
teniendo en cuenta que requiere Java 7 o posterior.
De esta manera, para configurar Logstash será necesario ir a estos lugares:
- /etc/default/logstash para cambiar las opciones de arranque del demonio en Debian y derivados.
- /etc/sysconfig/logstash para las opciones de arranque del demonio en RedHat y derivados.
- /etc/logstash/conf.d/ para dejar aquí ficheros de definición de entradas, filtros y salidas.
También habrá que asegurarse de que el sistema operativo arranca el servicio Logstash automáticamente.
3.3. Entradas, filtros y salidas
En cualquier caso, la configuración siempre consta de una sección input y otra output.
También es seguro que se definirá la sección filter, que es uno de los puntos fuertes de Logstash
y por lo que destaca sobre otras opciones más ligeras.
El demonio de Logstash obtiene esta información de todos los ficheros que encuentre en el directorio
/etc/logstash/conf.d.
También es posible lanzar la herramienta desde línea de comandos indicándole la ruta del fichero de configuración.
Esto lo vamos a comprobar con el siguiente ejemplo, que lee de la entrada estándar, geolocaliza cualquier
dirección IP introducida y vuelca la información en la salida estándar:
geoip_example
input {
stdin {}
}
filter {
grok {
match => {"message" => "%{IP:ip}"}
}
geoip {
source => "ip"
}
}
output {
stdout {
codec => rubydebug
}
}
Para mayor comodidad, los ejemplos se ejecutarán desde la máquina virtual appsserver definida en el
primer tutorial.
Recordar que para entrar a la máquina appsserver es necesario ejecutar estos comandos desde
el directorio elk-tutorial:
Terminal
$ vagrant up $ vagrant ssh appsserver
Y a continuación introducir lo que aparece en los cuadros rojos:
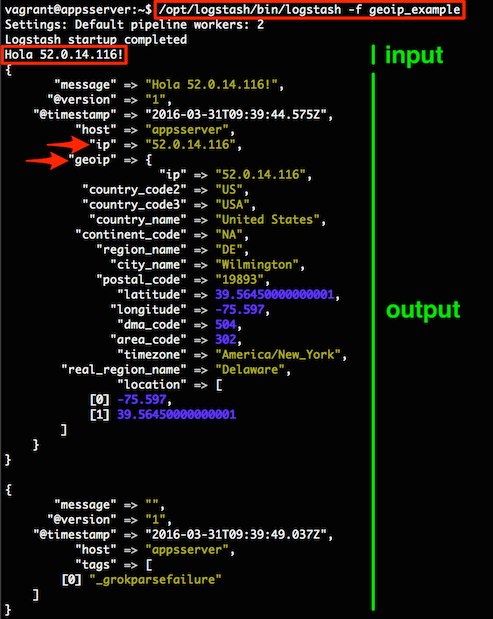
Volviendo al fichero geoip_example, en la sección input se indican las fuentes de datos,
en este caso stdin sin ningún parámetro de configuración.
Todas las entradas disponibles están documentadas
aquí.
La sección filter se ejecuta secuencialmente, primero el filtro
grok y luego
geoip.
El primero extrae campos estructurados (ip en este caso) de una cadena (message)
mediante una regex con grupos de captura (clase predefinida %{IP} en este ejemplo).
Existen un montón de clases predefinidas para muchos campos típicos, todas especificadas en este
repositorio de GitHub.
Grok Debugger también es muy útil a la hora de probar patrones Grok
y consultar las clases.
Esto nos lleva a otro concepto clave de Logstash: los mensajes no son texto plano, sino objetos con campos tipados.
En la captura de pantalla anterior se ve claro que cada objeto tiene varios campos predefinidos:
message, @version, @timestamp y host.
Sobre esos, el filtro grok ha generado el campo ip y la ejecución de geoip ha generado el campo
compuesto del mismo nombre.
Por último, de la salida no hace falta explicar mucho: se trata de stdout con un codec rubydebug
que hace un pretty-print de los campos de los eventos de log.
Todos los plugins de salida están documentados
aquí.
3.4. Detección de errores
Cuando se intenta ejecutar Logstash con una configuración no válida, la herramienta directamente no arranca.
Si el error se produce en tiempo de ejecución, la aplicación seguirá en marcha y lo único que hará será
dejar un registro en su log, que está en la ruta /var/log/logstash/logstash.log (parece un trabalenguas).
Aquí se puede ver un fallo de conexión con Elasticsearch:
Terminal
{:timestamp=>"2016-04-01T14:49:10.940000+0000", :message=>"No route to host", :class=>"Manticore::SocketException", :level=>:error}
Por defecto, Logstash sólo registra errores en su log, lo que dificulta depurar comportamientos incorrectos.
Para cambiar esto, se debe arrancar Logstash con la opción –verbose (algo más de información)
o –debug (mucha información).
Si estamos usando Ansible, esto se consigue modificando la variable logstash.options del grupo apps,
teniendo entonces el siguiente código:
ansible/environments/tutorial/group_vars/apps (fragmento)
---
# Logstash
logstash:
options: "--verbose"
inputs: |-
...
filters: |-
outputs: |-
...
Para aplicar el cambio no olvidar ejecutar el siguiente comando desde una terminal de la máquina anfitrión:
Terminal
$ vagrant provision appsserver
4. Procesando logs de Spring Boot
Con lo explicado hasta ahora, ha llegado el momento de diseccionar la configuración que se utilizó con
la aplicación elk-example-app del
anterior tutorial.
4.1. Entrada
El plugin file lee las líneas de los ficheros que encajan en el array de globs de la propiedad path,
en este caso /var/log/tutorial/*log.
En los logs de Java no es correcto asumir que cada línea del fichero es un evento de log; las trazas de
excepciones en particular generan muchas líneas.
Por esta razón se utiliza el codec multiline con una configuración que significa:
«Todo lo que no (negate a true) empiece por una fecha (el pattern) debe ser concatenado
con el evento de log anterior (what es previous)»
Las dos últimas propiedades consiguen un procesamiento de ficheros más robusto, sin pérdida de líneas
y sin líneas duplicadas.
Para saber qué ficheros han sido procesados y hasta qué línea, file mantiene una lista de inodos con
la posición dentro del fichero hasta donde ha procesado. Esta lista se conoce como sincedb.
Por otro lado, start_position con beginning asegura que se leen todas las líneas desde el principio.
4.2. Filtros
El log de las aplicaciones Spring Boot es bastante rico y contiene mucha información interesante para extraer con
el plugin grok utilizando clases predefinidas y un grupo nombrado:
- Con TIMESTAMP_ISO8601 se extrae al campo timestamp la fecha y hora en que se registró el evento.
- La clase LOGLEVEL extrae al campo level el nivel del mensaje.
- La clase general NUMBER en esa posición de la línea de log representa el pid del proceso de la aplicación.
- Luego se usa la clase USERNAME, que parsea nombres de usuario, para el nombre del hilo (thread).
- JAVAFILE es un patrón para analizar nombres completos de clases Java, que se guardan en el campo class.
- DATA es un patrón para cualquier cosa excepto saltos de línea y representa el cuerpo del mensaje (themessage).
- Por último, se utiliza una captura de grupo nombrado en formato (?<nombre-grupo>patrón) para extraer
la traza de una excepción en caso de que exista.
El grupo nombrado stacktrace también se añade al objeto Logstash.
Por defecto, Logstash toma como fecha del evento de log el instante en que procesa ese evento.
Lógicamente esto no es lo deseable porque cada mensaje de log ya lleva su marca de tiempo propia.
Con este filtro date, Logstash utilizará como fecha el valor del campo timestamp extraído con grok.
Los filtros mutate realizan estas tareas en este orden:
- rename: reemplazar el campo message original con el cuerpo del mensaje extraído en themessage.
- add_field: copiar al campo appid la ruta del fichero de log para extraer
después el nombre de la aplicación. - gsub: capturar con una regex el nombre del fichero de log sin extensión
y usarlo como valor de appid.
La razón de tener dos mutate es que dentro de un mutate las operaciones no se aplican en ningún orden
determinado y en este tutorial es necesario que primero se realice la operación add_field y después el gsub.
4.3. Salida
Los objetos resultantes se envían a Elasticsearch para que los almacene en un índice mensual de Logstash
según el patrón logstash-%{+YYYY.MM}.
Si la aplicación o aplicaciones generan enormes cantidades de log, se puede decidir tener un índice semanal
o incluso diario, aunque no es raro tener índices de cientos de gigas e incluso teras.
5. Generando alertas por errores
En el primer tutorial
se sugirió Watcher como herramienta de alertas basada en consultas sobre los datos en Elasticsearch.
Una alternativa gratuita a Watcher es una salida Logstash que envíe mensajes de alerta por e-mail
o algún otro sistema de mensajería instantánea como Slack.
5.1. Configurando las alertas
Para enviar un e-mail cada vez que se reciba un evento de log de nivel ERROR, añadiremos el plugin email
a la sección output de nuestra configuración Logstash.
El plugin está envuelto en una condición (sentencia if) que evalúa si el campo level del evento es ERROR:
if [level] == "ERROR" {
email {
address => "smtp.gmail.com"
port => "587"
use_tls => true
username => "origen@gmail.com"
password => "xyz"
from => "origen@gmail.com"
to => "destino@gmail.com"
subject => "%{[appid]}: ERROR"
body => "An ERROR event has been detected on %{[appid]}:\n- Timestamp: %{[timestamp]}\n- Source: %{[class]}\n- Message: %{[message]}\n- Stacktrace: %{[stacktrace]}"
}
}
Con Ansible, habrá que añadir este texto a la variable logstash.outputs del fichero
ansible/environments/tutorial/group_vars/apps y ejecutar el siguiente comando para actualizar la máquina virtual:
Terminal
$ vagrant provision appsserver
5.2. Habilitando el acceso en Gmail
Antes de probar las alertas, si la cuenta SMTP desde la que se va a enviar el correo pertenece a Gmail,
es necesario entrar a esta web
para habilitar el acceso «menos seguro» a esa cuenta de correo:
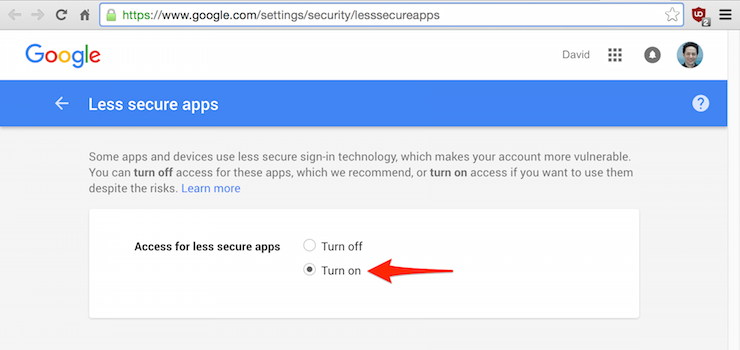
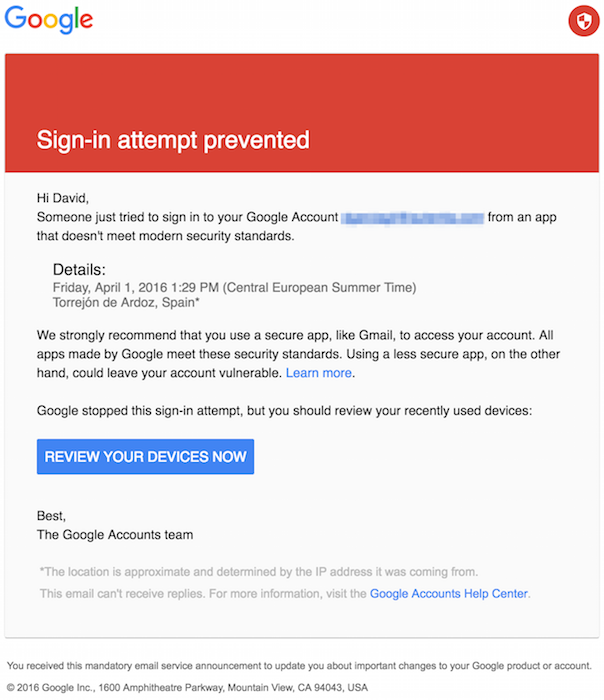
De no hacerlo, Gmail enviará este correo a la cuenta de origen:
5.3. Probando las alertas
A continuación sólo falta ejecutar la aplicación de prueba desde la máquina virtual appsserver:
Terminal
$ java -jar elk-example-app-1.0.0-SNAPSHOT.jar duration=10
Y unos segundos después la cuenta de correo de destino recibirá mensajes como este:
6. Conclusiones
No hay muchas alternativas a Logstash que se aproximen a su potencia, flexibilidad y soporte.
Este tutorial ha demostrado sus funciones más interesantes y cómo sacarles provecho, aunque queda
mucho por descubrir navegando entre el mar de plugins disponibles, tanto oficiales como extraoficiales
(sólo hay que buscar un poco en los repositorios de GitHub).
Claro, estas posibilidades no vienen gratis e implican que Logstash puede llegar a consumir bastantes recursos
en un servidor que nos interesa aprovechar al máximo para nuestras aplicaciones.
Para mitigar este problema, Elastic ha publicado Beats y en concreto Filebeat.
Los agentes Beats son aplicaciones ligeras que extraen información de la máquina donde se ejecutan y
la envían a Logstash u otros destinos como Elasticsearch.
Filebeat en particular lee ficheros de log y los envía a Logstash.
De este modo, se desplegaría un Filebeat ligero en cada servidor donde se produzcan logs y un único servidor
Logstash al que se envíen todos los mensajes para su procesamiento y posterior almacenamiento en Elasticsearch.
Otra cuestión interesante es el control de flujo de mensajes hacia Elasticsearch.
Una gran cantidad de logs puede saturar los nodos de Elasticsearch, lo que obligaría a desplegar
una cola de mensajes intermedia que además evitase pérdidas de logs en caso de caídas.
El próximo tutorial de la serie explicará cómo configurar Elasticsearch para mantenerlo en buenas condiciones.


[…] Aunque el marco apropiado para profundizar en Elasticsearch sería un curso completo, en este tutorial se intentará entrar lo máximo posible en las cuestiones más importantes del caso de uso planteado en el primer tutorial de esta serie y que consiste en recoger, almacenar y explotar logs de aplicaciones. Este tutorial ocupa la tercera posición.[…]
Muy buen tutorial! Muchas gracias por hacerlo.
Quería saber cómo hacer para filtrar para generar campos como el nombre del servicio, o id de sesión.
Muchas gracias.