
0. Índice de contenidos.
- 1. Entorno.
- 2. Introducción.
- 3. Descargar el software.
- 4. Preparación del entorno.
- 5. Instalando la versión correcta de Java para Cassandra.
- 6. Interactuamos desde consola con la nueva base de datos.
- 7. Instalación de la consola Helenos para Cassandra.
- 8. Instalación de DataStax Development Center.
- 9. Conclusiones.
1. Entorno
Este tutorial está escrito usando el siguiente entorno:
- Hardware: Ordenador iMac 27″ (3.2 GHz Intel Core i5, 8 GB DDR3)
- Sistema Operativo: Mac OS X Mavericks 10.9
2. Introducción.
Dentro del mundo de las bases de datos NoSql existen muchas opciones sobre las que elegir: clave-valor, columnares, orientadas a documentos, orientadas a grafos, etc.
Me gusta saber las cosas de primera mano y "oler" la madurez de los productos, entornos y tecnologías y por ello vamos a dar los primeros pasos con Cassandra que es una base de datos "orientada a columnas".
Siempre digo que la investigación sin un tangible es tirar gran parte del tiempo: este tutorial es el tangible del proceso de investigación que he seguido con la idea de que en mucho menos tiempo cualquier compañero de Autentia (o de fuera), sea capaz de llegar a las mismas conclusiones en mucho menos tiempo que yo y, si hace un tutorial adicional, yo podré a su vez avanzar con menos esfuerzo. Como diría Newton: "Si he logrado ver más lejos, ha sido porque he subido a hombros de gigantes."
Si en el tutorial anterior de MongoDB decía que me recordaba a Tamino, de mis años en Software AG, ésta me recuerda, siempre desde de distancia y el cariño, a AdabasC, con campos periódicos y múltiples, estructuras desnormalizadas para alcanzar una eficiencia en almacenamiento y recuperación especiales (ver http://jmpeco.es/personal/usr_docs/adabas_2.pdf). Todo en la vida se parece algo a otra cosa aunque obviamente estas bases de datos aportan un valor nuevo: el crecimiento horizontal 🙂
3. Descargar el software.
Vamos al portal de Cassandra en Apache: cassandra.apache.org/

En el propio Web nos sugiere que nos descarguemos una distribución ya compilada que podemos conseguir en DataStax.
4. Preparación del entorno.
Ejecutamos los Scripts para instalar. Simplemente seguimos las instrucciones para crear un directorio de trabajo, desplegar los binarios, añadir el path a la variable $PATH del entorno, etc.
Es recomendable ir siempre a la fuente original y seguir los pasos: http://wiki.apache.org/cassandra/GettingStarted
Last login: Tue Nov 19 18:29:48 on ttys000 MacBookPro2RCanales:~ rcanalesmora$ pwd /Users/rcanalesmora MacBookPro2RCanales:~ rcanalesmora$ cd programas/ MacBookPro2RCanales:programas rcanalesmora$ cd dsc-cassandra-2.0.2/ MacBookPro2RCanales:dsc-cassandra-2.0.2 rcanalesmora$ sudo mkdir -p /var/log/cassandra Password: MacBookPro2RCanales:dsc-cassandra-2.0.2 rcanalesmora$ sudo chown -R `whoami` /var/log/cassandra MacBookPro2RCanales:dsc-cassandra-2.0.2 rcanalesmora$ sudo mkdir -p /var/lib/cassandra MacBookPro2RCanales:dsc-cassandra-2.0.2 rcanalesmora$ sudo chown -R `whoami` /var/lib/cassandra MacBookPro2RCanales:dsc-cassandra-2.0.2 rcanalesmora$ sudo su sh-3.2# cd /etc/paths.d/ sh-3.2# echo "/Users/rcanalesmora/programas/dsc-cassandra-2.0.2/bin" > cassandra sh-3.2# ls cassandra mongodb sh-3.2# cat cassandra /Users/rcanalesmora/programas/dsc-cassandra-2.0.2/bin sh-3.2#
Cuando lo tenemos instalado, sólo tenemos que ejecutar el comando cassandra para arrancar.
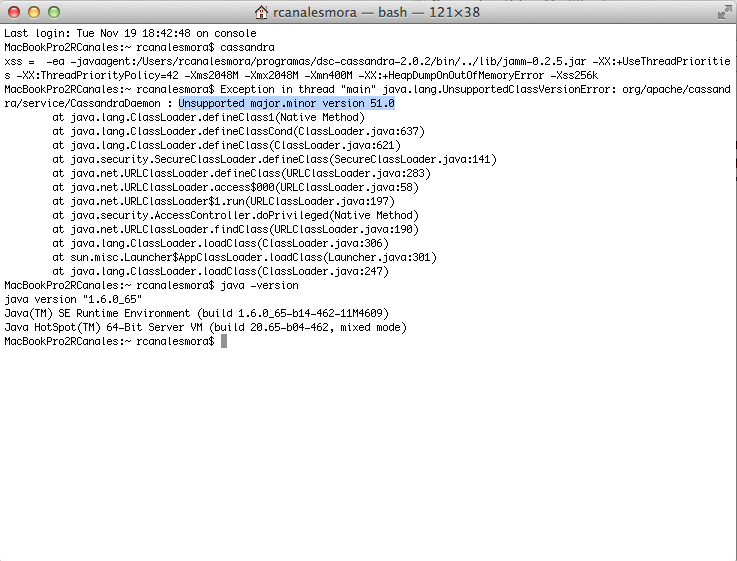
Podemos observar que en mi caso se produce un error. Como está construida en Java tiene que haber una coincidencia entre la versión en la que está compilada y la que tengo instalada (por lo menos tiene que ser esta última igual o superior).
5. Instalando la versión correcta de Java para Cassandra.
El problema es la versión de Java instalada en mi Mac. Para solucionarlo podéis consultar un tutorial de @alejandropgarci que cuenta los pasos para instalar Java7 en Mac OS X.
Le hacemos caso descargándola, instalándola y haciendo unos pequeños cambios manuales en los ficheros del sistema para que encuentre la versión que necesitamos.
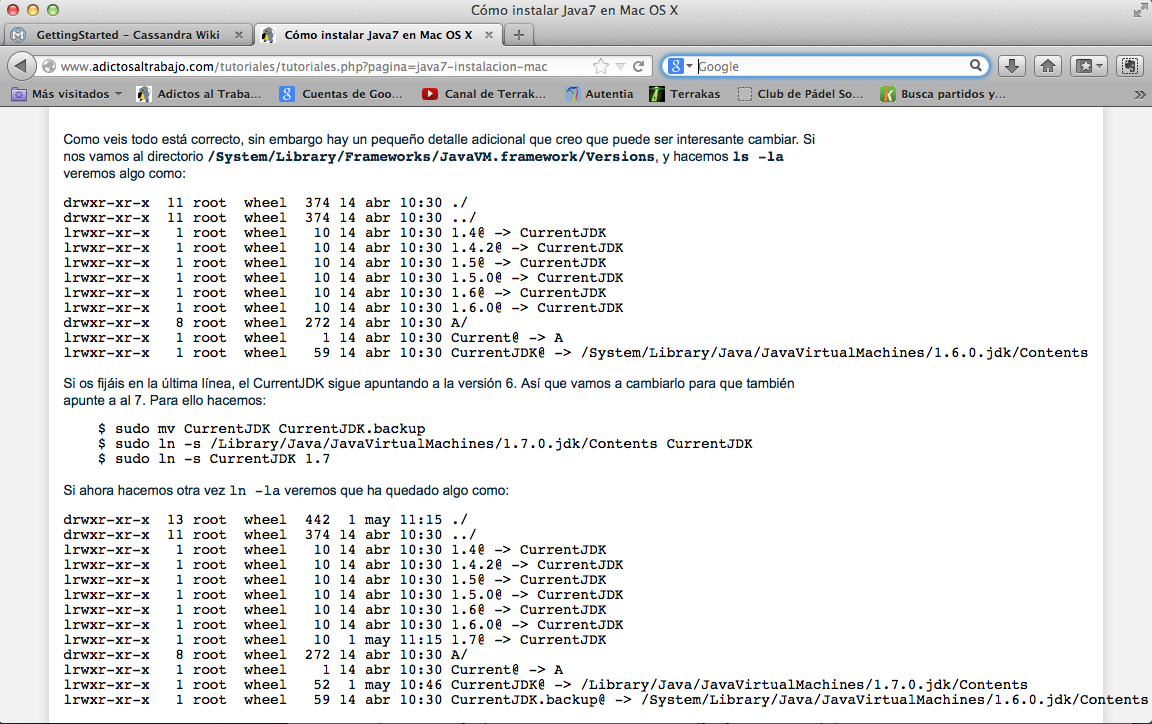
Como tip adicional (que he puesto como comentario en el tutorial), "me daba un error porque en .bash_profile estaba puesta la variable de entorno JAVA_HOME a la versión 6, que conviene ponerla a JAVA_HOME=$(/usr/libexec/java_home)"
Una vez corregida la variable de entorno JAVA_HOME ya arranca correctamente.
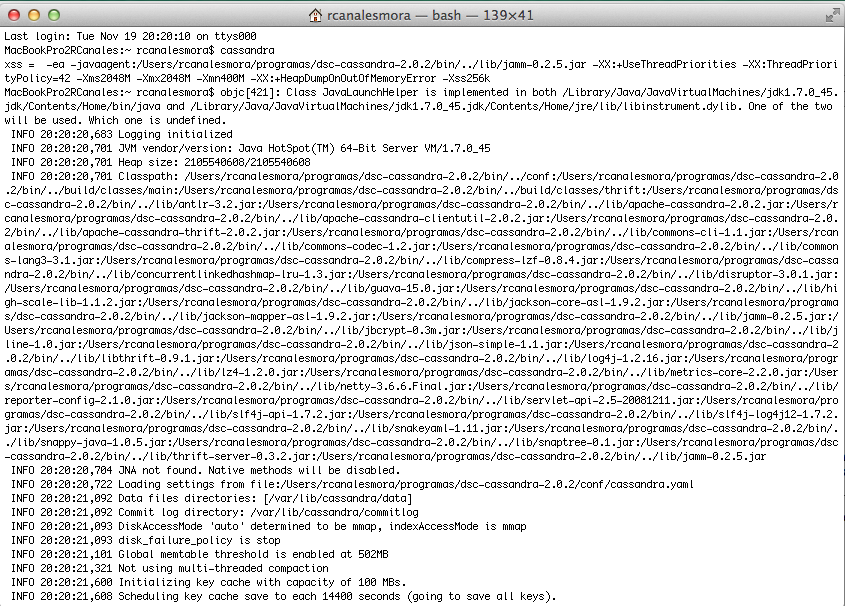
6. Interactuamos desde consola con la nueva base de datos.
Para atacar la base de datos y asegurarnos que funciona seguimos el manual:
Y ejecutamos cqlsh (que tenemos en el path), para arrancar la aplicación interfaz de línea de comando para interactuar con el sistema.
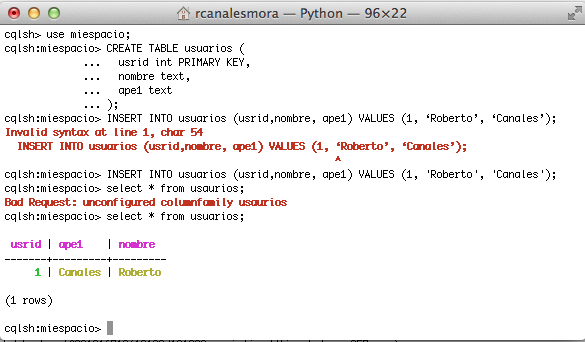
CREATE KEYSPACE miespacio WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };
USE miespacio
CREATE TABLE usuarios (
usrid int PRIMARY KEY,
nombre text,
ape1 text
);
INSERT INTO usuarios (usrid,nombre, ape1) VALUES (1, ‘Roberto’, ‘Canales’);
select * from usuarios;
Como podemos ver en la captura siguiente, nos pueden fallar las cosas por chorradillas: no especificar el espacio a usar, al copiar y pegar las comillas no son las correctas, etc. Bueno, pero estamos en órbita y ya podemos empezar a juguetear un poquito más.
7. Instalación de la consola Helenos para Cassandra.
Como ya hice con MongoDB, voy a instalarme un entorno un pelín más amigable para jugar con Cassandra que la línea de comando básica tan susceptible de errores 🙂
La primera que vamos a probar se llama Helenos
He descargado el bundle que incluye Apache Tomcat. Lo descomprimimos.
Para arrancar apache ejecutamos catalina.sh start
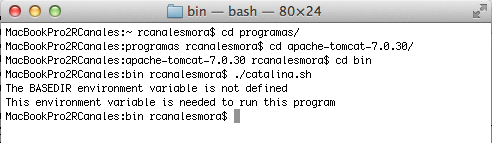
Nos da un error porque no están correctamente establecidas las variables de entorno, en concreto CATALINA_HOME.
Editamos el fichero .bash_profile. Aquí tenéis una captura de la secuencia de comandos.
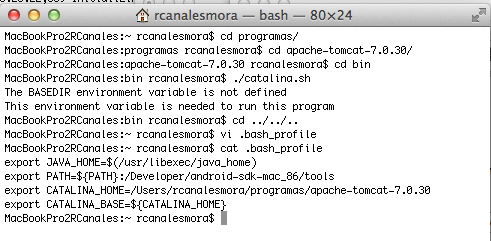
Arrancamos el servidor de nuevo y ya funciona correctamente.

Atacamos con un navegador por http a localhost:8080.

Metemos la contraseña por defecto: admin admin

Bueno, ya tenemos otra herramienta con la que jugar.
Es interesante sobre todo para ver los parámetros de inicialización.
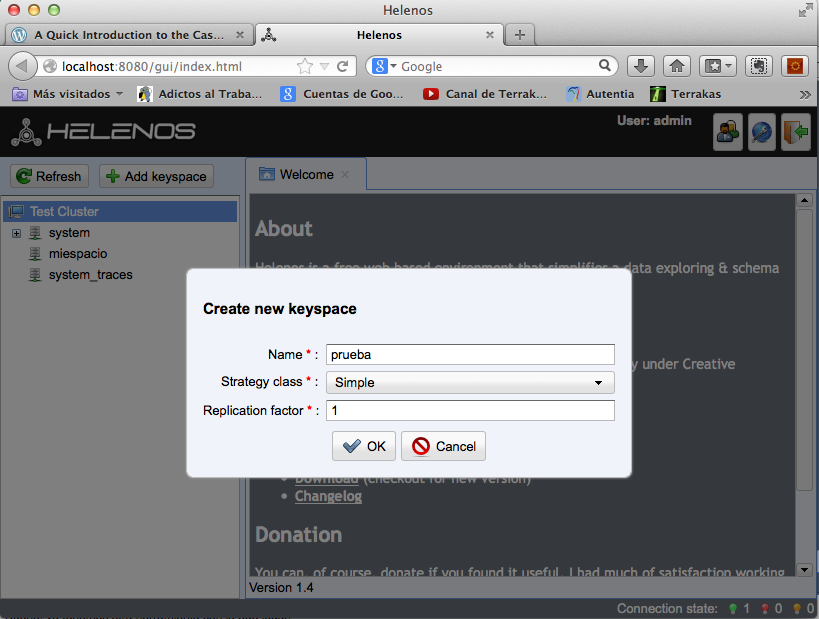
Añadimos familia de columnas (lo que vendría a ser conceptualmente una tabla pero con sus matices de que cada columna se almacena o puede almacenar por separado).
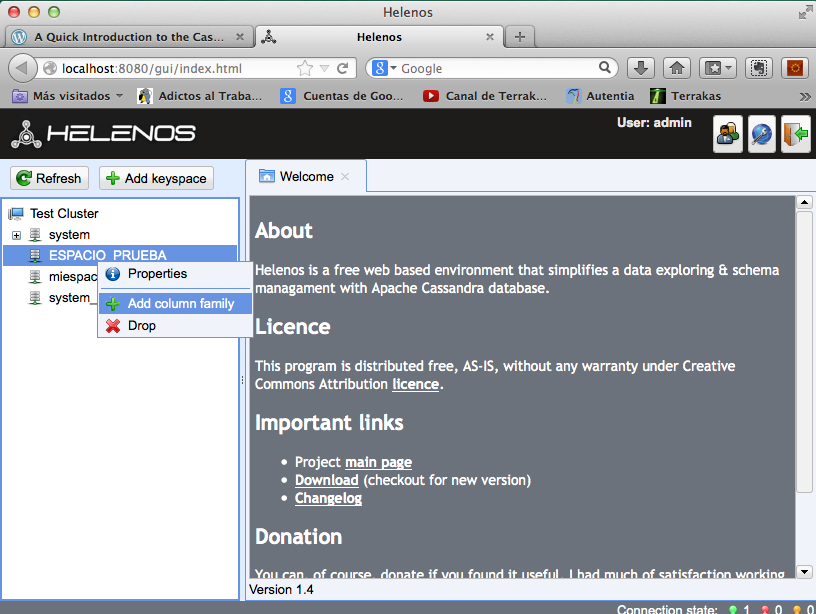
Añadimos los atributos (ojito que luego nos arrepentiremos de no estudiar un poquito mejor los tipos de datos que indicamos).
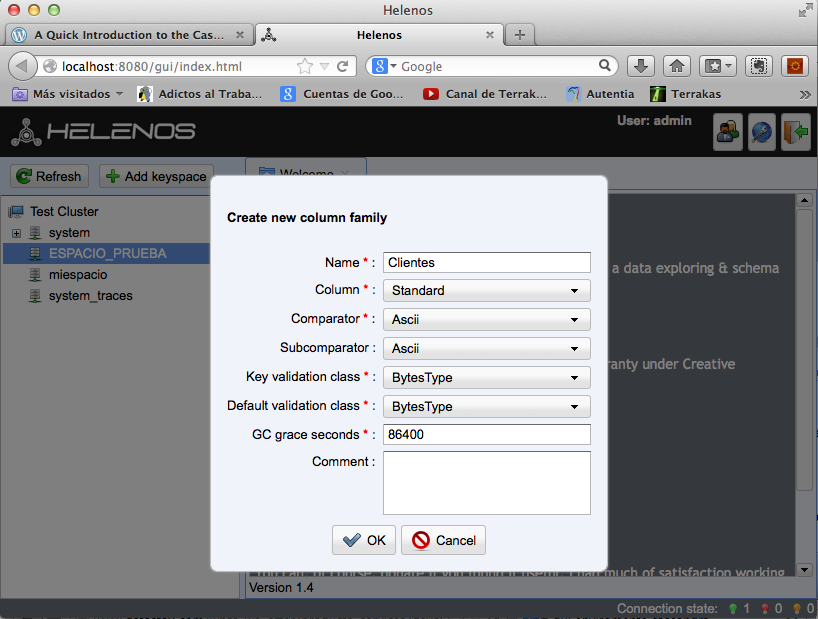
Desde la consulta CQL vamos a introducir un comando para añadir columnas (no he sido capaz de encontrar donde hacerlo visualmente).
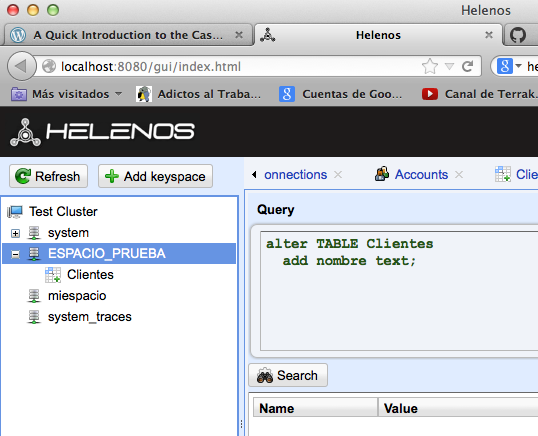
Vemos que se ha añadido dando a propiedades.
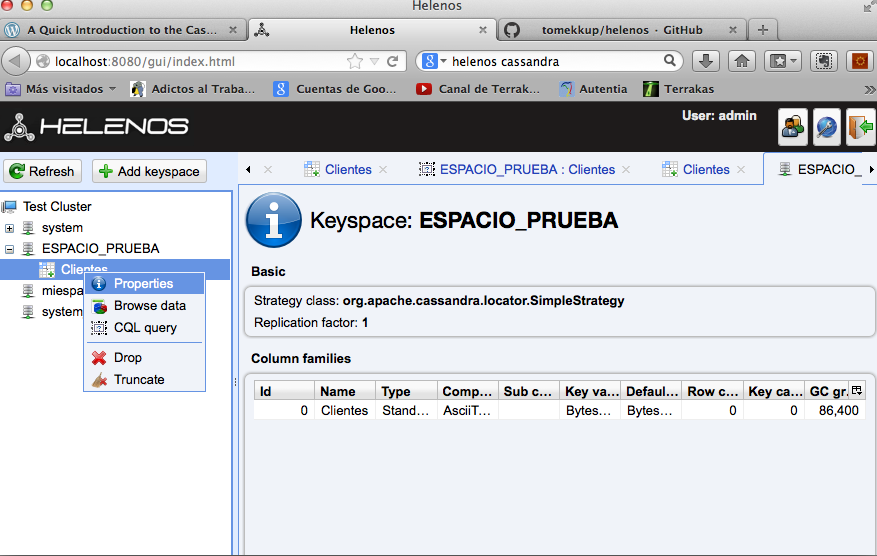
Añadimos un registro (estoy haciendo un poco de trampa con la clave).
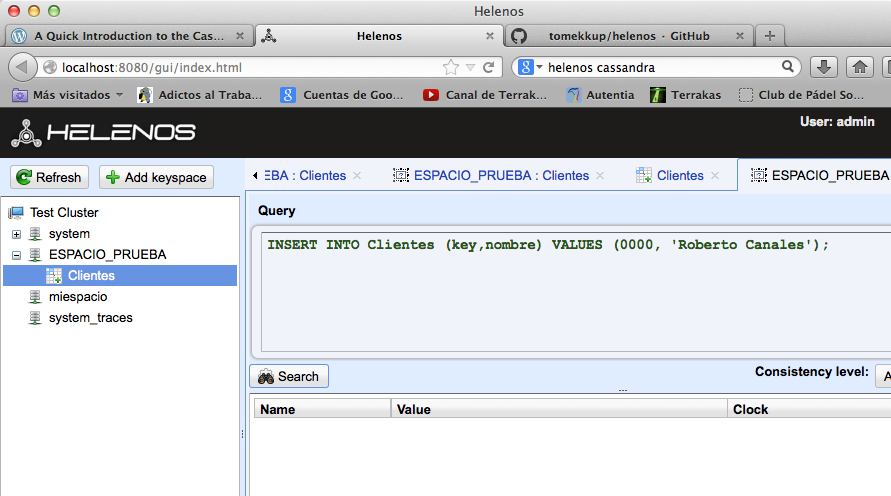
Vemos el resultado.
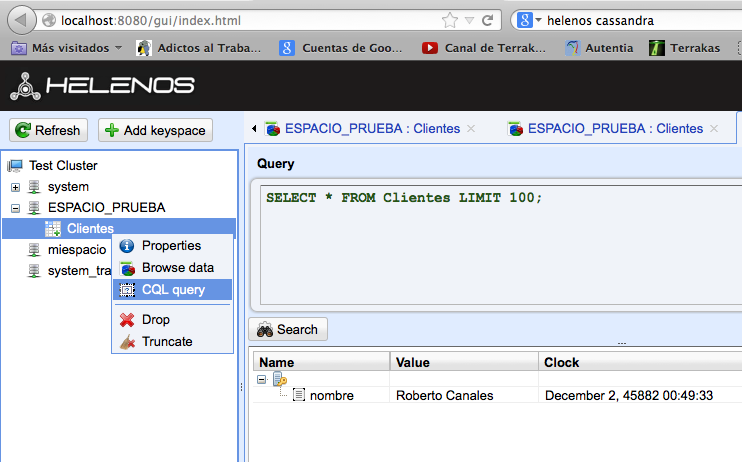
La verdad es que me tiene despistado esta herramienta porque lo que hago dentro de ella no lo veo fuera y lo que hago fuera no lo veo dentro (me refiero a una sesión de Terminal de cqlsh)… tendré que seguir investigando porque seguro que es una chorrada (relativo a permisos).
De todos modos, aunque no perderemos de vista esta herramienta por sus evoluciones futuras, voy a descargarme otra de DataStax.
8. Instalación de DataStax Development Center.
DataStax pone a disposición de los desarrolladores un entorno Eclipse adaptado para trabajar con Cassandra. Está bien porque puedes guardar las conexiones, ejecutar sentencias CQL y guardarlas como Scripts, te va diciendo los errores en las sentencias antes de ejecutarlas, se colorea el código, ves las estructuras de las los espacios, tablas e índices (por llamarlos así, con sus matices 😉

Descargamos el entorno:
En Mac es una aplicación nativa
Si estamos acostumbrados a Eclipse es muy predecible. Creamos una nueva conexión.
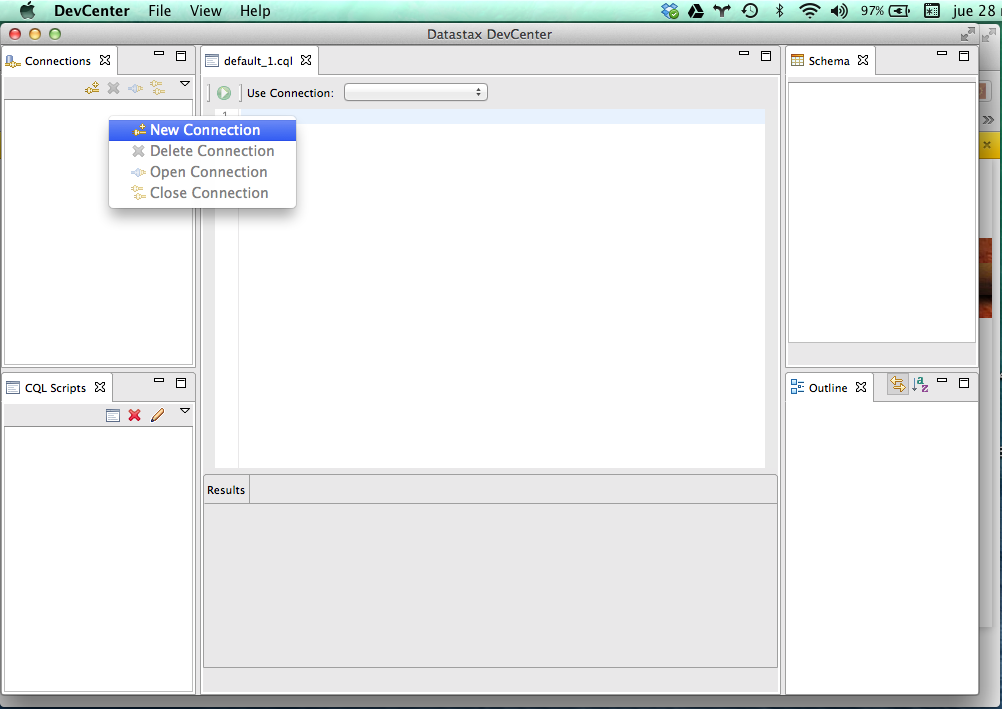
Demos al botón de test a ver si todo va bien.
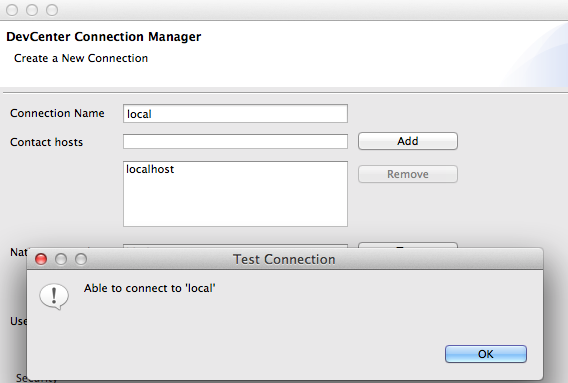
Elegimos en la pantalla principal la conexión a Cassandra a usar.
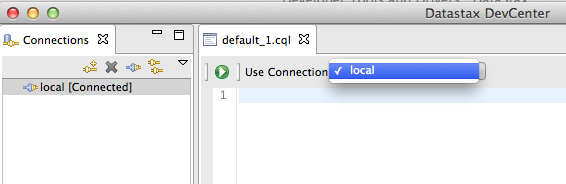
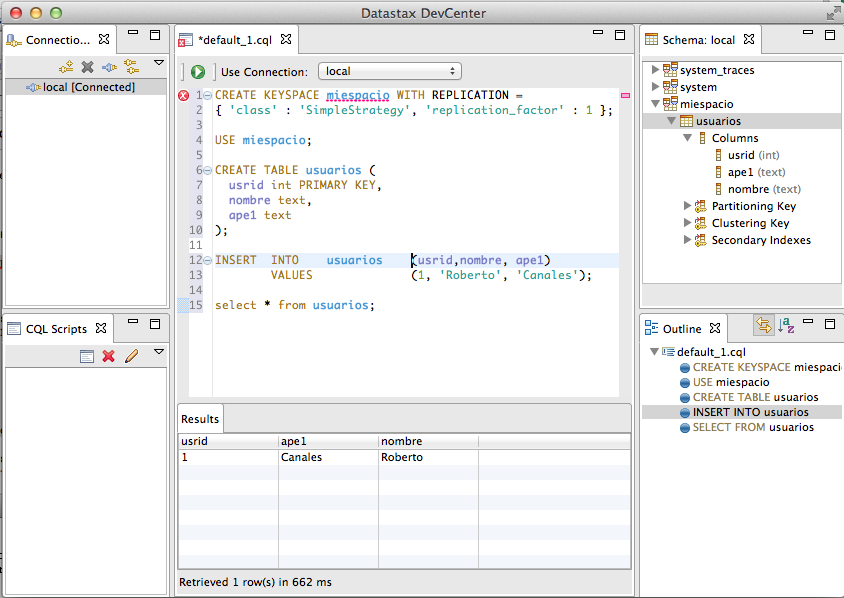
Y ya estamos operativos.
Podemos lanzar nuestros Scripts y ver inmediatamente los resultados. Si la última sentencia que pones es un select ves los cambios reflejados abajo.
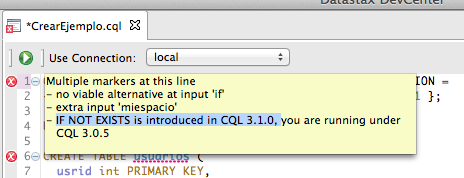
CREATE KEYSPACE if not exists miespacio WITH REPLICATION =
{ 'class' : 'SimpleStrategy', 'replication_factor' : 1 };
USE miespacio;
CREATE TABLE usuarios (
usrid int PRIMARY KEY,
nombre text,
ape1 text
);
INSERT INTO usuarios (usrid,nombre, ape1)
VALUES (1, 'Roberto', 'Canales');
select * from usuarios;
Para seguir jugando sería conveniente tener a mano un resumen del lenguaje CQL
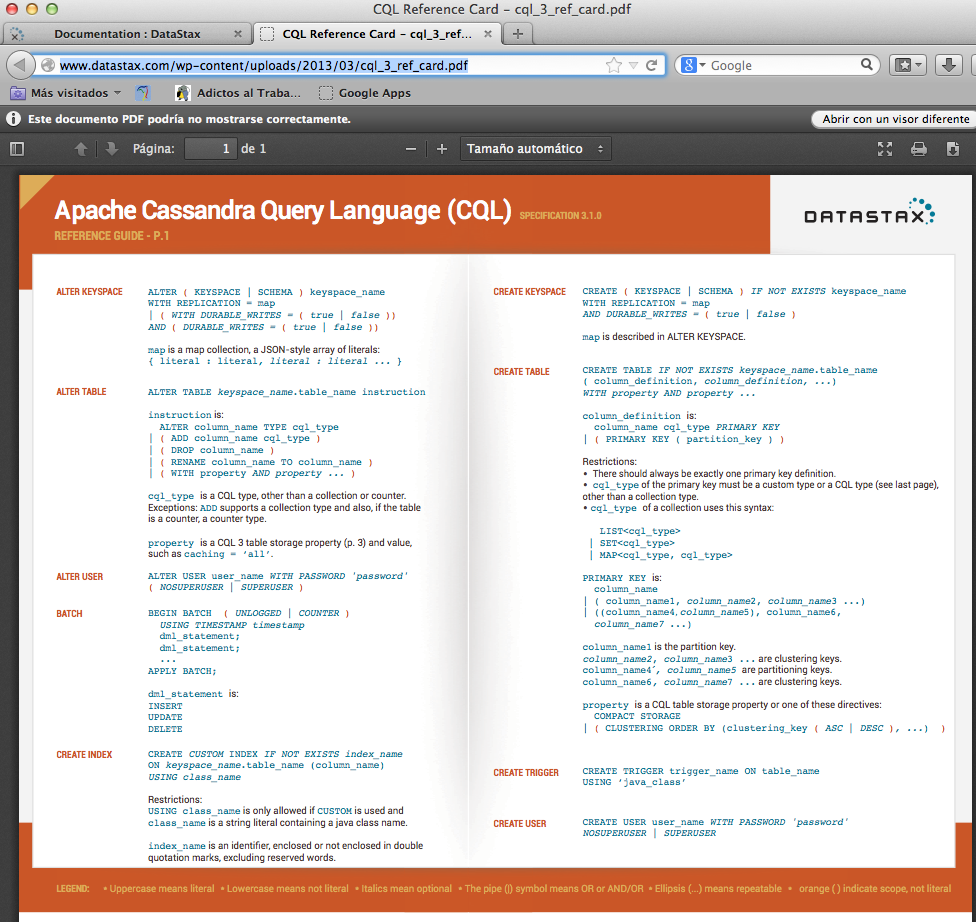
Aunque cuidado con la versión que estamos usando de CQL. Hay cositas interesantes, como sentencias condicionadas (tipo MySQL), para hacer los scripts reentretantes 😉 que solo están disponibles en las últimas versiones.
Probamos a hacer cosas básicas, como añadir columnas. Ésta es una de las gracia de estos tipos de base de datos, que las puedes añadir en cualquier momento porque las columnas se almacenan en sitios distintos.
USE miespacio; alter TABLE miespacio.usuarios add sede text;
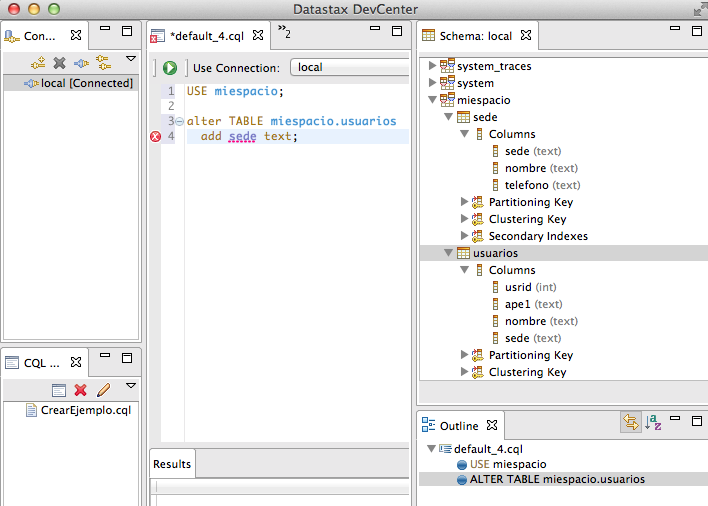
Comprobamos que se ha creado
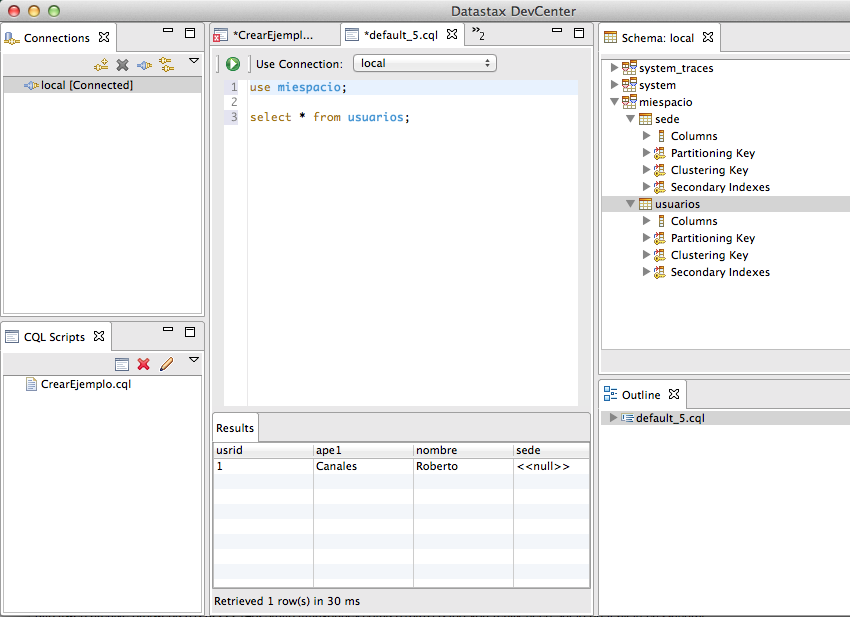
Los comandos de actualización son primos (aunque lejanos :-), hermanos de SQL.
Tenemos que especificar la clave.
use miespacio; update usuarios set sede = 'Madrid' where usrid = 1;
Estando investigando sobre estructuras más complejas de almacenamiento, durante un rato, tirando de un libro antiguo de Cassandra (del 2010.. ya viejo para esto), hacía referencia a super-columnas que pueden tener a su vez pares clave valor. Esto ha quedado obsoleto por otras variantes en versiones más modernas de CQL. Os recomiendo un pasito por este enlace:
http://www.datastax.com/documentation/cql/3.1/webhelp/index.html#cql/ddl/ddl_intro_c.html#concept_ds_tgl_q2y_zj
Vamos a modificar un poquito la estructura para crear un nivel superior de anidamiento de la información. Sobre todo tiene mucho sentido cuando esa información es única. Vamos a añadir los gastos asociados a un individuo.
use miespacio;
ALTER TABLE usuarios ADD gastos map;
update usuarios set gastos =
{ '2013-11-28' : 'Compra de loteria',
'2013-11-29' : 'Cervezas con amigos'}
where usrid = 1;
// select * from usuarios;
select gastos from usuarios where usrid = 1;
Podemos ver el resultado desde la consola cql desde la consola.
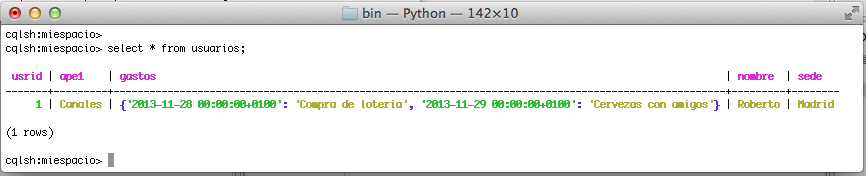
Bueno, para un primer tutorial y tomar el contacto creo que ya es suficiente. Con un poquito más de esfuerzo podemos partir de este punto para atacar tópicos más avanzados de Apache Cassandra.
9. Conclusiones.
A mi me gusta trabajar con tecnologías que ya van siendo demandadas en los entornos en los que trabajo: investigar pronto pero usarlas/proponerlas cuando están estables y hay referencias en el mercado cercano. Las tendencias están muy bien para captar la atención en charlas y conferencias pero dan poco de comer 😉
Del BigData y bases de datos NoSql se lleva hablando durante meses (digo esto porque los años entran en una mano), pero siempre hay dudas sobre la madurez de las tecnologías.
Parece que ese momento para invertir recursos formativos ya ha llegado y que va a ser imparable el uso más habitual en clientes de estas tecnologías como complementarias para las existentes: en ningún caso sustitutivas porque se usan para cosas diferentes que las bases de datos relacionales.


Amigo gracias por el aporte. Yo esta ahora empiezo a entender este tema y por eso no me es posible contribuir para que siga mejorando esta web =(. Espero en tiempo no muy lejano poder colaborar =), pero igual para mi ha sido de gran aporte esta información.
Se te agradece.
Saludos,
agradecido por tu gran aporte y conocimiento mil gracias