
Primeros pasos de MapReduce con Hadoop
0. Índice de contenidos.
- 1. Introducción.
- 2. Entorno.
- 3. Configuración del proyecto.
- 4. Análisis de DataSet.
- 5. Mapper.
- 6. Reducer.
- 7. Driver.
- 8. Conclusiones.
1. Introducción.
Una vez visto el tutorial de primeros pasos con Hadoop, instalación y configuración, muchos se dirán: «pues muy bonito, ¿y esto para qué vale?». Como dijimos en el anterior tutorial, principalmente para realizar tareas distribuidas sobre grandes ficheros de datos utilizando el paradigma MapReduce. En este tutorial vamos a ponernos manos a la obra realizando un ejemplo simple de un algoritmo MapReduce con el API de Hadoop.
Como aquí lo importante son los datos y dado que el clásico wordcount (el holamundo de MapReduce) está muy visto, he buscado un dataset que pueda darme un poco más de miga para sacar un poco de jugo a los datos.
Por suerte, aunque queda mucho camino por recorrer, nuestras administraciones van publicando lo que se conoce como open data o datos abiertos poniendo a disposición del que quiera y de forma libre datos relativos a censos, información económica, laboral, sectorial, mediciones medioambientales, datos estadísticos de consumo, transportes, etc. A mí me ha parecido interesante un dataset sobre la medición de la calidad del aire en Castilla y León desde 1997 que he sacado de la página datosabiertos.jcyl.es . Vamos a ver con Hadoop cómo extraer información relevante de un fichero que contiene más de 150.000 líneas.
Puedes descargarte el código del tutorial desde mi repositorio de github pinchando aquí.
2. Entorno.
El tutorial se ha realizado con el siguiente entorno:
- Ubuntu 12.04 64 bits
- Oracle Java SDK 1.6.0_27
- Apache Hadoop 2.2.0
- Apache Maven 3.1.1
3. Configuración del proyecto
Lo primero que haremos será crear un proyecto Maven y añadir al pom.xml las dependencias necesarias para trabajar.
4.0.0
com.autentia.tutoriales
mapreduce-basico
0.0.1-SNAPSHOT
jar
UTF-8
1.6
org.apache.maven.plugins
maven-compiler-plugin
${project.encoding}
${java.version}
${java.verion}
org.apache.hadoop
hadoop-common
2.2.0
org.apache.hadoop
hadoop-client
2.2.0
4. Análisis del DataSet
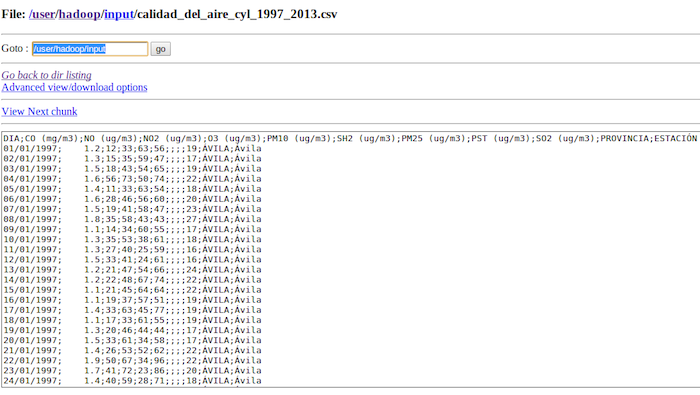
Antes de implementar ni una línea de código debemos pararnos a analizar lo que pretendemos extraer del fichero de datos. Si abrimos el fichero CSV que nos hemos descargado esto es lo que nos aparece.
DIA;CO(mg/m3);NO(ug/m3);NO2(ug/m3);O3(ug/m3);PM10(ug/m3);SH2(ug/m3);PM25(ug/m3);PST(ug/m3);SO2(ug/m3);PROVINCIA;ESTACION 01/01/1997;1.2;12;33;63;56;;;;19;ÁVILA;Ávila 02/01/1997;1.3;15;35;59;47;;;;17;ÁVILA;Ávila 03/01/1997;1.5;18;43;54;65;;;;19;ÁVILA;Ávila 04/01/1997;1.6;56;73;50;74;;;;22;ÁVILA;Ávila 05/01/1997;1.4;11;33;63;54;;;;18;ÁVILA;Ávila 06/01/1997;1.6;28;46;56;60;;;;20;ÁVILA;Ávila 07/01/1997;1.5;19;41;58;47;;;;23;ÁVILA;Ávila 08/01/1997;1.8;35;58;43;43;;;;27;ÁVILA;Ávila 09/01/1997;1.1;14;34;60;55;;;;17;ÁVILA;Ávila 10/01/1997;1.3;35;53;38;61;;;;18;ÁVILA;Ávila 11/01/1997;1.3;27;40;25;59;;;;16;ÁVILA;Ávila 12/01/1997;1.5;33;41;24;61;;;;16;ÁVILA;Ávila .... 09/09/1997;No cumple el anexo IV de la Decisión del Consejo 97/101/CE;25;62;48;56;;;;17;áVILA;ávila ....
Como se puede ver, el fichero tiene una línea por cada día de medición de diferentes medidas relativas a diferentes contaminantes como son el monóxido de carbono, monóxido de nitrógeno, dióxido de nitrógeno, ozono, etc… por provincia y población donde se encuentra la estación donde se ha tomado la medida.
Para hacer una primera prueba sencilla con el API de Hadoop vamos a calcular la media de las muestras tomadas desde 1997 de Monóxido de Carbono (CO) agrupados por provincia. Este sería un cálculo que aporta valor, podemos saber qué provincia de Castilla y León tiene un menor nivel de presencia de esta sustancia. Sin ser ningún entendido en química la he escogido por ser una sustancia que se desprende al quemar gasolina, petróleo, carbón, etc. y que representan un problema por estar presentes en el aire que respiramos.
El ranking final de las provincias menos contaminadas que resulte del cálculo que vamos a realizar, no se debe tomar como un estudio serio para determinar la calidad del aire presente en ellas ya que se ha decidido tomar este indicador como podría haber sido cualquier otro. Imagino que el cálculo para medir en conjunto la calidad del aire de una provincia debe ser mucho más complejo pero queda fuera del ámbito de este tutorial.
5. Mapper
Dentro del paradigma MapReduce, en la tarea mapper se reciben los bloques de datos que contienen la información. Es aquí donde debemos extraer la información que nos irá llegando línea a línea. Nuestra clase AirQualityMapper extenderá de la clase Mapper definiendo los formatos de entrada de la clave y valor y los tipos de salida que devolverá la función. La salida del mapper será la entrada del reducer. En nuestro caso el valor de la clave contendrá el offset del fichero es decir el puntero que va recorriendo el fichero entero y extrae cada una de las líneas del mismo. La línea nos la pasará en el campo value. Al heredar de Mapper debemos implementar el método map cuyos parámetros de entrada corresponderán con los tipos genéricos la que definimos anteriormente.
El método map es muy sencillo, considerando que en el campo value tenemos una línea del fichero de entrada, la troceamos separando por el token «;». Nos quedaremos con los valores que nos interesan, para nuestro análisis nos quedamos con el valor correspondiente al Monóxido de Carbono (CO) y con la provincia.
Aparte de la tarea de extracción del dato, el mapper también realiza la tarea de filtrado, en nuestro caso no emitimos ningún valor que no sea numérico. Hacemos esto porque hay líneas que no tienen todas las medidas bien informadas supongo que porque ese día la muestra tomada no es fiable de acuerdo a las directiva que regula la medición.
Una parte muy importante en la fase de map es la información que devuelve el propio método, como es lógico. Esto se realiza escribiendo en el objeto context siempre una tupla compuesta por una clave y un valor. La clave será la provincia y como valor el dato relativo a la medición de Monóxido de Carbono (CO). Los tipos que se escriben en el context son del tipo Writable. Es un tipo de datos específico en Hadoop ya que por temas de rendimiento redefine los tipos de Java, por ejemplo si la clave es de tipo string tenemos que crear un tipo Text, si el valor es de tipo Double, debemos crear un DoubleWritable. También podremos crear nuestros propios Writables para trabajar con objetos compuestos. Esto lo veremos en próximos tutoriales.
El código del mapper quedaría así:
public static class AirQualityMapper extends Mapper<Object, Text, Text, DoubleWritable> {
private static final String SEPARATOR = ";";
/**
* DIA; CO (mg/m3);NO (ug/m3);NO2 (ug/m3);O3 (ug/m3);PM10 (ug/m3);SH2 (ug/m3);PM25 (ug/m3);PST (ug/m3);SO2 (ug/m3);PROVINCIA;ESTACIóN
* 01/01/1997; 1.2; 12; 33; 63; 56; ; ; ; 19 ;áVILA ;ávila
*/
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
final String[] values = value.toString().split(SEPARATOR);
// final String date = format(values[0]);
final String co = format(values[1]);
// final String no = format(values[2]);
// final String no2 = format(values[3]);
// final String o3 = format(values[4]);
// final String pm10 = format(values[5]);
// final String sh2 = format(values[6]);
// final String pm25 = format(values[7]);
// final String pst = format(values[8]);
// final String so2 = format(values[9]);
final String province = format(values[10]);
// final String station = format(values[11]);
if (NumberUtils.isNumber(co.toString())) {
context.write(new Text(province), new DoubleWritable(NumberUtils.toDouble(co)));
}
}
private String format(String value) {
return value.trim();
}
}
6. Reducer
El reducer es la parte del algoritmo que recoge agrupadas por clave todos los valores emitidos en la fase map. En nuestro caso a la tarea reduce le llegará algo como (ÁVILA, [1.2, 1.3, 1.5, 1.6, 1.4…]). En esta fase debemos realizar la operación que calcule la media de los valores recibidos para la provincia.
De forma muy parecida al map, en este caso extendemos de Reducer y definimos los valores de entrada y de salida del método reduce que debemos implementar obligatoriamente. Los valores de entrada deben coincidir con los valores de salida de la función map. La salida del reduce será de tipo texto resultando la tupla que contendrá la provincia y el valor medio de las muestras tomadas de Monóxido de Carbono (CO) desde 1997.
Recorremos con un bucle for el iterable que Hadoop nos pasa con los valores de las muestras tomadas. En el campo key vendrá la provincia. Si existen medidas para la provincia se emitirá el resultado escribiendo en el objeto context. De forma similar al map, se escribe siempre una tupla key/value. En nuestro caso la provincia y la media obtenida redondeando en 2 decimales.
public static class AirQualityReducer extends Reducer<Text, DoubleWritable, Text, Text> {
private final DecimalFormat decimalFormat = new DecimalFormat("#.##");
public void reduce(Text key, Iterable<DoubleWritable> coValues, Context context) throws IOException, InterruptedException {
int measures = 0;
double totalCo = 0.0f;
for (DoubleWritable coValue : coValues) {
totalCo += coValue.get();
measures++;
}
if (measures > 0) {
context.write(key, new Text(decimalFormat.format(totalCo / measures)));
}
}
}
7. Driver
Pues ahora que ya tenemos todo, sólo nos faltaría ejecutarlo. Para eso nos creamos una función Driver que no es más que un método main que creará un Job configurando todo lo necesario para ejecutar la tarea: función map, función reduce, tipos de datos que manejan, entrada y salida de datos, etc. Utilizaremos también la clase ToolRunner de Hadoop, una utilidad que se encarga de pasar en la invocación por línea de comandos de nuestra clase Driver una serie de parámetros de configuración que le pasemos.
El resultado final (eliminando código repetido) quedaría así:
package com.autentia.tutoriales;
//imports ...
public class AirQualityManager extends Configured implements Tool {
/** Map */
public static class AirQualityMapper extends Mapper<Object, Text, Text, DoubleWritable> {
private static final String SEPARATOR = ";";
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
...
}
}
/** Reduce */
public static class AirQualityReducer extends Reducer<Text, DoubleWritable, Text, Text> {
public void reduce(Text key, Iterable<DoubleWritable> coValues, Context context) throws IOException, InterruptedException {
...
}
}
@Override
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("AirQualityManager required params: {input file} {output dir}");
System.exit(-1);
}
deleteOutputFileIfExists(args);
final Job job = new Job(getConf());
job.setJarByClass(AirQualityManager.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapperClass(AirQualityMapper.class);
job.setReducerClass(AirQualityReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
return 0;
}
private void deleteOutputFileIfExists(String[] args) throws IOException {
final Path output = new Path(args[1]);
FileSystem.get(output.toUri(), getConf()).delete(output, true);
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new AirQualityManager(), args);
}
}
Creamos la clase AirQualityManager que para poder invocarse a través de ToolRunner debe extender de Configured e implementar el interfaz Tool. Define el método main que servirá de punto de entrada a nuestra función. En el main invocamos al ToolRunner creando una instancia de nuestra clase manager pasándole los argumentos que recogemos por línea de comandos.
Esto llamará a nuestro método run que valida los datos recibidos como entrada ya que es necesario introducir el fichero que contiene los datos y también el directorio de salida donde se escribirá el resultado. A continuación borra el directorio si ya existe (Hadoop da un error si ya está creado) y crea un nuevo Job pasándole la configuración recogida por línea de comandos si la hubiera. Al job hay que configurarle una serie de parámetros como son el formato de entrada y salida, en nuestro caso una entrada de texto línea a línea, el mapper y el reducer, los tipos de datos que se manejan, los ficheros de entrada y el directorio de salida. Invocamos y esperamos mediante la llamada al método waitForCompletion. El valor true indica el modo verbose.
Ya sólo queda ejecutar y esperar el resultado. Para ello antes debemos crear el directorio y subir al HDFS el fichero que contiene los datos mediante el comando:
$ hadoop fs -mkdir input $ hadoop fs -put input/calidad_del_aire_cyl_1997_2013.csv input
Podemos comprobar si se ha subido bien mediante el comando:
$ hadoop fs -ls input
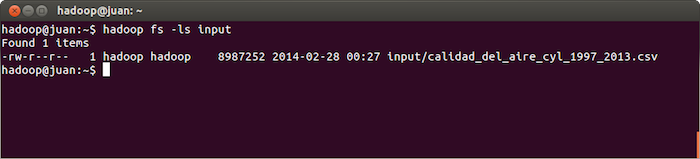
O también desde la url http://localhost:50075 donde se ve la información del NameNode y del filesystem de HDFS.
El siguiente paso será generar un jar que será la forma de pasarle a Hadoop el código que tiene que ejecutar. Para ello usamos maven haciendo un mvn package. Una vez hecho esto ejecutamos el siguiente comando para lanzar el Job.
$ hadoop jar target/mapreduce-basico-0.0.1-SNAPSHOT.jar
com.autentia.tutoriales.AirQualityManager
input/calidad_del_aire_cyl_1997_2013.csv
output
Después de unos pocos segundos nos dejará el resultado en el directorio output. Lo abrimos y tendremos el resultado del cálculo de la media de Monóxido de Carbono (CO) por provincia.
BURGOS 0.86 LEÓN 0.98 PALENCIA 1.18 SALAMANCA 1.39 SEGOVIA 1.02 SORIA 0.18 VALLADOLID 0.69 ZAMORA 0.84 ÁVILA 0.96
Enhorabuena a los sorianos por tener un aire tan limpio 🙂
8. Conclusiones.
En este tutorial hemos visto lo sencillo que resulta crear un Job en Hadoop y extraer información de un fichero que a simple vista no nos dice gran cosa a menos que se procese. El fichero con el que hemos trabajado era pequeño, unas 150.000 líneas (9 MB). Imaginad ficheros de cientos de millones de líneas, quizá la tarea no tardaría unos segundos en terminar sino horas o días por lo que ya tendríamos todo montado para distribuir nuestra tarea en un cluster que redujera los tiempos de proceso.
En próximos tutoriales complicaremos un poco más el problema y explotaremos un poquito más la información de la que disponemos.
Puedes descargarte el código del tutorial desde mi repositorio de github pinchando aquí.
Espero que te haya sido de ayuda.
Un saludo.
Juan


Me ha gustado el tutorial Juan, bien hecho, tienes un seguidor en github 🙂
Excelente tutorial, para que lo entienda un lerder como yo es significa que esta muy bien. Como pegas, deberia de venir la fecha del tutorial arriba porque ya sabemos como evoluciona estas tecnologias y en 2 años ya el tema queda desfasado por lo que deberiamos saberlos.
En el tutorial viene que en proximos tutoriales nos contaran más pero no hay links a los siguientes tutoriales. ¿como lo busco? deberian de poner links de tutoriales relacionados.
Gracias por su aportacion a la comunidad. son excelentes
Hola amigo, soy muy nuevo en esto. Me pdrias hacer el favor de explicar los parametros que estan en Mapper
en esta linea:
public static class AirQualityMapper extends Mapper
y tambien en esta:
public static class AirQualityReducer extends Reducer
GRACIAS.
Hola Alonso,
Estoy empezando con esto de Hadoop y quería preguntarte algo relativo a Java, sin saber casi nada de esto.
Solo para ver como funciona Hadoop con tu ejemplo: ¿cómo puedo hacer para compilar el .java, obtener el .class y de ahí el .jar sin maven, es decir, directamente en mi linux con javac. Me da un monton de errores de libreria.
Gracias.