
En este tutorial veremos una pequeña introducción a la gestión de servicios que nos ofrece la herramienta Kubernetes.
Índice de contenidos
- 1. Introducción
- 2. Entorno
- 3. Conceptos básicos
- 4. Instalación de kubernetes
- 5. Operaciones básicas
- 5.1. Pods
- 5.2. Replication Controllers
- 5.2.1 ¿Qué es un replication controller?
- 5.2.2 Creación de un replication controller
- 5.2.3 Trabajando con replication controllers
- 5.3. Services
- 6. Acceder a la interfaz gráfica desde el navegador.
- 7. Conclusiones
- 8. Referencias
1. Introducción
Kubernetes es una herramienta muy potente para manejar los servicios y que nos ofrece a tiro de piedra la experiencia de google a la hora de gestionar múltiples host remotos para el despliegue y mantenimiento de aplicaciones. En este tutorial aprenderemos los conceptos básicos al trabajar con kubernetes así como la exposición de las aplicaciones fuera del cluster.
2. Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro Retina 15′ (2.5 Ghz Intel Core I7, 16GB DDR3).
- Sistema Operativo: Mac OS El Capitán 10.11.2
- Virtual Box
- Vagrant 1.8.1
- Ansible 1.9.3
3. Conceptos básicos
Kubernetes es una plataforma opensource para el automatizar el despliegue, escalado de las aplicaciones, así como las operaciones con los contenedores de aplicaciones. Antes de ponernos manos a la obra, tenemos que tener una serie de conceptos claros:
- Cluster: Conjunto de másquinas físicas o virtuales y otros recursos utilizados por kubernetes.
- Nodo: Una máquina física o virtual ejecutándose en kubernetes donde pods pueden ser programados.
- Pod: Son la unidad más pequeña desplegable que puede ser creada, programada y manejada por kubernetes.
- Replication Controller: Se asegura de que el número específicado de réplicas del pod estén ejecutándose. Permite escalar de forma facil los sistemas y maneja la re-creación de un pod cuando ocurre un fallo.
- Service: Es una abstracción que define un conjunto de pods y la lógica para acceder a los mismos.
4. Instalación de kubernetes
Para realizar la instalación de kubernetes seguiremos el tutorial de instalación de Kubernetes en ubuntu. A partir de este punto entendemos que tienes Kubernetes instalado en una máquina virtual de Ubuntu.
5. Operaciones básicas
A continuación se indican las operaciones básicas que se pueden realizar con Kubernetes como crear y eliminar pods, crear y eliminar replication controllers y gestionar estos con los servicios, exponiéndolos dentro y fuera del cluster.
5.1. Pods
5.1.1 ¿Qué es un pod?
Como hemos definido antes, un pod es la unidad mínima que es manejada por kubernetes. Este pod es un grupo de uno o más contenedores (normalmente de Docker), con almacenamiento compartido entre ellos y las opciones específicas de cada uno para ejecutarlos. Un modelo de pods específico de una aplicación contiene uno o más contenedores que normalmente irían en la misma máquina.
Varios contenedores que pertenezcan al mismo pod son visibles unos de otros vía localhost. Los contenedores que se encuentran en distintos pods no pueden comunicarse de esta manera.
En términos de Docker, un pod es un conjunto de contenedores de Docker con namespace y volúmenes compartidos.
Hay que tener en cuenta que los pods son entidades efímeras. En el ciclo de vida de un pod estos se crean y se les asigna un UID hasta que terminen o se borren. Si un nodo que contiene un pod es eliminado, todos los pods que contenía ese nodo se pierden. Este pod puede ser reemplazado en otro nodo, aunque el UID será diferente. Esto es importante porque un pod no debería de tener información almacenada que pueda ser utilizada después por otro pod en caso de que a este le pasara algo. Para compartir información entre pods están los volúmenes (no hablamos de ellos en este tutorial, pero si tienes curiosidad puedes mirarlo en este enlace).
5.1.2 Usos de un pod
Los pods pueden utilizarse para realizar escalado horizontal, aunque fomentan el trabajo con microservicios puestos en contenedores diferentes para crear un sistema distribuido mucho más robusto. Puedes encontrar más información sobre los patrones utilizados aquí.
5.1.3 Creación de un pod
Los pods se pueden crear de dos maneras: directamente por línea de comandos o a través de un fichero de tipo YAML.
NOTA: Para ejecutar los comandos tal y como se muestran en el tutorial tenemos el comando que contiene el comando kubectl añadido al path. Para realizarlo, solo hay que introducir al final del fichero .bashrc la siguiente línea: «export PATH=$PATH:/opt/kubernetes/cluster/ubuntu/binaries» (teniendo en cuenta que se siga la instalación del tutorial previo).
Para crearlo directamente por línea de comandos ejecutamos lo siguiente:
Creación de replication controller por línea de comandos:
kubectl run my-nginx --image=nginx --port=80
Kubectl es el programa que vamos a utilizar para interactuar con el api de kubernetes.
- El primer parámetro indica la acción, que sirve para arrancar un pod.
- Después el nombre que va a recibir, en este caso my-nginx.
- Luego la imagen a partir de la que se va a construir el pod (la imagens e llama nginx).
- Por último el puerto en el que escucha.
Una vez ejecutado este comando obtendremos:

Lo que estamos viendo por pantalla no es el pod, sino el replication controller que se ha creado que se encarga de gestionarlo (y veremos más adelante). Para ver tanto el pod como el replication controller ejecutamos los siguientes comandos:
kubectl get pods
kubectl get rc
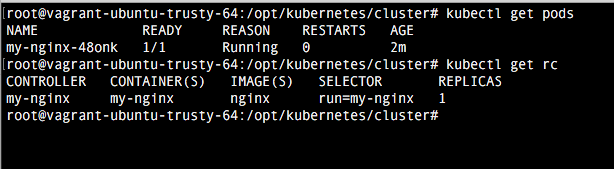
Comprobamos como el nombre del pod es igual al nombre del replication controller nombrado en el comando (my-nginx) seguido de un identificador único para cada pod.
Creación de pod a través de un fichero YAML
Para crearlo directamente por fichero de tipo YAML nos crearemos el archivo nginx-pod.yaml dentro del directorio /opt/kubernetes/example/nginx:
/opt/kubernetes/examples/nginx/nginx-pod.yaml
# Número de versión del api que se quiere utilizar
apiVersion: v1
# Tipo de fichero que se va a crear.
kind: Pod
# Aquí van los datos propios del pod como el nombre y los labels que tiene asociados para seleccionarlo
metadata:
name: my-nginx
# Especificamos que el pod tenga un label con clave "app" y valor "nginx"
labels:
app: nginx
# Contiene la especificación del pod
spec:
# Aquí se nombran los contenedores que forman parte de este pod. Todos estos contenedores serían visibles por localhost
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
# Aquí se define la política de restauració en caso de que el pod se detenga o deje de ejecutarse debido a un fallo interno.
restartPolicy: Always
Antes de ejecutar este pod vamos a eliminar el pod creado anteriormente. para ello usamos el comando:
kubectl delete rc my-nginx
¿Por qué borramos un replication controller en lugar del pod específico? Cuando creas un pod desde línea de comando implícitamente se crea un replication controller que se encarga de restaurar el pod cuando este es borrado ya que su política de restauración por defecto siempre es Always. Por tanto ahora procedemos a crear el mismo pod pero desde el fichero que acabamos de crear:
kubectl create -f /opt/kubernetes/examples/nginx/nginx-pod.yaml
Como estamos creando el pod directamente, vemos como ahora no se crea un replication controller.
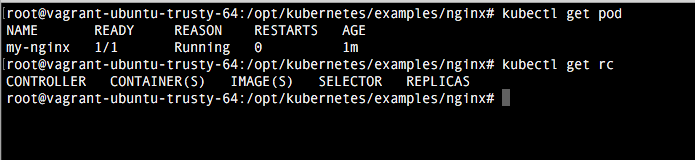
Y ¿qué es un replication controller? vamos a verlo justo a continuación 😀
5.2. Replication Controllers
5.2.1 ¿Qué es un replication controller?
Un replication controller se asegura de que grupo de uno o más pods esté siempre disponible. Si hay muchos pods, eliminará algunos. Si hay pocos, creará nuevos. Por este motivo, se recomienda siempre crear un replication controller aunque solo tengas un único pod (este es el motivo por el cual cuando creamos un pod por comando automáticamente se crea un replication controller para el pod que acabamos de crear). Un replication controller es al fin y al cabo un supervisor de un grupo de uno o más pods a través de un conjunto de nodos.
5.2.2 Creación de un replication controller
A continuación crearemos un replication contorller llamado nginx-rc.yaml en el directorio /opt/kubernetes/examples/nginx a partir de la siguiente plantilla, encargado de levantar un servidor nginx:
/opt/kubernetes/examples/nginx/nginx-rc.yaml
# Número de versión del api que se quiere utilizar
apiVersion: v1
# Tipo de fichero que se va a crear.
kind: ReplicationController
# Datos propios del replication controller
metadata:
# Nombre del Replication Controller
name: my-nginx
# La especificación del estado deseado que queremos que tenga el pod.
spec:
# Número de réplicas que queremos que se encargue de mantener el rc. (Esto creará un pod)
replicas: 1
# En esta propiedad se indican todos los pods que se va a encargar de gestionar este replication controller. En este caso, se va a encargar de todos los que tengan el valor "nginx" en el label "app"
selector:
app: nginx
# Esta propipedad tiene exactamente el mismo esquema interno que un pod , excepto que como está anidado no necesita ni un "apiVersion" ni un "kind"
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
Antes de ejecutar este pod vamos a eliminar el pod creado en el paso anterior. para ello usamos el comando:
kubectl delete pod my-nginx
Ahora creamos el replication controller con el comando:
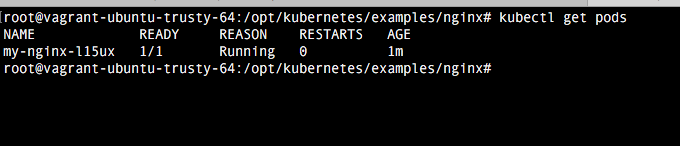
kubectl create -f /opt/kubernetes/examples/nginx/nginx-rc.yaml
Vemos como ahora se nos ha creado un pod con un UID. Para ver para que sirve cada línea del replication controller miramos los comentarios de código.
También podemos comprobar el estado de nuestro replication controller (nombre, número de pods y sus respectivos estados,..) a través del comando:
kubectl describe rc my-nginx
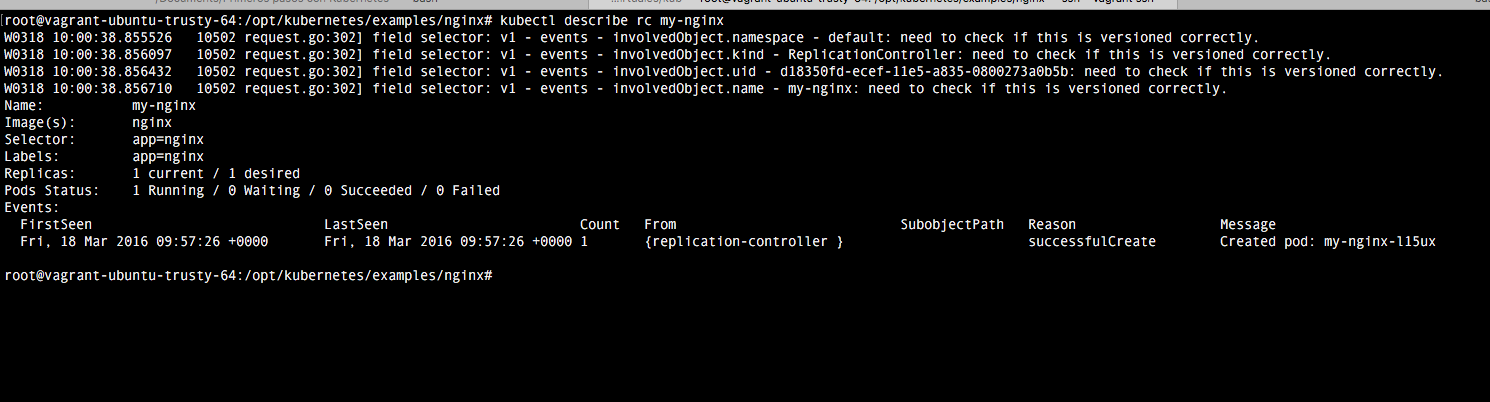
5.2.3 Trabajando con replication controllers
Una vez creado un rc te permite:
- Escalarlo: puedes escoger el número de réplicas que tiene un pod de forma dinámica.
- Borrar el replication controller: puedes borrar solo el replication controller o borrarlo junto a todos los pods de los que se encarga
- Aislar al Pod del replication controller:Los pods pueden no pertenecer a un replication controller cambiando los labels. El pod que ha sido removido de está manera será reemplazado por un pod nuevo, que será creado por le replication controller.
Para añadir un pod que sea controlado por el replication controller ejecutamos:
kubectl scale rc my-nginx --replicas=2
Tras listar el número de pods comprobaríamos como se ha añadido uno nuevo:
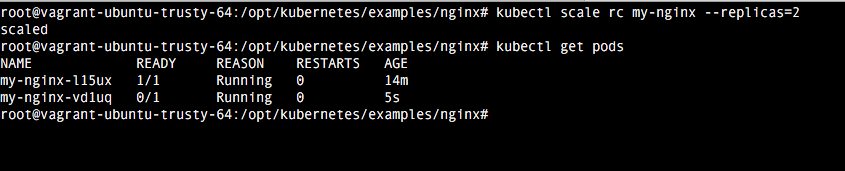
Para borrar un replication controller ejecutaríamos el comando:
kubectl delete rc my-nginx
Si después listamos los pods comprobaremos que han desaparecido todos.
5.3. Services
5.3.1 ¿Qué es un service?
Como ya sabemos, los pods son volátiles. Son creados y destruidos, de forma que no pueden recuperarse. De hecho, los replication controllers son los encargados de manejar su ciclo de vida, y de definir sus políticas de restauración. Como decíamos anteriormente, cada pod tiene su propia dirección IP (que podría incluso no ser constante en el mismo pod a lo largo del tiempo). Esto nos supone un problema en caso de que un pod necesite comunicarse con otro pod. ¿Qué manera tienen de comunicarse ambos, si las ip de cada pod son variables, o si uno de los dos se cae y lo sustituye otro? De esto justo se encargan los services.
Un service es una abstracción que define un grupo lógico de pods y una política de acceso a los mismos. Los pods apuntan a un servicio normalmente por la propiedad label. Pongamos como ejemplo nuestro caso anterior, dónde tenemos un replication controller encargado de ejecutar un pod con un contenedor nginx. Si algo causara la destrucción de este pod, el replication controller crearía uno nuevo con una ip diferente, de forma que el resto de la infraestructura que dependiera de ese pod por esa ip fija dejaría de funcionar. El servicio lo que hace es que ese pod siempre sea accesible de la misma manera, de forma que aunque el pod se destruya o se modifique siempre sea accesible por la abstracción. A continuación crearemos un servicio y también comprobaremos como podemos exponerlo desde fuera del cluster.
5.3.2 Creación de un Service
A continuación vamos a crear un service:
/opt/kubernetes/examples/nginx/nginx-svc.yaml
# Número de versión del api que se quiere utilizar
apiVersion: v1
# Tipo de fichero que se va a crear.
kind: Service
# Aquí van los datos propios del pod como el nombre y los labels que tiene asociados para seleccionarlo
metadata:
name: my-nginx-service
# Contiene la especificación del pod
spec:
# En esta propiedad se indican todos los pods que apuntan a este servkice. En este caso, se va a encargar de todos los que tengan el valor "nginx" en el label "app"
selector:
app: nginx
ports:
# Indica el puerto en el que se debería de servir este servicio
- port: 80
Una vez creado el fichero levantamos el service con el comando:
kubectl create -f /opt/kubernetes/examples/nginx/nginx-svc.yaml
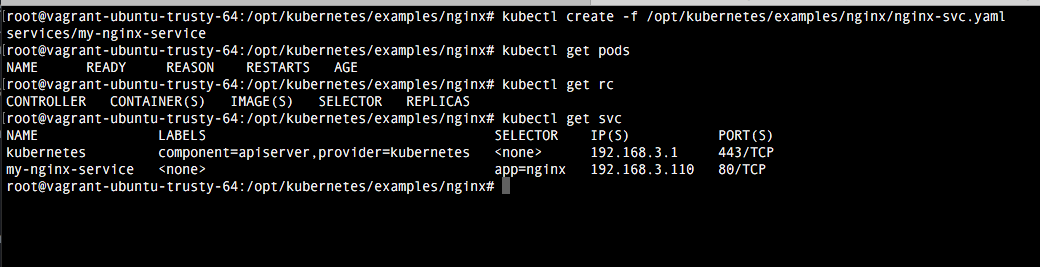
Ahora habilitamos el replication controller de este servicio, que es el que hemos creado anteriormente:
kubectl create -f /opt/kubernetes/examples/nginx/nginx-rc.yaml
Ahora vamos a acceder a la aplicación del pod desde dentro del cluster. Para ello necesitamos saber la ip que tiene actualmente el pod, para lo que usamos el comando:
kubectl get -o template pod my-nginx-m5mni --template={{.status.podIP}}
Ahora accedemos al servicio por medio de esa ip usando el comando curl.
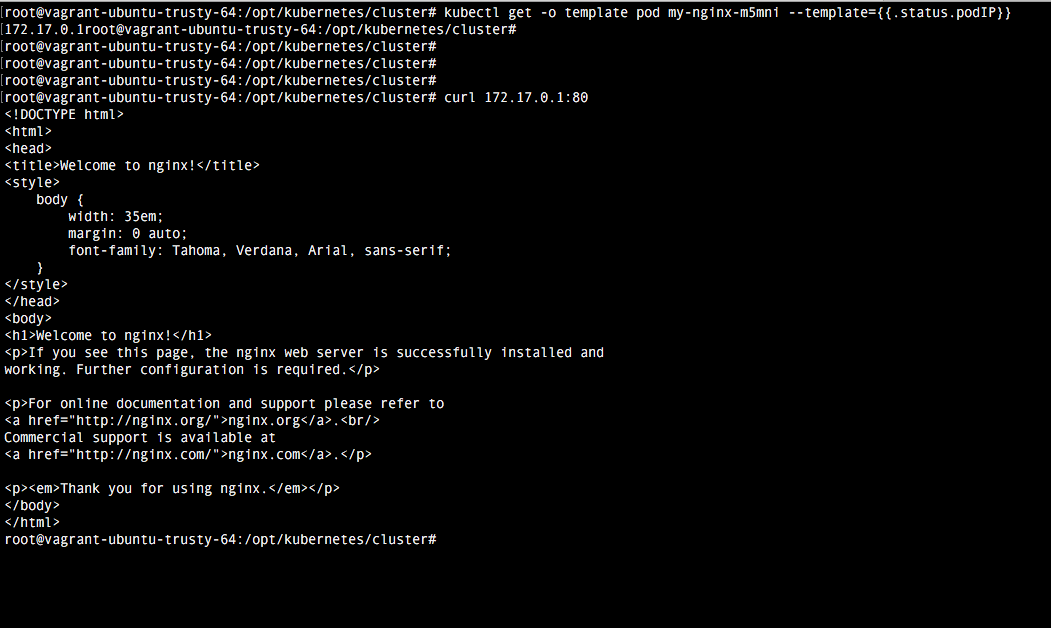
Actualmente este pod solo es accesible dentro del cluster. El service nos sirve para abstraernos del pod en cuestión que estamos utilizando. Este tipo de servicios dentro del cluster se suele utilizar para tener múltiples aplicaciones de un backend detrás del mismo frontend.
5.3.3 Acceder a un servicio desde fuera del cluster
Por último vamos a acceder al servicio desde fuera de cluster, de modo que accederemos al servidor nginx de nuestra máquina virtual desde el navegador. Para ello necesitamos modificar el servicio que estamos utilizando al que le añadimos la propiedad type: NodePort, que lo que hace es exponer el servicio en cada nodo del cluster de forma que serás capaz de contactar con el servicio desde cualquier ip de los nodos. Nuestro servicio qeudaría de la siguiente manera:
/opt/kubernetes/examples/nginx/nginx-svc.yaml
# Número de versión del api que se quiere utilizar
apiVersion: v1
# Tipo de fichero que se va a crear.
kind: Service
# Aquí van los datos propios del pod como el nombre y los labels que tiene asociados para seleccionarlo
metadata:
name: my-nginx-service
# Contiene la especificación del pod
spec:
type: NodePort
# En esta propiedad se indican todos los pods que apuntan a este servkice. En este caso, se va a encargar de todos los que tengan el valor "nginx" en el label "app"
selector:
app: nginx
ports:
# Indica el puerto en el que se debería de servir este servicio
- port: 80
Eliminamos el anterior service y añadimos el nuevo con los comandos que ya sabemos y comprobamos en que puerto externo está mapeeada la conexión:
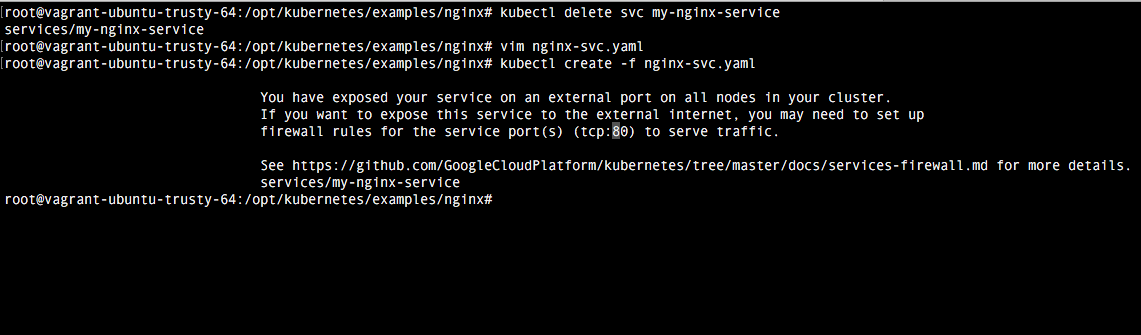
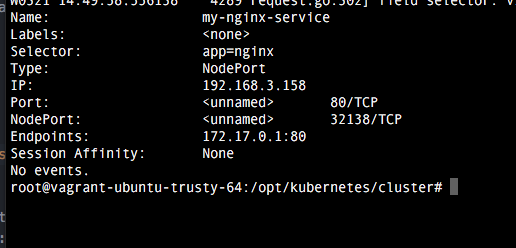
Vemos que tenemos la conexión mapeada en el puerto 32138 (que es el puerto que se elije de forma automática). Ahora tenemos que cambiar la configuración de vagrant para acceder a este puerto desde localhost:
/opt/kubernetes/examples/nginx/nginx-svc.yaml
Vagrant.configure(2) do |config|
config.vm.box = "ubuntu/trusty64"
config.vm.network "forwarded_port", guest: 8080, host: 8080
config.vm.network "forwarded_port", guest: 32138, host: 32138
config.vm.network "private_network", ip: "192.168.90.20"
config.vm.define "prueba" do |prueba|
prueba.vm.provision "ansible" do |ansible|
ansible.verbose = 'vvv'
ansible.playbook = "ansible/infraestructure.yml"
end
end
end
Ahora reiniciamos la máquina virtual para que aplique los nuevos cambios con el comando vagrant reload. Accedemos a la máquina con el comando vagrant ssh y una vez dentro, arrancamos el cluster de kubernetes con el comando:
/opt/kubernetes/examples/nginx/nginx-svc.yaml
cd /opt/kubernetes/cluster KUBERNETES_PROVIDER=ubuntu ./kube-up.sh
NOTA: Esto implica que has seguido el tutorial de instalación de kubernetes en ubuntu para crear un cluster de kubernetes.
Por último accedemos desde el navegador a la url localhost:32138 (tarda un poco en mostrarse debido a la configuración de la máquina virtual, asíque se puede aumentar desde el fichero Vagrantfile)
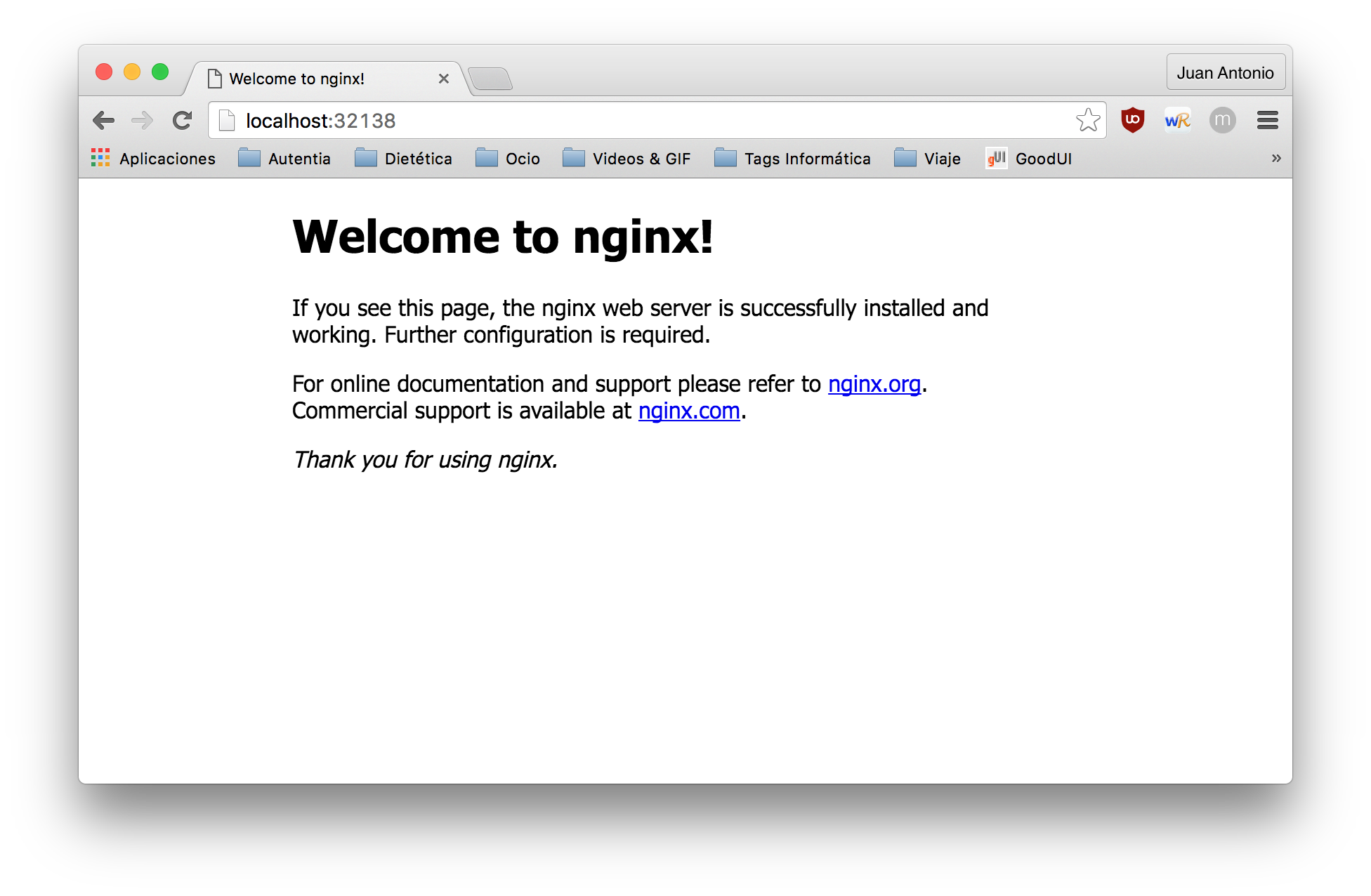
6. Acceder a la interfaz gráfica desde el navegador
Kubernetes cuenta con una serie de add-ons, qué son un conjunto de Services y Replication Controller (con sus correspondientes pods) que son considerados una parte interna del cluster de Kubernetes. Estos add-ons son visibles a través del API. Vamos a habilitar la interfaz que nos ofrece kubernetes: Para ello comenzamos habilitando el namespace kube-system, que viene en el fichero /opt/kubernetes/cluster/ubuntu/namespace.yaml para lo que ejecutamos el comando:
/opt/kubernetes/cluster/ubuntu/namespace.yaml
kubectl create -f /opt/kubernetes/cluster/ubuntu/namespace.yaml
Ahora habilitamos la interfaz gráfica, creando el Replication controller y el Service que vienen en el directorio /opt/kubernetes/cluster/addons/dashboard pero antes de eso, en el servicio exponemos el servicio fuera del cluster como hicimos anteriormente para poder acceder desde el navegador. Para ello simplemente añadimos type: NodePort justo después del spec.
/opt/kubernetes/cluster/addons/dashboard/dashboard-service.yaml
apiVersion: v1
kind: Service
metadata:
name: kubernetes-dashboard
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
kubernetes.io/cluster-service: "true"
spec:
type: NodePort
selector:
k8s-app: kubernetes-dashboard
ports:
- port: 80
targetPort: 9090
Ahora ya estamos listos para levantar la interfaz gráfica, para lo que usamos los siguientes comandos:
shell
kubectl create -f dashboard-controller.yaml kubectl create -f dashboard-service.yaml
Al igual que antes, para poder acceder desde fuera tenemos que mapear el puerto en el fichero de configuración de Vagrant y hacer el comando vagrant reload. ¡Después accedemos por el navegador, y ya tenemos el dashboard preparado!.
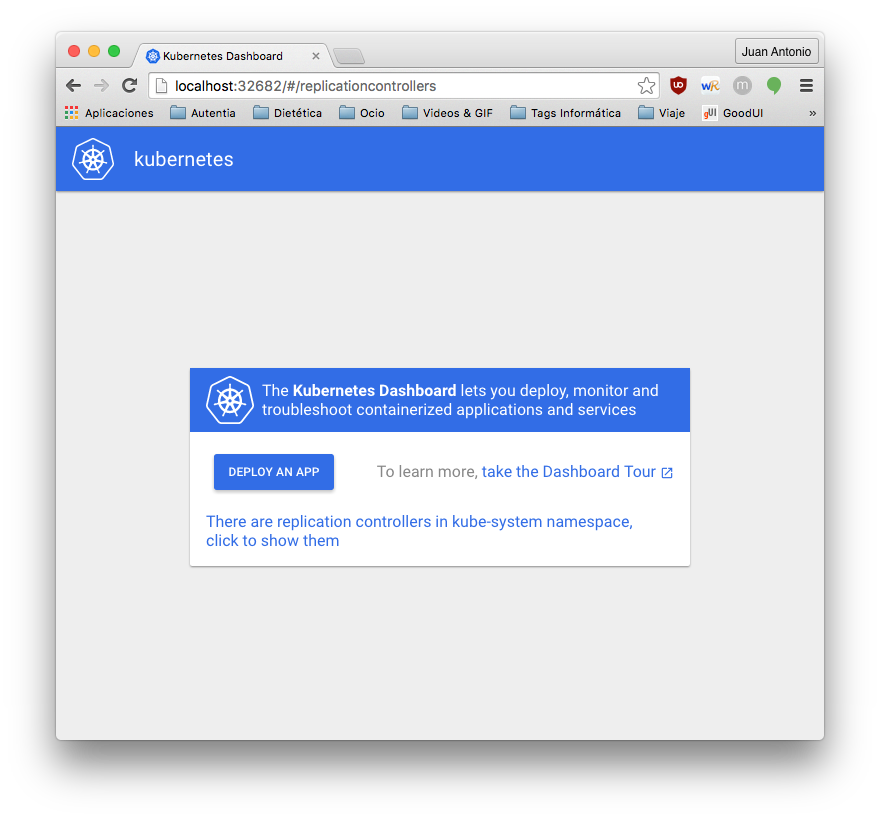
7. Conclusiones
Espero que hayamos cubierto algunas de las características principales de la gestión de kubernetes, así como que seamos capaces de crear nuestros propios pods, replication controllers y services para ser capaces una buena infraestructura que nos permita manejar nuestros servicios de una forma amigable.


Me parece increible que no haya comentarios…
Muy bien explicado. Estaría guay una continuación orquestando varios pods para desarrollo, por ejemplo uno que corra una aplicación que tenga que transpilar javascript y otro que sea el pod que ejecuta nodejs y hace watch sobre un volumen compartido del primer pod para tener siempre el bundle listo con lo cambios.
Muchas gracias por el tutorial, seguid asi
muy buen post!
Gracias
Excelente!!
Muy buen post para comenzar.
GUAUUUUUUUUUUUUUUUUUU. Enorme tutorial. Muchisimas gracias
Excelente tutorial!!
Me parece excelente el tutorial.
Es muy bien explicado y sobre todo en español ya qué es una herramienta relativamente nueva y la mayoría de los tutoriales que he encontrado están en inglés.
Excelente ejemplo y super bien explicado. Tengo la siguiente duda, kubernetes te asigno el puerto 32138 en forma aleatoria. Hay alguna forma de fijar para que sea un puerto en particular?
Muy buen tutoria, esta excelentel! deberías hacer otro manejando desde otro sistemas operativos, desde windows, Mac, Centos, etc.
[…] Para aprender un poco de Kubernetes podéis seguir este tutorial. Para aprender un poco de Apache Spark podéis seguir este otro […]
Post como este dan gusto. Todo muy bien explicado, bien ordenand y profundizando en los conceptos.