
CÓMO UTILIZAR EL DATASTORE DE GOOGLE APP ENGINE CON SU API DE NIVEL INFERIOR
1 Introducción
En un tutorial anterior os explicamos qué son el cloud computing y Google App Engine, donde os mostramos en qué consisten estas tecnologías, de qué capas están formadas y cuáles son las ventajas que nos aportan. Aquel introductorio tutorial nos servirá como base para este otro, donde nos centraremos en un apartado del Google App Engine en concreto: su almacén de datos, también como conocido como el datastore.
Todas las aplicaciones web necesitan algún tipo de soporte de almacenamiento de datos, es por ello que conocer el funcionamiento del datastore es realmente importante si quieres publicar tus aplicaciones utilizando la plataforma de Google App Engine.

El texto que vas a leer a continuación va a intentar que entiendas cómo funciona el datastore. Habrá una primera parte puramente teórica con la cual podremos situarnos y, tras ello, una parte práctica en la cual podreis descargar una aplicación de ejemplo. Dicha aplicación está escrita en java y hace uso del API de nivel inferior del datastore.
2 ¿Qué es el datastore?
El datastore es una parte vital de Google App Engine, destinada únicamente al almacenamiento de datos. Eso significa que todos los datos que necesitemos almacenar o recuperar los tendremos allí.
Es importante destacar que bajo el datastore no hay una base de datos relacional. Sirve para almacenar datos de un manera totalmente consecuente pero no funciona como las bases de datos tipo MySQL u Oracle. Aunque el concepto de almacenar y recuperar datos es el mismo, las tecnologías y la manera de trabajar son diferentes, lo que implica que tendrán distintos puntos fuertes y distintos puntos débiles.
Pero, ¿hasta qué punto las tecnologías son distintas?, ¿por qué los chicos de Google no han basado sus tecnologías en otras ya existentes?. Como mencionamos en el tutorial de introducción al cloud computing y a Google App Engine, Google posee unas tecnologías propias basadas en GFS y en BigTable. El primero es un sistema de ficheros propio, mientras que el segundo es un sistema de almacenamiento de información distribuido diseñado para almacenar cantidades de datos del tamaño de petabytes en miles de ordenadores.
¿Y qué diferencia hay entre unas tecnologias y otras?. Tanto GFS como BigTable han sido diseñadas específicamente para poder funcionar de manera distribuida en datacenters con cientos y miles de ordenadores en forma de grid donde, además, se entiende que la mayoría de operaciones que se realizan son lecturas en un espacio de almacenamiento infinito sobre un hardware que puede fallar en cualquier momento.
El datastore es, simplemente, una capa que se sitúa sobre BigTable. Todas las operaciones que realicemos sobre este sistema de almacenamiento tendrán que ser invocadas contra el datastore.
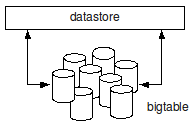
BigTable fue diseñado pensando, entre otras cosas, en la escalabilidad. Es por ello que conceptos propios de las bases de datos relacionales como la normalización o las claves foráneas no existen. En BigTable cuando existe una relación entre datos y se guarda uno de ellos lo que en realidad se hace es guardar los dos juntos como si ambos fueran uno solo. Esto permite escalar y simplificar las búsquedas, ya que al ir a buscar uno de los datos se recuperan los dos sin obligar a BigTable a lanzar una segunda búsqueda utilizando una clave foránea.
3 ¿Qué podemos utilizar para almacenar y recuperar información del datastore?
Actualmente Google da soporte para dos lenguajes diferentes en su Google App Engine: java y python. Es por ello que todas las operaciones que queramos realizar contra el Google App Engine en general y contra el datastore en particular tendrán que utilizar alguno de estos dos lenguajes:
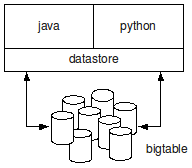
Nosotros, a lo largo de estos tutoriales, nos vamos a centrar en el desarrollo de aplicaciones mediante el lenguaje de programación java. Utilizando este lenguaje dispondremos de tres maneras de poder operar con el datastore:
- JDO (Java Data Objects)
- JPA (Java Persistence API)
- El API de nivel inferior
Donde API son las siglas de Application Programming Interface.
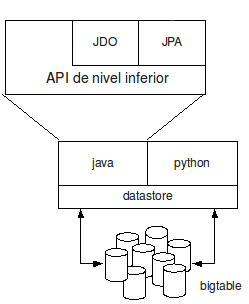
Como podeis ver en la imagen, tanto JDO como JPA utilizan el API de nivel inferior para poder hacer uso del datastore debido a que JDO y JPA poseen un mayor nivel de abstracción. Eso no es obstáculo para que nosotros como desarrolladores también podamos acceder al API de nivel inferior para construir nuestras aplicaciones.
Este tutorial gira en torno al API de nivel inferior puesto que mantiene una relación más estrecha con el datastore y porque comprender cómo funciona este API nos permitirá saber mejor cómo funciona el datastore.
3.1 API de nivel inferior
Es el interfaz de programación de aplicaciones de nivel inferior. Se dice que es de nivel inferior ya que es la capa de almacenamiento de datos que se encuentra más cerca del datastore.
Este API opera con datos y con operaciones relativamente primitivos. Al programar con este API hay que ser explícito ya que es necesario indicar no sólo qué quieres almacenar o recuperar sino cómo quieres hacerlo.
Este API, al igual que el propio datastore, opera con entidades. Las entidades son objetos de datos y se explicarán en el apartado 4 de este mismo tutorial. Si conoces JDO o JPA debes tener en cuenta que las entidades del datastore no son como las entidades de JDO o JPA. Las entidades del datastore son lo que en java se conoce como mapas, pares atributo-valor.
La ventaja de trabajar contra esta API es que permite tener un mayor control a costa de tener que comprender mejor cómo funciona el datastore.
3.2 JPA
Es el ‘API de persistencia para Java’, o ‘interfaz de programación de aplicaciones de persistencia para Java’.
Este interfaz define un estándar de almacenamiento de datos en una base de datos relacional que, en este caso, se encuentra adaptado para poder almacenar datos en el datastore (recordemos que el datastore no es una base de datos relacional). Debido a esta adaptación, el soporte de Google App Engine para JPA no admite algunas funciones de JPA.
Del estándar JPA existen varias versiones, de las cuales de momento sólo la 1.0 funciona en Google App Engine y, como ya decimos, con restricciones.
Pero, ¿para qué sirve este estándar y qué ventaja podemos sacar de usar JPA en nuestras aplicaciones?, sirve para definir un marco de trabajo con un nivel de abstracción alto que, mediante la anotación de objetos Java, permita que la recuperación de objetos a través de consultas, que el almacenamiento de las mismas y que la interacción con una base de datos a través de transacciones sea bastante sencilla. Gracias a ello los desarrolladores pueden centrarse más en el qué quieren almacenar o recuperar que en el cómo tienen que hacerlo.
3.3 JDO
Son los ‘objetos de datos de java’ y también consiste en una especificación de almacenamiento de objetos en Java.
Tiene muchas similitudes y algunas diferencias con JPA. La idea de definir un marco de trabajo a un alto nivel de abstracción se mantiene, pero JDO no se centra en almacenar datos en bases de datos relacionales. JDO encaja, por tanto, mejor que JPA con el datastore ya que el éste no es relacional. Sin embargo tambien se encuentra limitado y no podremos utilizar todas las funciones de JDO en nuestra aplicación si esta tiene que funcionar en Google App Engine.
Del estándar JDO también existen varias versiones, funcionando la 2.3 en Google App Engine y, como ya decimos, con algunas restricciones.
4 ¿Qué son las entidades?
Anteriormente comentamos que el datastore opera con lo que se denominan entidades, y también comentamos que este concepto de entidad es diferente al concepto de entidad que existe en JDO y JPA.
Las entidades del datastore son objetos de datos con propiedades, pudiendo estas propiedades ser casi cualquier cosa: textos, números, valores binarios, conjuntos de datos, etc.
Lo exótico del asunto es que las propiedades pueden tener uno o varios valores, y además las entidades de un mismo tipo no tienen por qué tener las mismas propiedades, ya que cada entidad puede definir qué propiedades tiene. Esto se debe a que las entidades en el datastore son pares atributo-valor.
De esta manera podriamos definir entidades de tipo persona que tuvieran sólo coche y casa y entidades de tipo persona que tuvieran sólo mascota y edad. Los atributos son totalmente diferentes, pero para el datastore son entidades del mismo tipo.
Esto en un modelo relacional o en las entidades de JDO o JPA no es posible. Se podría intentar simular pero no se podría conseguir de manera nativa con facilidad.
Las entidades del datastore mantienen una clave que las identifica de manera única. Estas claves tienen varios valores, siendo uno de ellos precisamente el tipo de la entidad que representa.
Por tanto, cuando utilicemos el API de nivel inferior operaremos con entidades del datastore y podremos añadir todas las propiedades que necesitemos con todos los valores que hagan falta. Al utilizar JDO o JPA ganaremos en facilidad pero nos limitaremos a lo que nos permitan perdiendo estas novedosas características.
5 Transaccionalidad
Una transacción, según la wikipedia, es:
«[…] una interacción con una estructura de datos compleja, compuesta por varios procesos que se han de aplicar uno después del otro. La transacción debe ser equivalente a una interacción atómica. Es decir, que se realice de una sola vez y que la estructura a medio manipular no sea jamás alcanzable por el resto del sistema hasta que haya finalizado todos sus procesos.»
http://es.wikipedia.org/wiki/Transacción_(informática)
Según la misma fuente, las transacciones deben cumplir 4 propiedades para poder ser consideradas como tal. A estas propiedades se las conoce como ACID
- «Atomicidad (Atomicity): es la propiedad que asegura que la operación se ha realizado o no, y por lo tanto ante un fallo del sistema no puede quedar a medias.
- Consistencia (Consistency): es la propiedad que asegura que sólo se empieza aquello que se puede acabar. Por lo tanto, se ejecutan aquellas operaciones que no van a romper la reglas y directrices de integridad de la base de datos.
- Aislamiento (Isolation): es la propiedad que asegura que una operación no puede afectar a otras. Esto asegura que la realización de dos transacciones sobre la misma información nunca generará ningún tipo de error.
- Permanencia (Durability): es la propiedad que asegura que una vez realizada la operación, ésta persistirá y no se podrá deshacer aunque falle el sistema.»
El concepto de transaccionalidad tambien existe en el datastore de Google App Engine, ya que vamos a ser capaces de lanzar varias operaciones en una misma transacción y recuperar la transacción entera si falla cualquiera de las operaciones. Recordemos que en el apartado 2 dijimos que el datastore era totalmente consecuente.
Pero, ¿cómo poder definir qué entra y qué no entra en una misma transacción?. Anteriormente mencionamos que el datastore opera con entidades. Pues bien, si necesitamos operar con varias entidades a la vez de manera transaccional es necesario que todas ellas pertencezcan a un mismo grupo de entidades. De este modo grupos de entidades distintos operan con transacciones independientes.
Otro aspecto a tener en cuenta es que el almacén de datos utiliza una política optimista para gestionar las transacciones. Esto es lógico, ya que tanto GFS como BigTable han sido diseñados para que sobre ellos se realicen muchas más búsquedas que escrituras.
6 Ejemplo con API de nivel inferior
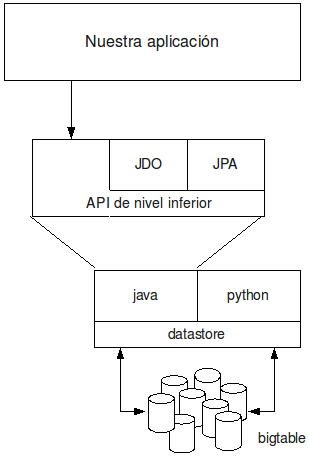
A continuación os vamos a mostrar un ejemplo realizado con el API de nivel inferior. Podeis bajar el código fuente del mismo pulsando en este enlace.
La aplicación será un gestor de tutoriales para adictosaltrabajo.com, en el cual podreis publicar nuevos tutoriales y consultar todos los que ya existen.
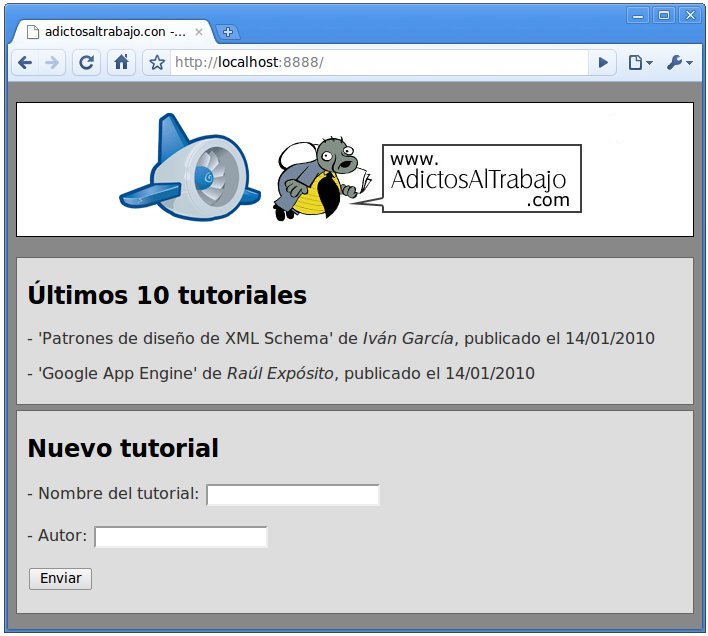
6.1 Cómo instalar el SDK para Java y el plugin de Eclipse
Lo primero que necesitamos es tener Java instalado en nuestro equipo, y también necesitaremos tener instalado Eclipse para poder desarrollar. El fuente de este tutorial ha sido generado con la versión 3.5 de Eclipse, también llamada Galileo.
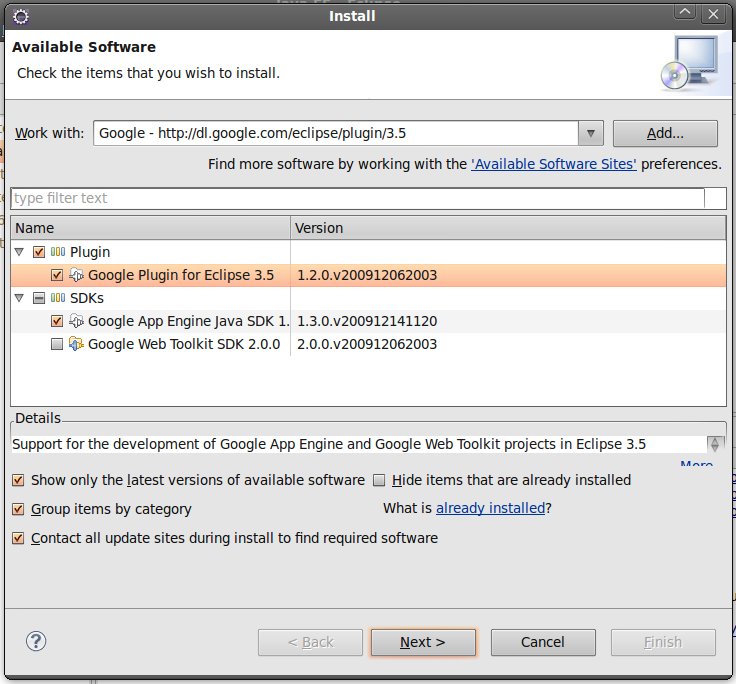
Necesitaremos instalar el plugin de Eclipse. Para ello nos basaremos en el siguiente enlace:
IMPORTANTE: Si estás usando Eclipse Galileo la ruta que deberás utilizar es http://dl.google.com/eclipse/plugin/3.5
Tras ello descomprimimos el código fuente del ejemplo. Si todavia no lo has bajado puedes hacerlo pulsando en este enlace.
Una vez tengas:
- Java,
- Eclipse y
- el plugin de Eclipse
podemos importar el proyecto en nuestro workspace de Eclipse. Para ello vamos a [ File > Import > General > Existing Projects into Workspace ] y una vez ahí seleccionamos el directorio con el ejemplo descomprimido.
Para ejecutarlo seguiremos las indicaciones publicadas en esta dirección: http://code.google.com/intl/es/appengine/docs/java/tools/eclipse.html#Running_the_Project
6.2 Estructura del proyecto
Nos vamos a encontrar dos capas bien diferenciadas: la primera va a ser la capa con la lógica y la persistencia mientras que la segunda se va a encargar de gestionar la interfaz.
La capa con la lógica y la persistencia está formada por tres clases:
- La factoría encargada de crear servicio del datastore, llamada DSF. Es un singleton para asegurarnos de que no hay más que una factoria, ya que crear el servicio del datastore es computacionalmente bastante costoso.
http://code.google.com/intl/es/appengine/docs/java/javadoc/com/google/appengine/api/datastore/DatastoreServiceFactory.html
http://code.google.com/intl/es/appengine/docs/java/javadoc/com/google/appengine/api/datastore/DatastoreService.html
package com.autentia.adictosaltrabajo.gae.persistence;
import com.google.appengine.api.datastore.DatastoreService;
import com.google.appengine.api.datastore.DatastoreServiceFactory;
public class DSF {
private static final DatastoreService INSTANCE = DatastoreServiceFactory
.getDatastoreService();
public static DatastoreService getDatastoreService() {
return INSTANCE;
}
private DSF() {
}
}
http://code.google.com/intl/es/appengine/docs/java/javadoc/com/google/appengine/api/datastore/Entity.html
http://code.google.com/intl/es/appengine/docs/java/javadoc/com/google/appengine/api/datastore/Key.html
package com.autentia.adictosaltrabajo.gae.persistence;
import java.text.SimpleDateFormat;
import java.util.Date;
import com.google.appengine.api.datastore.Entity;
public class Tutorial {
public static final String TUTORIAL_ENTITY = "Tutorial";
public static final String AUTOR = "autor";
public static final String TUTORIAL = "tutorial";
public static final String FECHA = "fecha";
private static SimpleDateFormat formatter = new SimpleDateFormat("dd/MM/yyyy");
private Entity entity = new Entity (TUTORIAL_ENTITY);
// -------------------------------- //
// constructores //
// -------------------------------- //
public Tutorial(final String autor, final String tutorial) {
entity.setProperty(AUTOR, autor);
entity.setProperty(TUTORIAL, tutorial);
entity.setProperty(FECHA, new Date());
}
public Tutorial(final String autor, final String tutorial, final Date fecha) {
entity.setProperty(AUTOR, autor);
entity.setProperty(TUTORIAL, tutorial);
entity.setProperty(FECHA, fecha);
}
// --------------------------------------- //
// getters de los atributos de la entidad //
// y de la propia entidad //
// --------------------------------------- //
public String getAutor() {
return (String) entity.getProperty(AUTOR);
}
public String getFecha() {
return formatter.format((Date) entity.getProperty(FECHA));
}
public String getTutorial() {
return (String) entity.getProperty(TUTORIAL);
}
public Entity getEntity () {
return entity;
}
}
http://code.google.com/intl/es/appengine/docs/java/javadoc/com/google/appengine/api/datastore/Query.html
http://code.google.com/intl/es/appengine/docs/java/javadoc/com/google/appengine/api/datastore/FetchOptions.html
package com.autentia.adictosaltrabajo.gae.persistence;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import com.google.appengine.api.datastore.DatastoreService;
import com.google.appengine.api.datastore.Entity;
import com.google.appengine.api.datastore.FetchOptions;
import com.google.appengine.api.datastore.Query;
import com.google.appengine.api.datastore.FetchOptions.Builder;
import com.google.appengine.api.datastore.Query.SortDirection;
public class TutorialUtils {
private static final int FETCH_MAX_RESULTS = 10;
/**
* Almacenamiento de un nuevo tutorial
* @param autor nombre del autor
* @param tituloTutorial titulo del tutorial
*/
public static void insert(final String autor, final String tituloTutorial) {
// recuperacion del datastore
final DatastoreService datastoreService = DSF.getDatastoreService();
// creamos un nuevo tutorial y los insertamos en el datastore
final Tutorial tutorial = new Tutorial(autor, tituloTutorial);
datastoreService.put(tutorial.getEntity());
}
/**
* Recuperación de los últimos 10 tutoriales (FETCH_MAX_RESULTS)
* @return una lista con los últimos 10 tutoriales
*/
public static List getEntries() {
// recuperación del datastore y configuracion de la consulta
final DatastoreService datastoreService = DSF.getDatastoreService();
final Query query = configureQuery();
final FetchOptions fetchOptions = configureFetchOptions();
// declaracion de un listado donde volcar los resultados
final List tutoriales = new ArrayList();
// lanzamiento de la consulta, la cual recupera entidades
for (Entity entity: datastoreService.prepare(query).asList(fetchOptions)) {
// conversion de las entidades a tutoriales
tutoriales.add(convertEntityToTutorial (entity));
}
return tutoriales;
}
/**
* Conversion de entidad a tutorial
* @param entity entidad a ser convertida en tutorial
* @return tutorial procedente de una entidad
*/
private static Tutorial convertEntityToTutorial (final Entity entity) {
final String autor = (String) entity.getProperty(Tutorial.AUTOR);
final String tutorial = (String) entity.getProperty(Tutorial.TUTORIAL);
final Date fecha = (Date) entity.getProperty(Tutorial.FECHA);
return new Tutorial(autor, tutorial, fecha);
}
/**
* Configuración de la consulta a lanzar contra el datastore
* @return una consulta configurada
*/
private static Query configureQuery () {
final Query query = new Query(Tutorial.TUTORIAL_ENTITY);
query.addFilter(Tutorial.FECHA, Query.FilterOperator.NOT_EQUAL, null);
query.addSort(Tutorial.FECHA, SortDirection.DESCENDING);
return query;
}
/**
* Configuración de las opciones de recuperacion de datos
* @return unas opciones de recuperacion de datos configuradas
*/
private static FetchOptions configureFetchOptions () {
return Builder.withLimit(FETCH_MAX_RESULTS);
}
}
Por otro lado tenemos la capa encargada de gestionar el interfaz del ejemplo, la cual no vamos a mostrar en el tutorial ya que carece de interés por ser totalmente independiente al funcionamiento del datastore.
7 Conclusiones
Una necesidad constante en el desarrollo de aplicaciones web es la de disponer de un soporte sobre el cual poder almacenar y recuperar datos. Es por ello que si vamos a dejar nuestras aplicaciones en la nube de Google necesitaremos conocer cómo poder realizar estas tareas sobre sus soportes de almacenamiento.
Como hemos podido ver en este tutorial el soporte de almacenamiento de Google para Google App Engine se conoce como datastore, el cual se apoya a su vez en BigTable, tecnología que no consiste en ser una base de datos relacional aunque es totalmente consecuente. Esto responde a las necesidades de escalabilidad que requieren las aplicaciones de Google, ya que el modelo relacional posee un punto que no es posible escalar: las propias relaciones.
También hemos conocido algunos de los aspectos propios del datastore, como son las entidades, sus propiedades y las transacciones, las cuales se delimitan creando grupos de entidades.
Hemos visto que para la recuperación y almacenaje de información utilizando el soporte para Java tenemos dispone de 3 alternativas: el API de nivel inferior, JDO y JPA. Hemos situado cada una de estas tecnologías y hemos dejado un ejemplo que utiliza la primera de ellas.
El uso del API de nivel inferior es relativamente simple. Nos otorga flexibilidad, nos da todo el control y es muy potente a la hora de lanzar consultas, aparte de que como habeis podido ver no es dificil de utilizar, ya que podemos pensar que las entidades son mapas o tablas hash que se guardan en base de datos.
8 Referencias
¿Qué son el Cloud Computing y Google App Engine?
Google I/O 2008 – App Engine Datastore Under the Covers
Google I/O 2009 – Java Persistence & App Engine Datastore
El API Java de almacén de datos
El API de nivel inferior
Instalación del SDK de Java

