
Indexación de documentos en Solr con el soporte de Talend.
0. Índice de contenidos.
- 1. Introducción.
- 2. Entorno.
- 3. Esquema de datos en Solr.
- 4. Fuente de datos: onix.
- 5. Instalación de los componentes de Solr en Talend.
- 6. Diseño del Job de Talend.
- 7. Referencias.
- 8. Conclusiones.
1. Introducción
Todo proyecto de software tiene una fase de migración de información; aún tratándose de un proyecto «de cero» siempre hay datos que migrar a la estructura de información que modelemos para nuestra aplicación: una tabla de países, los usuarios iniciales de acceso, la catalogación del modelo de negocio,…
Si tenemos que hablar de migración de datos:
- E: lectura de una fuente de datos: una base de datos, un fichero xml, un excel,…
- T: tratamiento de esa información para adaptarla a nuestro modelo, y
- L: carga de la información normalizada.
una herramienta áltamente recomendable es Talend, de la cuál ya hemos hablado en otros tutoriales de adictos al trabajo.
Por otro lado, en los cursos que imparte Autentia, si tenemos que proponer un modelo de negocio para realizar los ejercicios asociados a los mismos, solemos modelar las entidades que podría tener una gestión bibliotecaria: libro, autor, materia,… en este tutorial vamos a utilizar ese mismo negocio para migrar la información existente de un catálogo de libros en nuestro motor de indexación: Solr.
Los objetivos son:
- hacer uso de nuestra fuente de datos, un fichero xml con información normalizada sobre el catálogo de libros, en un formato onix, estandar para la industria del libro, y
- usar Talend Open Studio y componentes construidos por la comunidad para llevar a cabo la carga de esa información en Solr
Todo ello, como comentaba, dentro de un proceso de migración de información en el que, por otro lado, tendremos otro que migre la misma o más información a las tablas de una base de datos, si bien, en este tutorial nos centraremos únicamente en Solr.
2. Entorno.
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 15′ (2.4 GHz Intel Core i7, 8GB DDR3 SDRAM).
- Sistema Operativo: Mac OS X Lion 10.7.4
- Talend Open Studio 5.1.1.
- Apache Solr 3.5.
3. Esquema de datos en Solr.
Para indexar la información de un libro en Solr, en el ámbito de este tutorial, proponemos el siguiente esquema:
<fields> <field name="isbn" type="string" indexed="true" stored="true"/> <field name="title" type="text_general" indexed="true" stored="true" /> <field name="summary" type="text_general" indexed="true" stored="false" /> <field name="publicated" type="int" indexed="true" stored="true"/> <field name="price" type="double" indexed="true" stored="true"/> <field name="author" type="text_general" indexed="true" stored="true" multiValued="true"/> </fields>
Dejo como referencia un enlace al siguiente post «Esquemas en Solr» del blog de un buen amigo, en el que podéis ampliar información sobre como definir esquemas en Solr.
4. Fuente de datos: onix.
Nuestra fuente de datos es un fichero xml normalizado con la siguiente información, ponemos como ejemplo un único libro:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<!DOCTYPE ONIXMessage SYSTEM "http://www.editeur.org/onix/2.1/03/reference/onix-international.dtd">
<ONIXMessage>
<Header>
<FromCompany>TEST</FromCompany>
<SentDate>20120722</SentDate>
</Header>
<Product>
<RecordReference>9788483062982</RecordReference>
<NotificationType>03</NotificationType>
<ProductIdentifier>
<ProductIDType>03</ProductIDType>
<IDValue>9788483062982</IDValue>
</ProductIdentifier>
<ProductIdentifier>
<ProductIDType>02</ProductIDType>
<IDValue>8483062984</IDValue>
</ProductIdentifier>
<ProductIdentifier>
<ProductIDType>01</ProductIDType>
<IDTypeName>Depósito legal</IDTypeName>
<IDValue>B. 13.764-2000</IDValue>
</ProductIdentifier>
<ProductForm>BC</ProductForm>
<Set> <TitleOfSet>Siete libros sobre el arte de vivir</TitleOfSet>
</Set>
<Title>
<TitleType>01</TitleType>
<TitleText>Sobre la felicidad</TitleText>
</Title>
<Contributor>
<ContributorRole>A01</ContributorRole>
<PersonNameInverted>Epicuro</PersonNameInverted> </Contributor> <Contributor> <ContributorRole>A23</ContributorRole>
<ContributorRole>B06</ContributorRole>
<LanguageCode>grc</LanguageCode> <PersonNameInverted>García Gual, Carlos</PersonNameInverted> </Contributor> <Contributor> <ContributorRole>A16</ContributorRole> <PersonNameInverted>Lledó, Emilio</PersonNameInverted> </Contributor>
<Language>
<LanguageRole>01</LanguageRole>
<LanguageCode>spa</LanguageCode>
</Language>
<NumberOfPages>128</NumberOfPages>
<MainSubject>
<MainSubjectSchemeIdentifier>09</MainSubjectSchemeIdentifier>
<SubjectCode>821.14'02</SubjectCode>
<SubjectHeadingText>Literatura griega clásica. Historia y crítica. Obras</SubjectHeadingText>
</MainSubject>
<AudienceCode>01</AudienceCode>
<OtherText> <TextTypeCode>12</TextTypeCode> <TextFormat>07</TextFormat> <Text>La doctrina de Epicuro se caracteriza por su reivindicación del placer comofundamento natural, fácil y firme de la felicidad. Este hedonismo, considerado escandaloso
por otros pensadores y muy malentendido y calumniado desde la antigüedad hasta ayer mismo,
ofrece en su perspectiva individualista una senda sólida hacia la dicha cotidiana.
Materialista, atomista, sensualista, sin ilusiones trascendentes, insiste en la
moderación de los deseos, en el rechazo de los temores irracionales, en los placeres
de la vida retirada y sencilla, en los goces del conocimiento, la memoria y la amistad.
</Text> </OtherText>
<Publisher> <PublisherName>Editorial Debate</PublisherName> </Publisher>
<CityOfPublication>Madrid</CityOfPublication>
<CountryOfPubli cation>ES</CountryOfPublication>
<PublishingStatus>04</PublishingStatus> <PublicationDate>2000</PublicationDate>
<SupplyDetail> <SupplierName>Editorial Debate</SupplierName>
<AvailabilityCode>IP</AvailabilityCode>
<Price> <PriceTypeCode>02</PriceTypeCode> <PriceAmount>7.51</PriceAmount> <CountryCode>ES</CountryCode> </Price> </SupplyDetail>
</Product>
</ONIXMessage>
No nos interesa toda la información del documento, solo aquella que vamos a indexar y esto nos va a dar pie a analizar cómo se lleva a cabo la lectura y mapeo de etiquetas de un xml en Talend.
5. Instalación de los componentes de Solr en Talend.
Asumimos que disponemos de una versión de Talend Open Studio, si no es así, podéis consutlar este tutorial o este otro como referencias (ahora estamos en la versión 5.1.1.).
Lo primero es descargarnos los siguientes componentes de Solr y descomprimirlos en un directorio local:
Para añadir los componentes al porfolio de los pre-instalados en Talend debemos copiar cada uno de los directorios descomprimidos en la siguiente ubicación TOS_BD-r84309-V5.1.1/plugins/org.talend.designer.components.localprovider_5.1.1.r84309/components/ext/user, la numeración puede variar en función de la versión.
Una vez copiados debemos reiniciar el TOS y se mostrarán los nuevos componentes en la paleta.
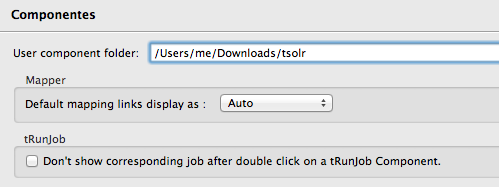
También existe la opción de indicar que el directorio en el que descomprimiste todos los componentes es tu directorio de componentes de usuario (Preferencias > Talend > Componentes):
6. Diseño del Job de Talend.
Una vez disponemos de los componentes ya podemos diseñar nuestro Job, que debería tener, en el modo diseño, un aspecto similar al siguiente:
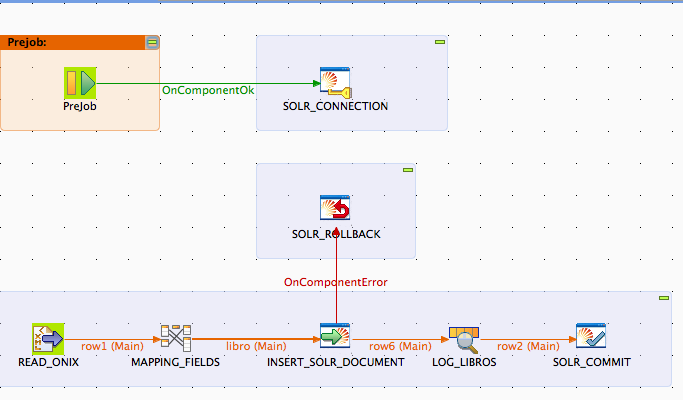
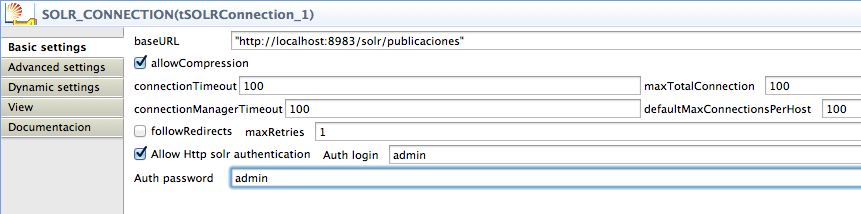
En el Prejob nos conectamos a la url de Solr y, si está securizado, podemos configurar el usuario y clave de paso.
La primera acción del Job, propiamente dicha, es realizar la lectura del fichero onix para lo cuál, primero definimos el esquema de campos con sus tipos de datos
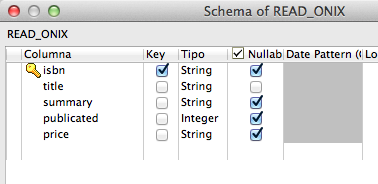
y después definimos los xpath para mapear el contenido de los valores del xml en los mismos.
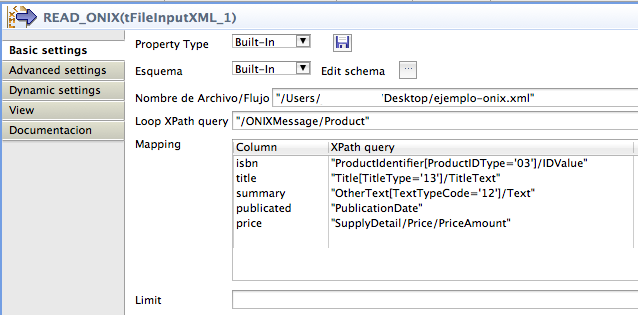
Muy importante a tener en cuenta es que, por defecto, el componente de Talend utiliza un parser DOM, con lo que si estamos trabajando con ficheros de cierto peso, puede que tengamos problemas de memoria, podemos modificar el tipo de parser del componente en la opción de «Advanced settings»:
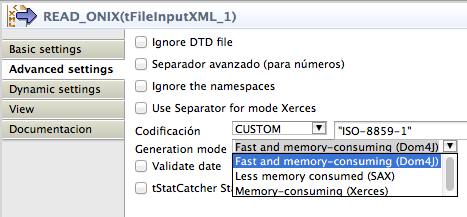
Una vez leido el contenido del documento xml, podríamos omitir el componente de mapeo (tMap), porque la información ya viene normalizada y no tenemos que refundirla, si bien, lo hemos mantenido para, más adelante, intentar resolver la problemática de los campos mutivaluados en el documento xml (los autores), que en este tutorial aún no vamos a cubrir.
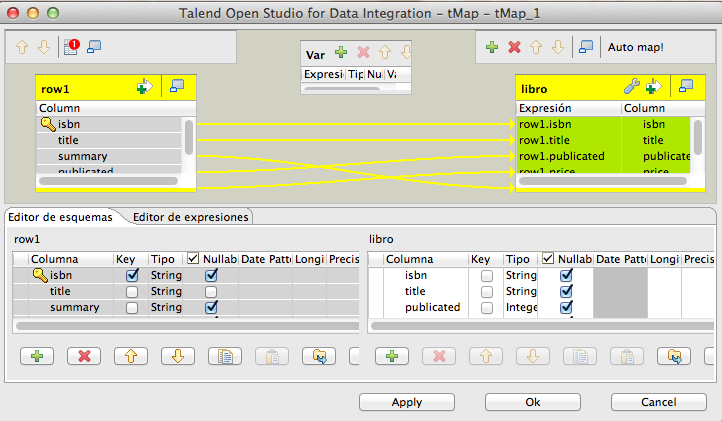
A continuación, hacemos uso del componente tSOLROutput que permite realizar insercciones de documentos estableciendo una conexión previa, la que abrimos en el PreJob.
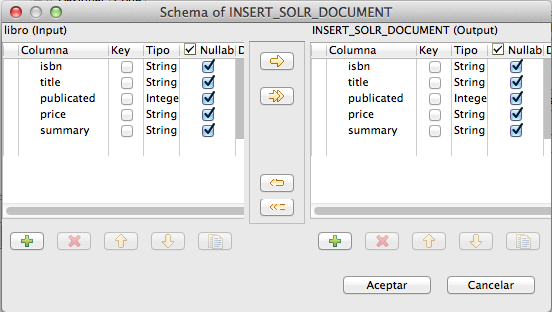
La única configuración de este componente es la correlación de los campos de entrada con los campos de salida, que deben corresponderse con el nombre de los campos del esquema de Solr.
Añadimos un tSOLRRollback, en caso de error y un tSOLRCommit en caso de éxito y, antes del commit, una salida por consola para depurar posibles errores antes del commit.
7. Referencias.
- http://www.talendforge.org/exchange/index.php
8. Conclusiones.
Entre hacer el proceso manualmente y hacerlo con una herramienta de ETL, optamos por la segunda opción. ¿Podría hacerse «a mano» tirando líneas de código?, por supuesto, pero evalúa el coste de introducir una modificación en el proceso (un campo más) o una fuente de datos adicional; con Talend no es más que una caja adicional en el esquema y un mapeo de los campos.
Un saludo.
Jose

