
CÓMO UTILIZAR EL DATASTORE DE GOOGLE APP ENGINE CON JDO
1 Introducción
En tutoriales anteriores os explicamos qué son el cloud computing y Google App Engine y cómo utilizar el datastore de Google App Engine con el API de nivel inferior. En este tutorial el protagonista seguirá siendo el datastore, sólo que esta vez utilizaremos otra tecnología de persistencia: JDO
En las siguientes líneas no vamos a explicar cómo funciona Google App Engine ni su datastore, ya que para ello están los dos tutoriales anteriormente mencionados. Este tutorial tendrá un enfoque más técnico y en él nos centraremos en cómo utilizar el datastore con JDO, razón por la cual habrá una primera parte teórica en la que hablaremos de JDO y, tras ello, una parte práctica en la cual podreis descargar una aplicación de ejemplo que utiliza JDO contra el datastore.
2 ¿Qué es JDO?
Tras estas iniciales se esconden los ‘Java Data Objects’, lo que en castellano vendrían a ser los ‘objetos de datos de java’.
JDO es una especificación de almacenamiento de objetos en Java, la cual no se limita a lo que es el almacenamiento de datos en bases de datos relacionales únicamente, pudiendo utilizarse contra ficheros XML, documentos de OpenOffice, objetos JSON, etc. Esto facilita la integración entre JDO y el datastore ya que el datastore no utiliza un modelo relacional por debajo.
Lo que sí utiliza JDO por debajo, sin embargo, es el API de nivel inferior:
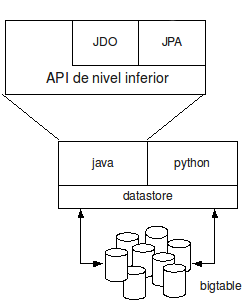
La documentación acerca de JDO en Google App Engine es bastante extensa, de hecho prácticamente toda la documentación existente acerca del uso del datastore mediante Java utiliza JDO:
El API Java de almacén de datos
Pero, ¿en qué puede sernos JDO de utilidad?. JDO permite que los desarrolladores pueden centrarse más en qué quieren buscar, modificar, borrar, etc. que en cómo. Es por ello que esta tecnología permite tener un grado de abstracción alto, claramente mayor al que tendríamos si tuvieramos que desarrollar nuestra aplicación con el API de nivel inferior, pero por contra perderemos el disponer de un control absoluto sobre lo que hacemos.
Del estándar JDO existen varias versiones, funcionando la 2.3 en Google App Engine y siendo la implementación una variante de DataNucleus Access Plataform. Sin embargo el soporte no es completo, esto es, hay funciones de JDO que no podremos utilizar si queremos hacer funcionar nuestra aplicación en Google App Engine.

2.1 Limitaciones de JDO sobre Google App Engine
He aqui la lista de incompatibilidades:
- 1- relaciones sin propiedad (puedes implementar relaciones sin propiedad a través de valores de Key explícitos; es posible que se admita la sintaxis de JDO para relaciones sin propiedad en una futura versión),
- 2- relaciones de propiedad varios a varios,
- 3- consultas con «Join», (no puedes utilizar un campo de una entidad secundaria en un filtro si realizas una consulta en la entidad principal; ten en cuenta que puedes comprobar el campo de relación de la entidad principal directamente en la consulta a través de una clave),
- 4- agrupación JDOQL y otras consultas agrupadas,
- 5- consultas polimórficas (no puedes realizar una consulta de una clase para obtener instancias de una subclase; cada clase está representada por un tipo de entidad independiente del almacén de datos),
- 6- IdentityType.DATASTORE para la anotación @PersistenceCapable (sólo se admite IdentityType.APPLICATION),
- 7- en la actualidad existe un error que evita que los campos persistentes se guarden en el almacén de datos; esto se solucionará en una futura versión.
Observad que la mayoría de ellas están relacionadas con lo que vienen a ser las relaciones entre las distintas entidades: no se pueden guardar relaciones sin que estén ambos extremos de la relación, no puede haber relaciones muchos a muchos y no se pueden hacer consultas con join. Esto tiene sentido si se piensa que por debajo se está utilizando BigTable.
Nosotros como desarrolladores deberemos tener en cuenta estas limitaciones en nuestros entornos de desarrollo. En desarrollo posiblemente podamos utilizar JDO sin tener estas limitaciones, pero debemos saber que hay ciertas cosas que no podemos dejar en nuestro software si queremos subirlo tal cual a la nube de Google App Engine en producción.
3 Objetos persistentes
Como comentamos en el tutorial acerca de cómo utilizar el datastore de Google App Engine, tanto JDO como el datastore utilizan un concepto llamado entidades. Sin embargo, este concepto es diferente entre entidades de JPO y las del datastore. Puesto que estos tutoriales están relacionados con el datastore vamos a mantener el nombre de entidad para las entidades del datastore y vamos a llamar objetos persistentes a las entidades de JDO.
Un objeto persistente es una clase java bastante simple, lo que por lo general se conoce como un POJO (una clase con atributos los cuales son accedidos mediante getters y setters) que puede ser almacenado en el datastore. Para poder indicarle a JDO cómo debe tratar a los objetos persistentes es necesario utilizar anotaciones. La implementación de JDO, por debajo, convertirá los objetos persistentes anotados en entidades con los que el datastore pueda operar.
3.1 Anotaciones
Sabemos que el datastore opera con entidades y que JDO opera con objetos persistentes. También sabemos que para convertir objetos persistentes en entidades necesitamos anotar dichos objetos. Sólo nos falta conocer las posibles anotaciones que podemos utilizar, las cuales son las siguientes:
@PersistenceCapable
Indica que una clase puede ser recuperada y almacenada mediante el soporte de JDO. Mirad la restricción 6 del apartado 2.1.
import javax.jdo.annotations.PersistenceCapable;
import javax.jdo.annotations.IdentityType;
@PersistenceCapable(identityType = IdentityType.APPLICATION)
public class Tutorial { ... }
@Persistent
Indica que queremos poder almacenar el campo de la entidad en el datastore.
import javax.jdo.annotations.Persistent; @Persistent private String autor;
El tipo de campo que podremos almacenar puede ser cualquiera de los que se indican a continuación:
- uno de los tipos principales compatibles con el almacén de datos,
- una colección (como, por ejemplo, java.util.List) o un conjunto de valores de tipo principal del almacén de datos,
- una instancia o colección de instancias de una clase @PersistenceCapable,
- una instancia o colección de instancias de una clase serializable (@Persistent(serialized = «true»)),
- una clase insertada y almacenada como propiedades de la entidad
@NotPersistent
Indica que queremos que el campo de la entidad no se almacene.
import javax.jdo.annotations.NotPersistent; @NotPersistent private String fechaFormateadaParaPresentacion;
Ahora bien, ¿cuál es el valor por defecto, @Persistent o @NotPersistent?. Bueno, pues depende del tipo de dato. Por lo general prácticamente todos los tipos de datos son persistentes a no ser que se diga lo contrario, ya que hay tipos de datos que por defecto no son persistentes. Podeis ver cuales son persistentes por defecto y cuales no en la siguiente dirección: http://www.datanucleus.org/products/accessplatform_1_1/jdo/types.html. En esta dirección vereis los tipos de datos y una columna llamada Persistent? que os indicará si el tipo de datos por defecto es persistente o no.
Los chicos de Google, por claridad, recomiendan poner anotaciones directamente en todas las variables que declaremos.
@PrimaryKey
Indica que el campo va a ser la clave primaria, e irá acompañada de la anotación @Persistent ya que la clave también será almacenada.
import javax.jdo.annotations.IdGeneratorStrategy; import javax.jdo.annotations.Persistent; import javax.jdo.annotations.PrimaryKey; @PrimaryKey @Persistent(valueStrategy = IdGeneratorStrategy.IDENTITY) private Long id;
En Google App Engine hay 4 maneras de definir claves primarias, y en función al tipo de datos de esta clave primaria hay que configurar la anotación @Persistent de una manera u otra. Más información aquí.
Las 4 maneras de definir claves primarias son las siguientes:
- Como objetos de tipo
Long, cuyo id se genera de manera automática. - Como objetos de tipo
String, cuyo id deberemos generar nosotros. - Como objetos de tipo
Keynumérico, cuyo id se genera de manera automática. - Como objetos de tipo
Keyrepresentados como una cadena, cuyo id se genera de manera automática.
Las claves primarias de tipo Long y String se utilizan en entidades fuertes, mientras que las claves de tipo Key son claves compuestas que contienen el id de la aplicación y el id de la entidad padre, utilizándose por tanto en entidades débiles.
@EmbeddedOnly y @Embedded
Se utilizan para insertar unas clases dentro de otras (ojo, esto no es relacionar clases, es insertar literalmente unas clases dentro de otras). No es un concepto nuevo ya que está presente en otras tecnologías como por ejemplo Hibernate.
La idea subyacente es la siguiente: es posible que tengamos entidades que manejen muchos campos, de tal modo que nos gustaría poder organizarlos de alguna manera con la que poder mejorar la legibilidad del código.
Imaginemos el caso de un coche. En un coche podemos guardar un montón de información relacionada con el dueño, con el seguro, con el estado del vehículo, con las revisiones que ha pasado, con las averias que ha sufrido, etc. Podemos poner toda esta información campo a campo en el coche o podemos dividirla en subclases: una será la clase Seguro, y en ella almacenaremos la información del seguro, otra será la clase Estado y en ella almacenaremos la información acerca del estado del coche, otra será Revisión y en ella almacenaremos la información acerca de las revisiones, etc. de tal modo que insertaremos (no relacionaremos) esta información en la clase Coche.
En la documentación oficial hay un ejemplo bastante claro de qué es y cómo insertar una clase dentro de otra.
3.2 Relaciones
Con el soporte de JDO puedes crear relaciones entre clases persistentes de manera sencilla, tan sólo debes referenciar a unas desde las otras. Las relaciones pueden ser de tipo 1:N o 1:1 con una navegabilidad tanto unidireccional como bidireccional, pero no se permiten las relaciones N:M (ver punto 2.1 de este mismo tutorial). Además en las relaciones 1:N y en las 1:1 puedes hacer que una sea la entidad débil y la otra la fuerte. Las entidades fuertes son aquellas que tienen sentido por si mismo, por ejemplo pacientes o médicos, mientras que las débiles son aquellas que necesitan de una fuerte para existir, por ejemplo las visitas del paciente.
En el ejemplo anterior podriamos tener pacientes sin visitas ni médicos asignados, al igual que podriamos tener médicos sin pacientes. Lo que no tendría sentido sería tener visitas sin pacientes.
En el Google App Engine, si se borra una entidad fuerte, se borran en cascada todas las entidades débiles que tuvieran relación con ella. Si borramos a un paciente borraríamos automáticamente todas sus visitas, pero no a su médico. Y si borramos una visita, no borraríamos ni al paciente ni a su médico.
Cabe tambien mencionar que al relacionar entidades entre sí crearemos lo que se conoce como un grupo de entidades, lo cual afectará a la transaccionalidad, ya que las operaciones realizadas sobre cualquiera de las entidades del grupo de entidades actuan de manera transaccional sobre todas las entidades del grupo de entidades.
Puedes acceder a la documentación oficial que trata este tema de las relaciones pulsando aquí.
3.2.1 Relaciones 1:N
Podeis acceder a la documentación oficial pulsando aquí.
Si quereis relacionar una entidad con varias, por ejemplo a una persona con varios coches, lo que debereis hacer es crear un campo de tipo ‘persona’ en la clase Coche y un campo que sea una lista de tipo ‘coche’ en la clase Persona.
import javax.jdo.annotations.Persistent;
@PersistenceCapable(identityType = IdentityType.APPLICATION)
public class Coche {
@PrimaryKey
@Persistent(valueStrategy = IdGeneratorStrategy.IDENTITY)
private Long id;
@Persistent
private Persona persona;
...
}
import javax.jdo.annotations.Persistent;
@PersistenceCapable(identityType = IdentityType.APPLICATION)
public class Persona {
@PrimaryKey
@Persistent(valueStrategy = IdGeneratorStrategy.IDENTITY)
private Long id;
@Persistent
private List coches;
...
}
Con esto lo que se consigue es indicar que una persona puede tener varios coches, mientras que un coche sólo puede ser poseido por una persona. Ambas son entidades fuertes puesto que ambas tienen un id de tipo Long, y a su vez ambas forman parte del mismo grupo de objetos persistentes.
También podemos indicar qué ordenación vamos a querer en los coches. Esto es, podemos indicar en qué orden queremos almacenar y recuperar los coches de una persona en el datastore.
import javax.jdo.annotations.Persistent;
@PersistenceCapable(identityType = IdentityType.APPLICATION)
public class Persona {
@Persistent
@Order(extensions = @Extension(vendorName="datanucleus", key="list-ordering", value="matricula asc"))
private List coches;
...
}
En este caso estaríamos ordenando los coches de una persona por matrícula en orden ascendente.
3.2.2 Relaciones 1:1
Podeis acceder a la documentación oficial pulsando aquí.
Si quereis relacionar una entidad con otra, por ejemplo a un emplado con un empleo, haciendo que una entidad sea fuerte y la otra débil, habría que crear una relación entre los objetos persistentes como la que sigue:
import javax.jdo.annotations.IdentityType;
import javax.jdo.annotations.IdGeneratorStrategy;
import javax.jdo.annotations.PersistenceCapable;
import javax.jdo.annotations.Persistent;
@PersistenceCapable(identityType = IdentityType.APPLICATION)
public class Empleado {
@PrimaryKey
@Persistent(valueStrategy = IdGeneratorStrategy.IDENTITY)
private Long id;
@Persistent
private Empleo empleo;
...
}
import javax.jdo.annotations.IdentityType;
import javax.jdo.annotations.IdGeneratorStrategy;
import javax.jdo.annotations.PersistenceCapable;
import javax.jdo.annotations.Persistent;
@PersistenceCapable(identityType = IdentityType.APPLICATION)
public class Empleo {
@PrimaryKey
@Persistent(valueStrategy = IdGeneratorStrategy.IDENTITY)
private Key key;
@Persistent(mappedBy = "empleo")
private Empleado empleado;
...
}
Con esto lo que conseguiremos es que la clave de la entidad débil, en este caso Empleo, utilice automáticamente la clave de Empleado. De este modo conseguimos relacionar empleados y empleos haciendo que Empleo sea una entidad débil de Empleado. Fijaros en que la clave de Empleado es de tipo Long mientras que la clave de Empleo es de tipo Key.
También hay que tener en cuenta lo siguiente: si nuestra aplicación necesitase recuperar la entidad débil, es decir, el Empleo, se recuperaría, además, la información de Empleado de manera implícita. En el caso contrario, si necesitasemos recuperar al Empleado, no recuperariamos la información del Empleo a no ser que lo indicásemos explícitamente.
4 Cómo operar con los datos
A continuación vamos a mostrar cómo se pueden realizar las operaciones sobre los registros, lo que habitualmente se conoce como las operaciones del CRUD (create, read, update, delete)
Para poder realizar todas estas operaciones necesitaremos utilizar al gestor de persistencia de JDO. El gestor de persistencia es un pilar importante ya que es quien se encarga de hacer el cómo de nuestros qué, esto es, nosotros queremos realizar operaciones, se las indicaremos al gestor de persistencia y él se encargará de saber cómo hacerlo. Si quisiesemos almacenar un objeto persistente tan sólo deberemos indicarle que queremos guardarlo y él se encargará de realizar las operaciones oportunas para almacenarlo en el datastore.
Es importante destacar también que el gestor de persistencia se va a encargar de gestionar el ciclo de vida de los objetos persistentes.
Más información sobre el gestor de persistencia.
4.1 Create (creación)
Para poder guardar un objeto persistente en el datastore es necesario ejecutar el método makePersistent() del gestor de persistencia.
final PersistenceManager gestorPersistencia = PersistenceManagerFactory.getInstance().getPersistenceManager();
final Tutorial tutorial = new Tutorial("adictosaltrabajo", "Google App Engine", "nivel medio");
try {
gestorPersistencia.makePersistent(e);
} finally {
gestorPersistencia.close();
}
Podeis acceder a la documentación oficial pulsando aquí.
4.2 Read (lectura)
Para poder recuperar un objeto persistente del datastore es necesario ejecutar el método getObjectById() del gestor de persistencia.
final PersistenceManager gestorPersistencia = PersistenceManagerFactory.getInstance().getPersistenceManager(); final Tutorial tutorial = gestorPersistencia.getObjectById(Tutorial.class, "Google App Engine");
Tambien podeis utilizar JDOQL como indicamos en el apartado 5 de este mismo tutorial.
Podeis acceder a la documentación oficial pulsando aquí.
4.3 Update (actualización)
Lo primero que necesitaremos es recuperar el objeto persistente que queremos modificar y, tras ello, modificarlo. No será necesario indicar explícitamente que queremos almacenar los cambios en base de datos ya que el gestor de persistencia se encargará de ello al gestionar el ciclo del vida del objeto persistente.
final PersistenceManager gestorPersistencia = PersistenceManagerFactory.getInstance().getPersistenceManager();
try {
final Tutorial tutorial = gestorPersistencia.getObjectById(Tutorial.class, "Google App Engine");
tutorial.setNivel ("nivel bajo");
} finally {
pm.close();
}
Podeis acceder a la documentación oficial pulsando aquí.
4.4 Delete (borrado)
Lo primero que necesitaremos es recuperar el objeto persistente que queremos borrar y, tras ello, borrarlo. Para ello utilizaremos el método deletePersistent() del gestor de persistencia.
final PersistenceManager gestorPersistencia = PersistenceManagerFactory.getInstance().getPersistenceManager(); final Tutorial tutorial = gestorPersistencia.getObjectById(Tutorial.class, "Google App Engine"); gestorPersistencia.deletePersistent (tutorial);
Hay que tener en cuenta que si se borra una entidad fuerte que tenía otras entidades débiles relacionadas se realizará un borrado en cascada, es decir, al borrar a la fuerte se borrarán las débiles con ella.
Podeis acceder a la documentación oficial pulsando aquí y aquí.
5 Cómo realizar consultas
Las consultas se utilizan con el objetivo de poder recuperar objetos persistentes de, en este caso, el datastore. Recuperaremos unos objetos persistentes u otros en función a los criterios de búsqueda que utilicemos y ordenados según los criterios de ordenación que empleemos.
Podeis acceder a la documentación oficial pulsando aquí.
Para poder realizar esta labor JDO posee un lenguaje de consultas llamado JDOQL. A diferencia del lenguaje SQL, JDOQL devuelve objetos persistentes en vez de tuplas con datos.
Este lenguaje posee varias maneras de ser ejecutado. Los códigos que vas a ver a continuación, por ejemplo, son equivalentes:
final Query query = persistenceManager.newQuery(Tutorial.class);
query.setFilter("nombreTutorial == nombreTutorialParam");
query.setOrdering("fecha DESC");
query.declareParameters("String nombreTutorialParam");
query.execute("Google App Engine");
final Query query = persistenceManager.newQuery("select from Tutorial where nombreTutorial == nombreTutorialParam order by fecha DESC parameters String nombreTutorialParam");
query.execute("Google App Engine");
Con esta consulta estamos recuperando todos los tutoriales cuyo nombre se recibe por parámetro ordenados por fecha en orden descendente. Como el parámetro que se recibe es ‘Google App Engine’, estaríamos recuperando todos los tutoriales de nombre ‘Google App Engine’ ordenados por fecha en orden descendente.
Es importante destacar que el datastore mantiene varios índices en nuestros datos. A medida que la aplicación realiza cambios en las entidades del datastore éste actualiza los índices para extraer los resultados directamente del índice correspondiente cuando la aplicación ejecute una consulta. Esto es bastante sensato, ya que el datastore está pensando para poder recuperar información muy rápidamente.
6 Transacciones
Podeis acceder a la documentación oficial pulsando aquí.
Una transacción, según la wikipedia, es:
«[…] una interacción con una estructura de datos compleja, compuesta por varios procesos que se han de aplicar uno después del otro. La transacción debe ser equivalente a una interacción atómica. Es decir, que se realice de una sola vez y que la estructura a medio manipular no sea jamás alcanzable por el resto del sistema hasta que haya finalizado todos sus procesos.»
http://es.wikipedia.org/wiki/Transacción_(informática)
Según la misma fuente, las transacciones deben cumplir 4 propiedades para poder ser consideradas como tal. A estas propiedades se las conoce como ACID y lo que aseguran es que o se aplica el resultado de todas las operaciones englobadas dentro de una misma transacción o no se aplica el de ninguna.
El datastore es transaccional, lo que hace que sea consecuente y evita que se den inconsistencias en los datos.
La transaccionalidad en el datastore puede conseguirse de dos maneras:
- Declarando explícitamente los márgenes de la transacción, utilizando para ello el API de JDO.
- Creando grupos de entidades, lo que vendría a ser una declaración implícita.
La declaración explícita, como podeis ver, es bastante simple de utilizar:
final PersistenceManager gestorPersistencia = PersistenceManagerFactory.getInstance().getPersistenceManager();
final Transaction transaccion = gestorPersistencia.currentTransaction();
try {
transaccion.begin();
// hacer lo que sea
transaccion.commit();
} finally {
if (transaccion.isActive()) {
transaccion.rollback();
}
}
Donde:
transaccion.begin()inicia la transacción.transaccion.commit()hace que se apliquen los cambios efectuados desde que se inició la transacción y que ésta termine.transaccion.rollback()hace que se deshagan los cambios efectuados desde que se inició la transacción y que ésta termine.
Todas las operaciones de escritura en el datastore son atómicas, lo que permite que nuestros datos siempre se encuentren en un estado consistente. Una operación de modificación o de creación puede producirse completamente o no producirse en absoluto.
Para poder conseguir una declaración implícita necesitaremos crear un grupo de entidades. Para ello deberás relacionarlas como indicamos en el apartado 3.2 de este tutorial.
6.2 Acciones no permitidas en el ámbito de una transacción
Podeis acceder a la documentación oficial pulsando aquí.
Hay una serie de acciones que no podreis realizar mientras os encontreis en una transacción activa. Dichas acciones son las siguientes:
- Puesto que cada grupo de entidades maneja una transacción propia no se pueden guardar objetos de más de un grupo de entidades en una misma transacción, con lo que no podrás asegurar que en una misma operación puedas almacenar entidades de más de un grupo de entidades. Como podreis ver es una limitación importante, aunque siempre podrás utilizar la lógica de la aplicación para controlar estos casos.
- No es posible recuperar objetos persistentes mediante consultas cuando te encuentras en medio de una transacción, aunque sí puedes recuperarlos por id sin tener ningún problema. Esto estaría vinculado con las declaración explícita de transacciones. Si vas a necesitar lanzar una consulta debes asegurarte de lanzarla fuera del ámbito de una transacción.
- No es posible crear ni actualizar el mismo objeto persistente más de una vez en una misma transacción. Esto es lógico ya que por un lado los objetos sólo pueden ser creados una vez, y por otro cada vez que actualizamos lo que hacemos es crear nuevas entidades del datastore. Si actualizamos más de una vez estaríamos, sin ser conscientes de ello, tratando de guardar entidades en el datastore a las que no vamos a poder acceder nunca.
Sin embargo JDO tiene multitud de excepciones que podremos capturar en cada caso y obrar en consecuencia para solucionar los posibles problemas que nos podamos encontrar.
Entonces, ¿para qué sirve la transaccionalidad explícita?. No puedo crear una transacción explícita, operar con grupos de entidades, cerrarla y dar por sentado que todas las entidades se han guardado correctamente, no puedo lanzar consultas dentro de ellas y no puedo guardar cambios todas las veces que quiera, ¿qué utilidad tiene?.
JDO utiliza una política optimista, así que presupone que cuando vayamos a guardar no se van a producir estos problemas, pero, ¿y si ocurren?, ¿no es mejor englobar las operaciones más importantes dentro de una transacción explícita?. De este modo podremos utilizar detectar el problema y utilizar la lógica de negocio para tratar de resolverlo.
7 Ejemplo con JDO
Igual que en el tutorial en el cual os explicábamos cómo utilizar el datastore de Google App Engine con el API de nivel inferior, en este también hemos generado una pequeña aplicación de ejemplo encargada de gestionar tutoriales. La aplicación en realidad es la misma, cambiando únicamente la manera de utilizar el datastore, ya que hemos migrado la capa que utilizaba el API de nivel inferior a una capa que utiliza JDO.
Podeis descargar el código fuente de la aplicación pulsando en este enlace.
Si quieres montar el entorno de desarrollo, por favor, sigue el apartado 6 del tutorial mencionado anteriormente.
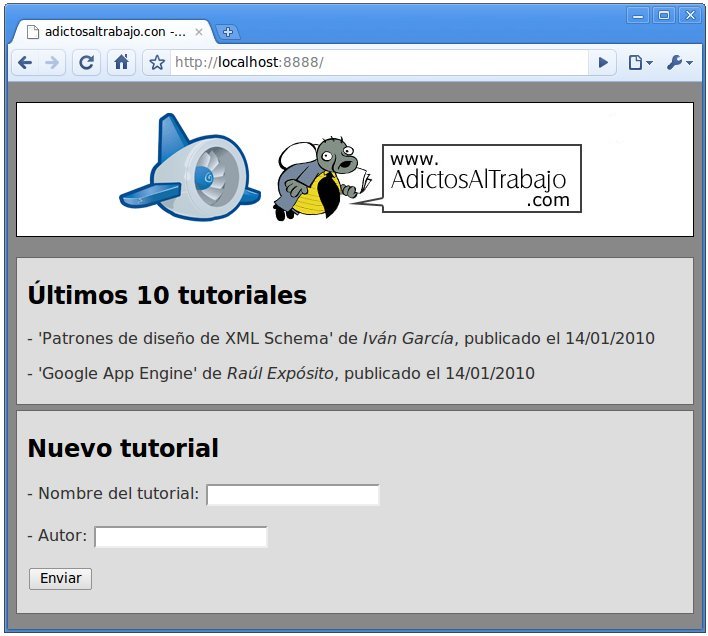
7.1 Estructura del proyecto y cambios
Los cambios se han aplicado únicamente a la capa de persistencia. La clase DSF, que era la factoria encargada de facilitarnos acceso directo al datastore ha sido modificada por la clase PMF, que es una factoria encargada de facilitarnos acceso al gestor de persistencia. Es en detalles como estos donde te das cuenta que estás subiendo el nivel de abstracción: hemos pasado de acceder directamente al datastore a disponer de un gestor de persistencia.
También se ha cambiado la clase Tutorial. Antes era una clase que envolvía una entidad del API de nivel inferior y ahora ha pasado a ser un objeto persistente que se encuentra anotado.
Finalmente ha habido cambios en la clase TutorialUtils. Esta clase ha visto cómo su código se reducía ya que las operaciones de búsqueda e inserción de las que se encargaba se realizan ahora en el gestor de persistencia.
Es por ello que el código queda como sigue:
- La factoría encargada de facilitarnos acceso al gestor de persistencia, llamada PMF. Es un singleton para asegurarnos de que no hay más que una factoría de gestores de persistencia ya que crear dicha factoría es computacionalmente bastante costoso.
package com.autentia.adictosaltrabajo.gae.persistence;
import javax.jdo.JDOHelper;
import javax.jdo.PersistenceManagerFactory;
public final class PMF {
private static final PersistenceManagerFactory pmfInstance = JDOHelper
.getPersistenceManagerFactory("transactions-optional");
private PMF() {
}
public static PersistenceManagerFactory get() {
return pmfInstance;
}
}
package com.autentia.adictosaltrabajo.gae.persistence;
import java.text.SimpleDateFormat;
import java.util.Date;
import javax.jdo.annotations.IdGeneratorStrategy;
import javax.jdo.annotations.IdentityType;
import javax.jdo.annotations.PersistenceCapable;
import javax.jdo.annotations.Persistent;
import javax.jdo.annotations.PrimaryKey;
@PersistenceCapable(identityType = IdentityType.APPLICATION)
public class Tutorial {
@PrimaryKey
@Persistent(valueStrategy = IdGeneratorStrategy.IDENTITY)
private Long id;
@Persistent
private String autor;
@Persistent
private String tutorial;
@Persistent
private Date fecha;
private static SimpleDateFormat formatter = new SimpleDateFormat("dd/MM/yyyy");
// -------------------------------- //
// constructores //
// -------------------------------- //
public Tutorial(final String autor, final String tutorial) {
this.autor = autor;
this.tutorial = tutorial;
this.fecha = new Date();
}
// --------------------------------------- //
// getters de los atributos de la entidad //
// y de la propia entidad //
// --------------------------------------- //
public String getAutor() {
return autor;
}
public String getTutorial() {
return tutorial;
}
public Date getFecha() {
return fecha;
}
public String getFechaFormatted() {
return formatter.format(fecha);
}
}
package com.autentia.adictosaltrabajo.gae.persistence;
import java.util.List;
import javax.jdo.PersistenceManager;
import javax.jdo.Query;
public class TutorialUtils {
private static final int FETCH_MAX_RESULTS = 10;
/**
* Almacenamiento de un nuevo tutorial
* @param autor nombre del autor
* @param tituloTutorial titulo del tutorial
*/
public static void insert(final String autor, final String tituloTutorial) {
// recuperacion del gestor de persistencia de JDO
final PersistenceManager persistenceManager = PMF.get().getPersistenceManager();
// creamos un nuevo tutorial y los insertamos en el datastore
final Tutorial tutorial = new Tutorial(autor, tituloTutorial);
persistenceManager.makePersistent(tutorial);
}
/**
* Recuperación de los últimos 10 tutoriales (FETCH_MAX_RESULTS)
* @return una lista con los últimos 10 tutoriales
*/
@SuppressWarnings("unchecked")
public static List getEntries() {
// recuperación del gestor de persistencia de JDO
final PersistenceManager persistenceManager = PMF.get().getPersistenceManager();
// generación de la consulta y configuración de la ordenación de los resultados de la misma
final Query query = persistenceManager.newQuery(Tutorial.class);
query.setOrdering("fecha DESC");
query.setRange(0, FETCH_MAX_RESULTS);
// devolución de resultados
return (List) query.execute();
}
}
Como podeis ver la cantidad de código a escribir es menor y, sobre todo, es más legible.
8 Conclusiones
A lo largo de este tutorial hemos podido ver qué es JDO, qué ventajas aporta, qué inconvenientes tiene y cómo podemos utilizarlo desde nuestros desarrollos teniendo en mente que luego estas aplicaciones van a encontrase en Google App Engine.
También hemos podido ver qué diferencias hay entre las entidades y los objetos persistentes, explicando cómo anotar estos últimos para poder almacenarlos en el datastore, cómo poder relacionar los unos con los otros, cómo poder definir los márgenes de las transacciones, etc.
Finalmente os hemos entregado el código fuente de un proyecto que usa JDO en vez del API de nivel inferior para que podais modificarlo a vuestro gusto. También os hemos explicado las diferencias entre ambos estilos para que las veais en un caso práctico y sencillo y podais decidir cual os conviene más.
9 Referencias
¿Qué son el Cloud Computing y Google App Engine?
¿Cómo utilizar el datastore de Google App Engine con el API de nivel inferior?
Java Data Objects (JDO)
API de JDO 2.3
El API Java de almacén de datos
Definición de las clases de datos


Quiero agradecer el tiempo que has tomado para preparar y presentar este tutorial, ha sido de una invaluable ayuda.
Te deseo muchas bendiciones.
Muchas Gracias por el tutorial. Me surge la necesidad de tener que compartir los datos almacenados en datastores para que sean visibles con otras aplicaciones. es posible realizar esta funcion
Buen tutorial! pero tengo una pregunta.
En una aplicación donde, por ejemplo, un usuario con sus respectivos campos, tiene una relacion por ejemplo, un libro de visitas, es decir, la clase usuario tiene un \\\»@Persistent List guestbook;\\\»… cada vez que obtienes el usuario, obtienes tambien tooodos sus mensajes del libro e visitas.
Y la pregutna es… no será muy ineficiente, si por ejemplo solo quiero obtener los nombres de usuarios en una consulta, y me está evolviendo todos los datos, incluido el libro de visitas, donde puede tener miles de mensajes, por cada usuario?
Hay alguna manera de evitar esto? cual seria el proceder en un caso como este?
Muchas gracias.
Hola déjame darte la gracias por la información está bien detallado, sobre el DATASTORE y la API de nivel inferior, haciendo registros.
Bueno ahora quisiera saber como seria el código si es que quisiera eliminar, modificar y buscar dichos registro en una tabla. Que debería agregar en TutorialUtil, Tutorial, TutorialServlet, tutoriales.jsp etc. GRACIAS