
En este tutorial intentaremos explicar qué es el principio de idempotencia aplicado a verbos HTTP, por qué es importante respetarlo y los beneficios esperados.
0. Índice de contenidos.
- 1. Introducción.
- 2. Entorno.
- 3. ¿Qué es el principio de idempotencia?.
- 4. ¿Por qué idempotencia?.
- 5. Los recursos «virtuales».
- 6. Referencias.
- 7. Conclusiones.
1. Introducción
Ya comentamos en anteriores tutoriales la importancia del diseño de nuestras APIs REST para que sigan los principios de la web y no se conviertan en simples interfaces sobre HTTP. En este tutorial volvemos a incidir en las buenas prácticas de diseño de APIs REST, esta vez explicando el principio de idempotencia de los verbos HTTP. ¿Te has preguntado alguna vez en qué nivel se encuentra tu API en la famosa escala de Richardson?
En este tutorial intentaremos explicar qué es el principio de idempotencia aplicado a verbos HTTP, por qué es importante implementar dicho principio y los beneficios esperados.
2. Entorno.
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro Retina 15′ (2.2 Ghz Intel Core I7, 16GB DDR3).
- Sistema Operativo: Mac OS Yosemite 10.10
- Entorno de desarrollo: NetBeans IDE 8.0.2
- JDK 1.8
- Apache Tomcat 8.0.21
- Maven 3.1.1
- Spring 4.1.6.RELEASE
- H2 database 1.3.170
3. ¿Qué es el principio de idempotencia?.
El principio de idempotencia aplicado a REST (realmente es a los verbos HTTP) nos dice que, la ejecución repetida de una petición con los mismos parámetros sobre un mismo recurso tendrá el mismo efecto en el estado de nuestro recurso en el sistema si se ejecuta 1 o N veces. ¿¡¿¡Cooooooooomo?!?!?!!?, vamos a verlo gráficamente para comprenderlo mejor 🙂
Imaginemos la ejecución repetida de una petición utilizando un verbo NO idempotente con los mismos datos de entrada sobre un mismo recurso.
Paso 1: Enviamos una petición de creación de un recurso con unos parámetros. Y el estado en el sistema se modifica, concretamente se crea un nuevo pedido en base de datos.
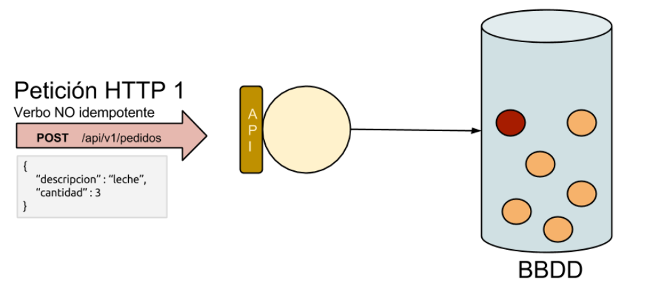
Paso 2: Volvemos a enviar la misma petición de creación al mismo recurso con los mismos parámetros. Observamos que el estado del sistema vuelve a cambiar, se crea otro recurso nuevo.
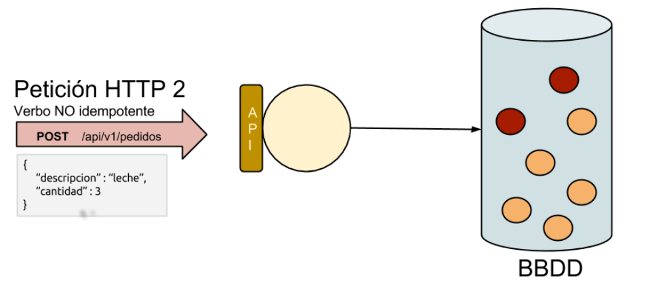
Paso 3: Nuevamente enviamos la misma petición de creación al mismo recurso con los mismos parámetros. Y se a crear otro recurso nuevo.
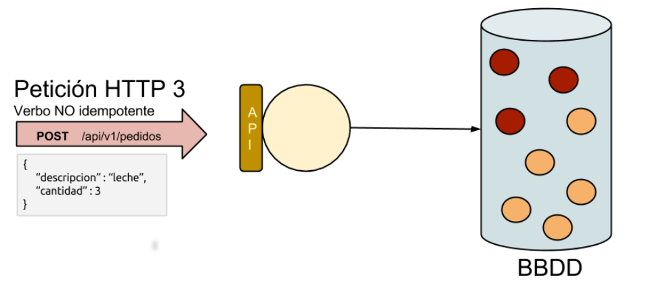
Acabamos de ver el comportamiento esperado de aplicar un verbo NO idempotente sobre un recurso, el estado del sistema cambia siempre aunque se apliquen los mismos parámetros al mismo recurso.
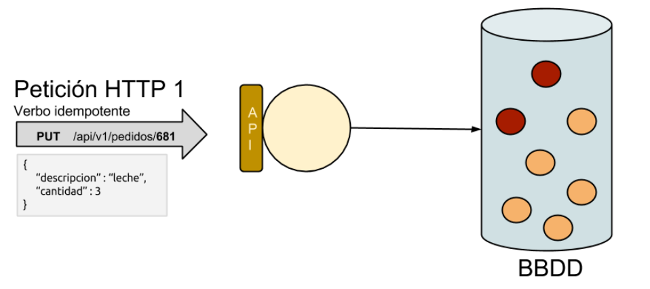
Paso 1: Veamos el comportamiento esperado de un verbo idempotente. Enviamos una petición de creación/actualización sobre un recurso con unos determinados parámetros. Y se crea un nuevo recurso en el sistema en caso de no existir o se modifica, en caso de que algo haya cambiado, el existente.
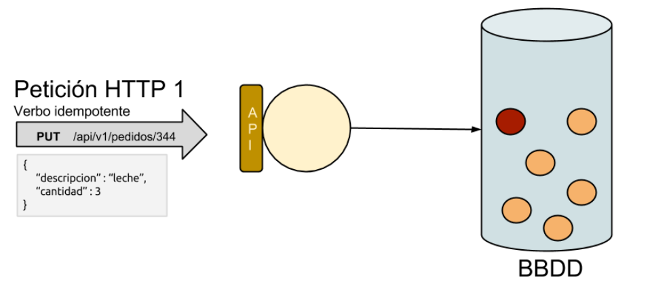
Paso 2: Repetimos la petición con el mismo verbo idempotente con los mismos parámetros y sobre el mismo recurso. Al ser una acualización el estado del sistema se mantiene igual, no se crea un recurso nuevo y el valor de las propiedades el recurso es el mismo que cuando se terminó la primera petición.
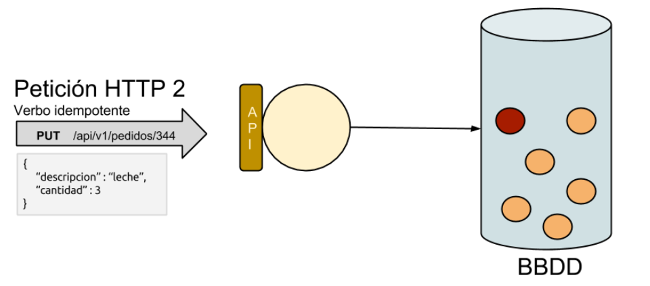
Paso 3: Repetimos N veces la petición y el estado sigue siendo el mismo.

Paso 4: Si cambiamos algo, por ejemplo el recurso al que atacamos utilizando los mismos parámetros y mismo verbo idempotente si que se producirían cambios en el sistema, ya que la petición es contra un nuevo recurso. En este caso se crearía/actualizaría otro recurso
Nótese que es MUY IMPORTANTE tener en cuenta que este comportamiento no se produce por «arte de magia» por el simple hecho de utilizar un verbo idempotente. Es necesario implementar la idempotencia en nuestro servicio.
La respuesta del servidor puede cambiar según el número de petición. Por ejemplo, si es una petición de creación/actualización de un recurso, si dicho recurso no existiese, la primera vez que realizamos la petición el servidor nos podría devolver un código 201 (CREATED) y las siguientes veces podría devolver 200 o 204.
Aquí podemos ver un listado de los verbos HTTP más comunmente utilizados donde se indica si son o no idempotentes.

4. ¿Por qué idempotencia?.
Pueden existir determinadas ocasiones en las que, debido a congestiones de la red, el consumidor de un API no reciba una respuesta del servidor acerca del resultado del procesamiento de la petición (salta un timeout). En ese caso, ¿qué hacemos?, ¿repetimos nuevamente la petición?, ¿continuamos como si no hubiese pasado nada?.
Con HTTP, a diferencia (por ejemplo) de JMS, no tenemos garantía de entrega de nuestras peticiones al servidor, por lo que nada nos asegura que una petición que enviamos, y donde se genera un error por timeout, haya llegado y se haya procesado correctamente.
El caso más típico es cuando queremos dar de alta un nuevo recurso en el sistema. Por ejemplo, una orden de compra que realiza un cliente. Imaginemos que al dar de alta dicha petición en el sistema no obtenemos respuesta del servidor. Supongamos que reintentamos la petición y el servidor nos responde que todo está correcto. Si las dos peticiones se hubiesen hecho de una manera NO idempotente, es probable que la primera petición sí que hubiese llegado al servidor y se hubiese procesado por lo que tendríamos dos órdenes de compra de un mismo cliente. Como el sistema en la segunda petición nos devolvió que todo estaba correcto, nosotros pensamos que se ha creado la orden una única vez, pero realmente existen dos órdenes de compra para el cliente, cuando sólo queríamos dar de alta una.
Si dichos reintentos se hubiesen ejecutado de una manera IDEMPOTENTE podemos realizar tantos reintentos como necesitemos (mismo recurso y mismos parámetros) teniendo la garantía de que cuando el servidor nos responda la primera vez que todo esta correcto, tendremos nuestro recurso creado una única vez.
Por tanto, el gran beneficio que obtenemos de la idempotencia es la capacidad de realizar tantos reintentos como necesitemos teniendo la certeza de que el estado del sistema será el que deseabamos cuando realizamos la primera petición.
5. Los recursos «virtuales».
Siguiendo con el problema de la creación de recursos en el servidor que se den de alta una única vez por muchos reintentos que hagamos vemos que aparece un gran inconveniente. Si nos fijamos qué verbos HTTP son idempotentes vemos que está PUT pero no POST.
La gran ventaja que obtenemos con POST sobre PUT es que realizamos la petición sobre un recurso padre (ejemplo: una colección) para crear un recurso hijo como podría ser una entidad dentro de dicho recurso. Hablando claro, delegamos la generación del identificador del nuevo recurso que se va a crear en el servidor. Veamos un ejemplo:
URL: http://miservidor:puerto/api/v1/pedidos
Method: POST
Headers:
Accept: application/json
Content-Type: application/json
Body:
{
"voucher" : "358AFD",
"price" : 33.78,
"status" : 1
}
Si nos fijamos, la petición la enviamos contra la URL http://miservidor:puerto/api/v1/pedidos que es la colección de la que colgará el recurso que queremos crear. Una posible respuesta podría ser:
URL: http://miservidor:puerto/api/v1/pedidos
Status: 201 CREATED
Headers:
Location: http://miservidor:puerto/api/v1/pedidos/5743896
Content-Type: application/json
Body:
{
"id" : 5743896,
"voucher" : "358AFD",
"price" : 33.78,
"status" : 1
}
Como vemos, en la respuesta el servidor nos devolverá el nuevo identificador del recurso (campo id en la respuesta) y, lo más importante, la URL que identifica de manera única al recurso recién creado. El servidor es el que tiene el conocimiento para crear el identificador de un nuevo recurso.
PUT, sin embargo, suele actuar sobre un recurso concreto y no sobre un recurso padre. Por tanto, si quisiésemos utilizar PUT para crear un nuevo recurso, el cliente debería saber el identificador del mismo, por lo que quedaría en manos del cliente la responsabilidad de crear dicho identificador, cosa MUY POCO recomendable.
Entonces, si queremos utilizar idempotencia para crear recursos concretos, ¿qué hacemos?. Pues utilizar recursos «virtuales». La técnica de recursos «virtuales» consiste en realizar una primera petición al servidor mediante POST para que cree un identificador válido para un nuevo recurso que se va a crear. Sin embargo, en el servidor no se ha creado ningún recurso, únicamente se genera un identificador válido para un posible nuevo recurso.
Seguidamente, si todo ha ido bien, al contar con una URL que identificará de manera única a un posible nuevo recurso, ya podemos utilizar idempotencia (peticiones PUT) contra ese recurso que todavía no existe.
Sería algo así:
URL: http://miservidor:puerto/api/v1/pedidos Method: POST Headers: Body:
Si todo ha ido bien el servidor respondería algo como:
URL: http://miservidor:puerto/api/v1/pedidos Status: 201 CREATED Headers: Location: http://miservidor:puerto/api/v1/pedidos/5743896 Body:
Con lo que ya tendríamos una URL sobre la que hacer las peticiones PUT (idempotentes) sobre un recurso con un identificador válido. Dicho recurso no existe hasta que hagamos un PUT con los datos del recurso y el servidor nos devuelva una respuesta correcta:
URL: http://miservidor:puerto/api/v1/pedidos/5743896
Method: PUT
Headers:
Accept: application/json
Content-Type: application/json
Body:
{
"voucher" : "358AFD",
"price" : 33.78,
"status" : 1
}
Representado gráficamente sería algo así:
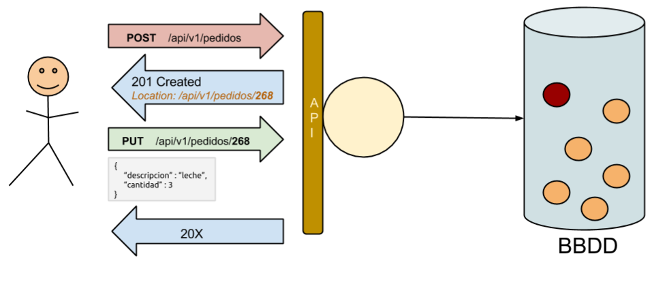
En el caso de que la primera petición fallase (timeout) no pasaría nada. Aunque dicha petición no es idempotente (POST) podemos reenviar al servidor la petición tantas veces como queramos hasta que nos devuelva un identificador válido ya que no se están creando recursos en el servidor, únicamente generamos identificadores.
Seguidamente, ya tenemos una URL de un posible recurso a crear. Finalizamos el proceso con una petición idempotente PUT con la que crearemos/actualizaremos dicho recurso.
Aquí os dejo un EJEMPLO con Java y SpringMVC donde se puede apreciar cómo implementar del lado del servidor un servicio con verbos idempotentes (recurso Users) además de un ejemplo con recursos virtuales (recurso Orders).
6. Referencias.
- Código fuente de ejemplo de idempotencia y uso de recursos virtuales
- Buenísimo: La idempotencia en vacas y APIs REST (inglés)
7. Conclusiones.
En este tutorial hemos visto el principio de idempotencia aplicada a verbos HTTP. A la hora de diseñar nuestras APIs REST sobre HTTP es muy importante tener en cuenta las diferentes características de los verbos como pueden ser la seguridad o la propia idempotencia.
La gran ventaja de la idempotencia es que podemos reintentar una petición contra el servidor tantas veces como necesitemos hasta que tengamos la certeza de que el estado de nuestro recurso en el sistema está justo como nosotros queríamos. Esto adquiere especial importancia en operaciones de creación de recursos donde necesitamos garantizar que ese recurso se creará una única vez en el servidor y donde queremos contar con una política de reintentos en caso de que no obtengamos respuesta del servidor.
Espero que este tutorial os haya sido de ayuda. Un saludo.
Miguel Arlandy
Twitter: @m_arlandy


Buenísimo tutorial, me ha quedado bastante claro la verdad.
un saludo.
Buenas, tengo varias preguntas, espero que me puedan ayudar.
Con respecto a los recursos virtuales y la idempotencia, esta práctica debería seguirse en el desarrollo de toda api rest?
Ahora, con los recursos virtuales, entonces la responsabilidad de generar el id se le daría a otra tabla, y por ende, significaría que la tabla de la entidad principal ya no tendría la propiedad de auto increment?
Y esta última pregunta que no tiene que ver con el tema.
Por qué al generar un id lo concatenas con un hash generado por el id? Me imagino que tiene que ver con la seguridad de la api, pero me gustaría saber un poco más al respecto.
De antemano, muchas gracias.
Buena pregunta Alfonso, a mí me quedo la misma duda, voy a buscar que encuentro sobre el tema.
Hola Alfonso, me corrigen si estoy equivocado pero a mi forma de ver la solución a la pregunta «con los recursos virtuales, entonces la responsabilidad de generar el id se le daría a otra tabla, y por ende, significaría que la tabla de la entidad principal ya no tendría la propiedad de auto increment?» yo la solucionaría a partir de otra alternativa que en base de datos se llaman «secuencias» ya sea incrementando su valor a través de un ORM o manualmente haciendo uso de las funciones CURRVAL and NEXTVAL (Para el caso de una base de datos Oracle) o las funciones de incremento que provea otro motor de base de datos. De hecho en el código fuente compartido en este blog muestra la estratégia empleada a partir de la generación de un identificador muy básico md5 que ejemplifica su uso. ¿Miguel Aralndy o cualquier colaborador de Adictos al trabajo puede revisar algunos links que no funcionan? se le agradecerá y me quiero manifestar que me pareció muy educativo y aclaratorio el contenido de este tema. Felicitaciones.
Hola, Gustavo. Hemos revisado todos los enlaces del tutorial y funcionan correctamente. ¿A cuáles te refieres?
Buen tutorial gracias por toda la info 🙂
no ma muy bien saludos ojala hgas mas tutoriales como estos
Excelente artículo…
Sublime
buen tuto, pero por que la segunda petición no podría ser también un post si yo mismo tengo que implementar la idempotencia dentro de mi servidor ?