Los procesos batch (o procesos por lotes) son aquellos programas que se lanzan generamente de manera programada y que no requieren ningún tipo de intervención humana. Suelen ser procesos relativamente pesados, que tratan una gran cantidad de información, por lo que normalemente se ejecutan en horarios con baja carga de trabajo para no influir en el entorno transaccional.
Algunos ejemplos de este tipo de procesos podrían ser los destinados a la generación o tratamiento de ficheros de facturación o la generación masiva de documentos (ej: cartas de bienvenida a nuevos clientes).
En este tutorial haremos una introducción a Spring Batch, un excelente framework perteneciente al «ecosistema Spring» diseñado para el desarrollo de procesos por lotes, comentaremos sus principales características, veremos un ejemplo y aprenderemos a empaquetar y ejecutar un proceso.
2. Entorno.
El tutorial está escrito usando el siguiente entorno:
Spring Batch es un framework ligero enfocado específicamente en la creación de procesos batch. Además de marcar unas directrices para el diseño de procesos, Spring Batch proporciona con una gran cantidad de componentes que intentan dar soporte a las diferentes necesidades que suelen surgir a la hora de crear estos programas: trazas, transaccionalidad, contingencia, estadísticas, paralelismo, particionamiento, lectura y escritura de datos, etc…
3.1 Componentes principales.
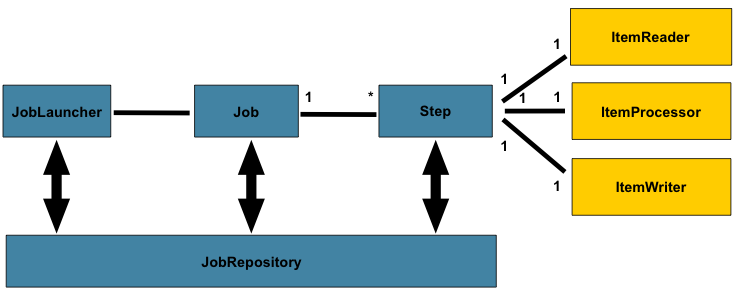
Spring Batch nos propone un diseño como el que se puede apreciar en la siguiente figura para construir nuestros procesos.
Observamos diferentes elementos:
JobRepository: es el componente encargado de la persistencia de metadatos relativos a los procesos tales como procesos en curso o estados de las ejecuciones.
JobLauncher: es el componente encargado de lanzar los procesos suministrando los parámetros de entrada deseados.
Job: El Job es la representación del proceso. Un proceso, a su vez, es un contenedor de pasos (steps).
Step: Un step (paso) es un elemento independiente dentro de un Job (un proceso) que representa una de las fases de las que está compuesto dicho proceso. Un proceso (Job) debe tener, al menos, un step.
Aunque no es obligatorio, un step puede estar compuesto de tres elementos: reader, writer y processor.
ItemReader: Elemento responsable de leer datos de una fuente de datos (BBDD, fichero, cola de mensajes, etc…)
ItemProcessor: Elemento responsable tratar la información obtenida por el reader. No es obligatorio su uso.
ItemWriter: Elemento responsable guardar la información leída por el reader o tratada por el processor. Si hay un reader debe haber un writer.
Probablemente, la parte más interesante de todo este diseño resida en los steps (o pasos que conforman un proceso). En el siguiente apartado veremos cómo Spring Batch se basa en el enfoque «Chunk-Oriented» para la ejecución de los steps de un proceso.
3.2 Chunk-Oriented Processing.
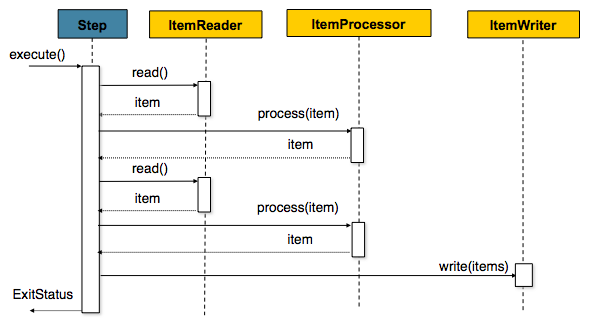
Chunk-Oriented es la técnica que utiliza Spring Batch para la ejecución de las fases de un proceso (nótese que es posible no utilizar en todos los steps este enfoque).
Funciona de la siguiente manera. El reader (en el punto anterior vimos que un step podía contener un reader, un writer y un processor) lee una porción de datos de la fuente de datos y los convierte en un «chunk» (entidad que representa esa porción de información leida). Si existe un processor, ese chunk pasa al processor para que lo trate. Todo esto se realiza dentro de un límite transaccional o, lo que es lo mismo, leemos y tratamos tantos chunks como queramos antes de que sean persistidos por el writer.
Supongamos que tenemos un fichero en texto plano, donde debemos tratar cada línea para luego persistir cierta información en una base de datos. Si configuramos nuestro step con un intervalo de commit fuese igual a 10, lo que haría sería leer una línea del fichero, luego tratarla, leer otra línea del fichero, volver a tratarla, así hasta 10 veces. Una vez que ya hemos leído y tratado 10 líneas, el writer recibe esa información (los 10 chunks) y los persiste en base de datos. Este proceso se repetiría hasta terminar con todas las líneas el fichero.
La siguiente figura ilustra lo que hemos comentado en este punto:
4. Ejemplo.
A continuación veremos un pequeño ejemplo que nos ayude a asimilar mejor todos estos conceptos. Lo que haremos será un pequeño proceso que lea los datos de un fichero en texto plano, los transforme y genere un resultado en un fichero .xml.
Nuestro fichero de entrada, el fichero en texto plano, contiene líneas cuyo formato está deliminato por posiciones, de tal forma que las posiciones 1 a 2 de la línea contendrán el id que representa al elemento y las posiciones de la 3 a la 9 contendrán un texto. Sería algo así:
01LINEA 1
Además, queremos que se genere un fichero .xml con los elementos procesados. El nuevo elemento tras procesar la línea del fichero de entrada se representará con el tag anotherelement y contendrá un elemento hijo id. El valor de dicho id será el resultado de concatenar el id de la línea del fichero original, un separador que será :: y el texto. De forma que quedaría algo como:
1::LINEA 1
Todos los elementos de este fichero de salida colgarán del tag elements.
4.1 Configurando las dependencias.
Para crear nuestro proceso haremos uso de Maven. Las dependencias en el pom.xml quedarían de la siguiente forma:
Contaremos con dos ficheros de configuración: applicationContext.xml y simpleJob.xml. En el primer fichero añadiremos los parámetros de configuración generales para cualquier proceso batch y en el segundo la configuración concreta para nuestro proceso.
El fichero applicationContext.xml quedaría de la siguiente forma:
Lo que hemos hecho ha sido definir nuestro repositorio de Jobs y el lanzador de procesos que, como vimos en el punto 3.1 son dos de los componentes principales de cualquier proceso desarrollado con Spring Batch. Además referenciamos a un fichero de propiedades fileProcessor.properties donde meteremos algunas de las propiedades de nuestros procesos. En concreto, las rutas del fichero de entrada y del de salida.
4.3 Creando nuestro proceso.
Nuestro proceso (Job) constará de un único paso (Step). Dicho Step contará con un reader, encargado de leer las líneas del fichero de texto plano, un processor, encargado de concatenar los elementos del fichero de entrada (id :: texto) y un writer que escribirá el resultado en el .xml
Para ello crearemos un fichero simpleJob.xml (configuración de Spring) donde configuraremos dicho comportamiento. Sería algo como esto:
Veamos paso a paso qué es lo que hemos hecho. Lo primero que observamos es que hemos definido un Job (línea 17) con id processFileJob (este id es importante a la hora de lanzar el proceso. Lo veremos más adelante). Dicho Job tiene un único Step con id processFileStep1. Este Step contiene un Reader, un Processor y un Writer para el que hemos definido un límite transaccional igual a 2. Lo que es lo mismo, se lee una línea del fichero y se procesa, se lee una segunda línea del proceso y se procesa y el resultado se escribe en el fichero de salida. Así hasta que se procese todo el fichero de entrada.
El Reader
Vamos con el Reader. Como vemos, nuestro reader (con id igual a processFileItemReader) es un componente del tipo FlatFileItemReader que no es más que una clase que nos proporciona Spring Batch que está especializada en el tratamiento de ficheros en texto plano. Esta clase es una implementación de la interface ItemReader que define un comportamiento muy sencillo: lee datos de la fuente de datos que sea y devuélvelos en un objeto. Todo reader para Spring Batch debe ser una implementación de ItemReader, nosotros hemos utilizado FlatFileItemReader por comodidad (podríamos haber implementado nuestro propio reader).
public interface ItemReader<T> {
T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException;
}
Nuestro reader necesita conocer el fichero que va a procesar (propiedad resource) y un mapper. Este mapper necesita un fieldSetMapper que es el elemento (POJO) en el que va a convertir los datos de las líneas del fichero y un lineTokenizer que es el componente que se encargará de procesar cada una de las líneas.
El elemento en el que queremos que se mapeen los datos de las líneas del fichero es un objeto Element que hemos creado a medida de las necesidades de nuestro proceso. Sería algo así:
public class Element implements Serializable {
private static final long serialVersionUID = 141976950236790725L;
private int id;
private String text;
// constructores, getters, setters, toString, hashCode y equals...
}
Por último, nuestro lineTokenizer es otra clase que nos proporciona Spring Batch (FixedLengthTokenizer) que está especializada en tratar líneas de ficheros en texto plano delimitadas por posición. Lo único que hacemos es decir de qué posición a qué posición están los valores de los atributos de nuestro POJO. En nuestro caso, el id del elemento serán las posiciones 1 y 2 de la línea y el texto las posiciones de la 3 a la 9 (bean processFileLengthLineTokenizer).
La lista de readers que nos proporciona Spring Batch puede consultarse aquí.
El Processor
Nuestro processor elementProcessor es bastante sencillo. No aparece como un bean en el fichero de configuración ya que lo tenemos anotado con @Component. Del mismo modo que sucedía con el reader, los processors también deben implementar una interface: ItemProcessor
public interface ItemProcessor<I, O> {
O process(I item) throws Exception;
}
Como se puede ver es muy sencillo el comportamiento que propone. Se debe definir un método process que recibirá un elemento (elemento que ha leido nuestro reader) y devolverá los datos procesados en otro elemento. En nuestro caso, hemos creado otro POJO (AnotherElement) que contiene un único atributo (id) que representará el elemento (elementos) que queremos escribir en nuestro .xml de salida. Nuestro processor sería algo como esto:
@Component
public class ElementProcessor implements ItemProcessor<Element, AnotherElement> {
@Override
public AnotherElement process(Element element) throws Exception {
final String anotherElementId = element.getId() + "::" + element.getText();
return new AnotherElement(anotherElementId);
}
}
El Writer
Para finalizar el proceso necesitamos un writer al que le hemos dado un identificador processFileXMLWriter. Del mismo modo que ocurría con el reader y el processor, nuestro writer deberá implementar una interface. En este caso ItemWriter:
Como vemos lo único que debemos hacer es implementar el comportamiento de la escritura de nuestra lista de POJO´s que haya sido generada en la lectura o el procesamiento. ¿Y por qué una lista en vez de un único elemento?. La respuesta es muy sencilla. Si recoradamos, Spring Batch se basa en Chunk-Oriented Processing de forma que, en base a un límite transaccional, leerá y procesará elementos para luego persistirlos. La lista de elementos a persistir tendrá un tamaño igual a ese límite transaccional.
Del mismo modo que hicimos con el reader, haremos uso de un componente writer que nos proporciona Spring Batch, en concreto StaxEventItemWriter que está especializado en escribir POJO´s en ficheros en formato XML. Para construir un componente de este tipo debemos indicarle el fichero en el que queremos que los datos de salida sean persistidos (resource), un marshaller o elemento que transformará de POJO a XML, el rootTagName que será la etiqueta padre sobre la que cuelguen los elementos en formato XML y overwriteOutput que indicará si queremos que se sobreescriba el fichero en caso de que ya existiese.
La lista de writers que nos proporciona Spring Batch puede consultarse aquí.
5. Empaquetando y ejecutando nuestro proceso.
Podemos ejecutar nuestro proceso sin ningún problema desde nuestro entorno de desarrollo favorito. En mi caso, he utilizado Intellij Idea, aunque puede hacerse desde cualquier otro IDE (Eclipse, NetBeans, etc…). Como siempre, deberemos indicar una clase Main y unos argumentos. Para ello:
Argumentos: simpleJob.xml processFileJob. Donde el primer argumento es el nombre que le hemos dado al fichero .xml donde hemos configurado nuestro Job y el segundo es el id del Job.
Además, si así lo deseamos, podemos lanzar nuestro proceso con Maven. Para ello, en el directorio de nuestro proyecto (donde está el pom.xml) ejecutamos:
Sin embargo, los procesos batch no suelen lanzarse así (al menos en producción), sino en servidores dedicados a ello. Por este motivo, sería muy interesante empaquetar nuestro proceso, para dejarlo en nuestro servidor y que pueda ser lanzado desde ahí. Para ello meteremos nuestro módulo (.jar), sus dependencias y sus ficheros de configuración en un .zip cuyo contenido será algo como lo siguiente:
Donde el directorio conf/ contendrá los ficheros de propiedades que contendrán los parámetros dependientes del entorno (en nuestro caso las rutas del fichero de entrada y de salida), el directorio lib/ contendrá las librerías de las que depende nuestro proceso y springbatch-1.0-SNAPSHOT.jar será el módulo con nuestro proceso.
Como contamos con la inestimable ayuda de Maven, este proceso de ensamblaje es muy sencillo. Haremos uso de los plugins maven-jar-plugin y maven-assembly-plugin. El primero lo utilizaremos para construir el .jar de nuestro módulo, indicarle la clase Main y añadir las dependencias al classpath. El segundo nos generará un fichero .zip con el módulo, sus dependencias y sus ficheros de propiedades con la estructura descrita anteriormente.
Lo primero que hacemos será crear nuestro .jar (el módulo del proceso) de la forma deseada. Añadimos lo siguiente a nuestro pom.xml:
Ejecutamos mvn clean package y obtendremos nuestro empaquetado en el directorio target/ bajo el nombre springbatch-1.0-SNAPSHOT-distribution.zip.
Para lanzarlo en el entorno que deseemos, descomprimimos el contenido del .zip en el directorio deseado, configuramos las propiedades del directorio conf/ y, en ese mismo directorio (a la altura del .jar), ejecutamos lo siguiente:
En este tutorial hemos pretendido hacer una pequeña introducción a Spring Batch, un excelente framework para el desarrollo de procesos batch en Java con el que cualquiera que esté familiarizado con el tema seguro que se siente muy identificado. Además, si el usuario está acostumbrado a trabajar con módulos del «ecosistema Spring», seguro que le será mucho más fácil hacerse con las riendas.
Por último, me gustaría destacar que lo que hemos visto en este tutorial es solo la punta del iceberg. Spring Batch ofrece soporte a muchos de los problemas típicos que nos encontramos al desarrollar procesos batch tales como procesamiento multilínea, paralelismo, paginación, gestión de errores, contingencia, trazas, etc… Además, su documentación es excelente 🙂
Espero que este tutorial os haya sido de ayuda. Un saludo.
Mis felicitaciones por este tutorial tan completo. Me gustaría poder descargarme una copia en PDF, pero al pulsar sobre el link me indica que el fichero no existe ¿Podrías ponerlo disponible? Gracias de antemano.
Buenos días, estoy trabajando con Spring batch, y tengo un problemilla. ¿Como puedo guardar el fichero resultante de mi proceso batch con el nombre que yo quiera? En este caso tendría que guardarlo con un identificador que tomo de la BBDD en un paso anterior. ¿Me podríais echar un cable?
No sé exactamente qué writer estás utilizando. Probablemente lo que yo haría sería crearme mi propio writer de una de las siguientes formas: – extendiendo de otro writer (por ejemplo: StaxEventItemWriter) – implementando las interfaces que considerase necesarias (en tu caso al menos de ResourceAwareItemWriterItemStream)
Con esto, lo siguiente que haría sería asignar el valor del \\\»Resource\\\» (método setResource) una vez que ya supiera el nombre del fichero.
Buenos dias de nuevo. Gracias por tu comentario al respeto del otro día. Pero el problema que tengo es que quiero dar nombre a varios ficheros que estoy componiendo con el batch, y el nombre que quiero asignarles es un dato de la BBDD….y el problema es que no se como recuperar ese dato en el app-context del writter… ¿Me puedes guiar un poco?
Ese temas es más de Spring (core) que de Spring-Batch. Yo te recomendaría que usases un PropertyPlaceholderConfigurer que saque esos datos de la base de datos.
Estamos desarrollando un batch en que tenemos un job con un solo step en el que tenemos un listener. En nuestra clase del Listener implementamos las interfaces ItemWriteListener y StepExecutionListener. En el método beforeWrite insertamos un valor en el ExecutionContext. Después de realizar el método beforeWrite nuestro job llama a una clase en donde nosotros queremos recuperar el valor q hemos guardado en el ExecutionContext.
¿Como podemos acceder al ExecutionContext desde otra clase?
Felicitarte por tan claro y completo tutorial sobre todo para los no iniciados en el tema, como es mi caso. Sólo comentarte que hay un par de enlaces que no funcionan (Las listas de readers y writers que nos proporciona Spring Batch), y por si quieres editarlos, te paso el «actualizado» (espero que sea éste):
Gracias por la explicación.
Tengo unas preguntas al respecto…
Si tengo dos jobs, uno en un fichero xml y otro en otro…
1.- ¿Cómo puedo ejecutar en IntelliJ con Maven los dos jobs?
Puedo ejecutarlos por separado pero no sé cómo ejecutarlos a la vez:
exec:java -Dexec.mainClass=org.springframework.batch.core.launch.support.CommandLineJobRunner «-Dexec.args=simpleJobTxtToTxt.xml processFileJobTxt»
2.- ¿Cómo puedo hacer que el proyecto se quede ejecutado mirando la carpeta de entrada, de manera que cuando llegue un fichero input lo convierta a output?




Mis felicitaciones por este tutorial tan completo. Me gustaría poder descargarme una copia en PDF, pero al pulsar sobre el link me indica que el fichero no existe ¿Podrías ponerlo disponible? Gracias de antemano.
Buenos días,
estoy trabajando con Spring batch, y tengo un problemilla.
¿Como puedo guardar el fichero resultante de mi proceso batch con el nombre que yo quiera?
En este caso tendría que guardarlo con un identificador que tomo de la BBDD en un paso anterior.
¿Me podríais echar un cable?
Muchas gracias.
Hola mivan,
No sé exactamente qué writer estás utilizando. Probablemente lo que yo haría sería crearme mi propio writer de una de las siguientes formas:
– extendiendo de otro writer (por ejemplo: StaxEventItemWriter)
– implementando las interfaces que considerase necesarias (en tu caso al menos de ResourceAwareItemWriterItemStream)
Con esto, lo siguiente que haría sería asignar el valor del \\\»Resource\\\» (método setResource) una vez que ya supiera el nombre del fichero.
Saludos.
Buenos dias de nuevo.
Gracias por tu comentario al respeto del otro día.
Pero el problema que tengo es que quiero dar nombre a varios ficheros que estoy componiendo con el batch, y el nombre que quiero asignarles es un dato de la BBDD….y el problema es que no se como recuperar ese dato en el app-context del writter…
¿Me puedes guiar un poco?
Hola mivan,
Ese temas es más de Spring (core) que de Spring-Batch. Yo te recomendaría que usases un PropertyPlaceholderConfigurer que saque esos datos de la base de datos.
Saludos
Buenas tardes.
Estamos desarrollando un batch en que tenemos un job con un solo step en el que tenemos un listener. En nuestra clase del Listener implementamos las interfaces ItemWriteListener y StepExecutionListener. En el método beforeWrite insertamos un valor en el ExecutionContext. Después de realizar el método beforeWrite nuestro job llama a una clase en donde nosotros queremos recuperar el valor q hemos guardado en el ExecutionContext.
¿Como podemos acceder al ExecutionContext desde otra clase?
Gracias.Un saludo.
Hola, tengo problema en poner las rutas en el fichero fileProcessors.properties me puedes dar un ejemplo por favor?
Hola.
Felicitarte por tan claro y completo tutorial sobre todo para los no iniciados en el tema, como es mi caso. Sólo comentarte que hay un par de enlaces que no funcionan (Las listas de readers y writers que nos proporciona Spring Batch), y por si quieres editarlos, te paso el «actualizado» (espero que sea éste):
http://docs.spring.io/spring-batch/reference/html/listOfReadersAndWriters.html
Un saludo y gracias
Buenas,
Os dejo unos ejemplos que pueden ser útiles y documentación de Spring Batch:
https://github.com/maldiny/Spring-Batch-en-Castellano
Espero os sean de utilidad.
Un saludo!
Gran tutorial !!
Pero en el esquema Reader – Processor – Writer, no sería:
«Si hay un writer debe haber un reader.» ??
Hola,
¿Es posible leer de dos ficheros y procesarlos juntos?
El caso es que tengo dos ficheros con XML los cuales tengo que comparar, para la comparación uso el XMLDiff
Gracias!
El tutorial está guay. Se agradece!
Muchas gracias por tomarse el tiempo para esto, bastante útil!
Hola,
Gracias por la explicación.
Tengo unas preguntas al respecto…
Si tengo dos jobs, uno en un fichero xml y otro en otro…
1.- ¿Cómo puedo ejecutar en IntelliJ con Maven los dos jobs?
Puedo ejecutarlos por separado pero no sé cómo ejecutarlos a la vez:
exec:java -Dexec.mainClass=org.springframework.batch.core.launch.support.CommandLineJobRunner «-Dexec.args=simpleJobTxtToTxt.xml processFileJobTxt»
2.- ¿Cómo puedo hacer que el proyecto se quede ejecutado mirando la carpeta de entrada, de manera que cuando llegue un fichero input lo convierta a output?
Gracias por la ayuda.