
Usar un
DataSource XML para crear informes con iReport
Este tutorial
es el siguiente de la «saga» de tutoriales relacionados con iReport
que hay actualmente en www.adictosaltrabajo.com.
- Introducción
a iReport - Exportar
PDF multilenguaje con iReport - Subinformes
con iReport - Gráficos
con iReport - Informes
con código HTML
En este nuevo tutorial no vamos a crear nuestros informes usando
la típica conexión a base de datos JDBC, sino que vamos a usar
un fichero XML como fuente de datos (datasource) para rellenar nuestro informe.
Lo primero de todo es crear nuestro fichero XML que nos servirá
de ejemplo para este tutorial.
Introduccion a EJB 3.0 Juan Alonso Anotaciones en EJB 3.0 Juan Alonso Interceptando un EJB en JBOSS Francisco Javier Guia de referencia de JSF Ivan Zaera Introduccion a Ajax4jsf Juan Alonso Jsf y comparativa con Struts Alejandro Perez
Aquí les dejo el fichero ds-report.xml.
Una vez creado nuestro fichero xml arrancamos iReport, en este caso el tutorial
lo he hecho usando iReport 2.0.2, y vamos a crear una nueva conexión/fuente
de datos.
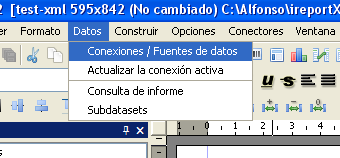
Cuando hacemos clic nos aparece una ventana y le damos a «nueva
conexión…». Seleccionamos la opción «Fuente datos
fichero XML» y hacemos clic en «Próximo».
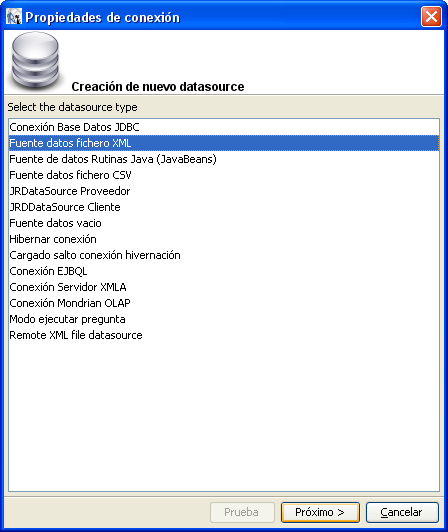
En esta nueva pantalla es donde vamos a tener que configurar nuestro
nuevo datasource o fuente de datos a partir de un fichero XML.
Escogemos un nombre para nuestro datasource, seleccionamos nuestro
fichero xml que anteriormente hemos creado («ds-xml.xml«)
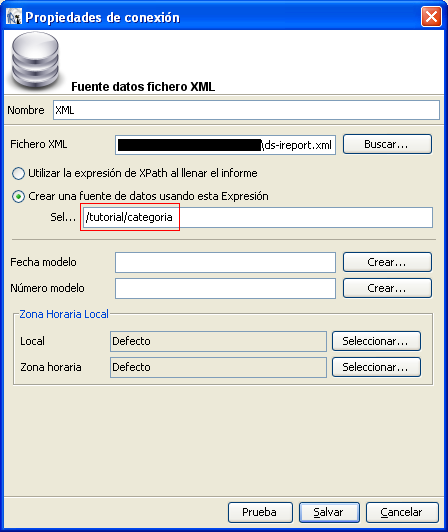
y elegimos la opción de crear una fuente de datos usando esta expresión
y escribimos «/tutorial/categoria/doc«.
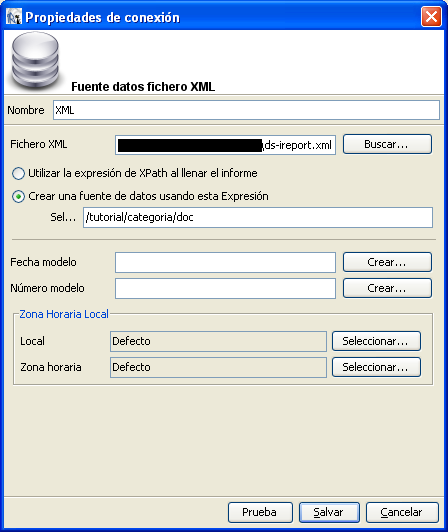
¿Qué siginfica esto? Esto significa que vamos a
crear un nuevo datasource tomando como origen el nivel del nodo representado
por la expresión «/tutorial/categoria/doc».
La implementación de datasource usando XML permite acceder a ficheros
XML usando expresiones XPath. El datasource se contruye a partir del nodo especificado
por «/tutorial/categoria/doc» (expresión XPath).
Cada campo de nuestro informe puede usar una expresión XPath para acceder
a valores, nodos hijos, padre, etc… Esta expresión se debe especificar
en la descripción del elemento campo. Dicha expresión se evalúa
a partir del nodo elegido como origen, en nuestro ejemplo será «/tutorial/categoria/doc».
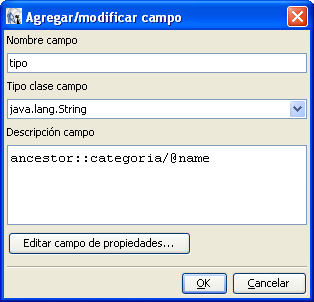
Por ejemplo, si quisieramos acceder al nombre de la categoría usaríamos
la expresión XPath «ancestor::categoria/@name«.
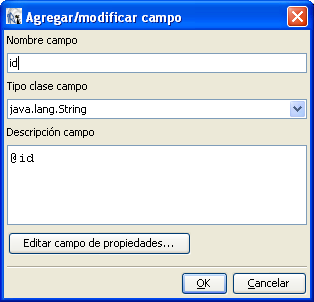
Si quisieramos acceder al id de un nodo doc, usaríamos la expresión
«@id«.
Para saber más sobre XPath, visite este tutorial de adictosaltrabajo.com
Introducción
a XPath.
Una vez creado el datasource correctamente vamos a diseñar nuestro informe.
Aquí les dejo el informe
que he usado para hacer este tutorial.
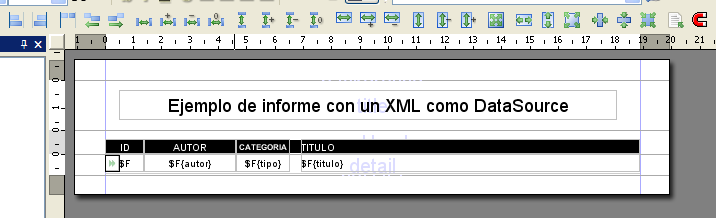
Como se dijo anteriormente, pasa poder acceder a los datos de
nuestro datasource usaremos expresiones XPath que tendremos que colocar en la
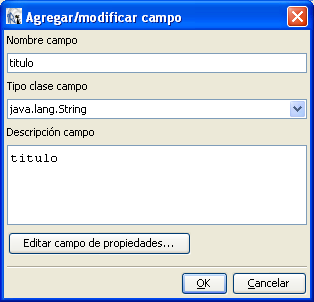
descripción de cada campo que queramos sacar en nuestro informe.Estos
son los campos y las expresiones usada para la creación de este informe.
Como se puede ver todos los tipos de campo son de tipo String y en
la descripción del campo está la expresión XPath que junto
con la expresión origen «/tutorial/categoria/doc»
formará la expresión completa XPath para poder acceder al nodo/valor
correcto.
 |
 |
 |
 |
Ahora sólo nos queda ejecutar el informe y ver el resultado final.
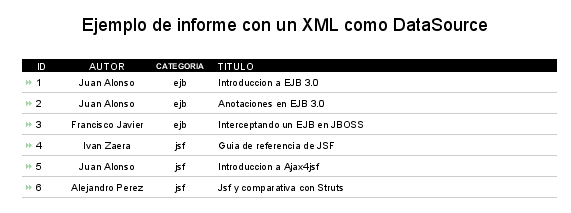
Pero también podemos hacer muchas más cosas, como
por ejemplo crear subinformes. Vamos a hacer un ejemplo de un informe con un
subinforme para que nos devuelva todos los tutoriales de cada una de las categorías.
El primer paso es crearnos el informe principal (o informe padre)
como lo hemos hecho anteriormente en este mismo tutorial, con la única
salvedad que cuando configuremos nuestro datasource vamos a elegir
la opción de «Crear una fuente de datos usando esta expresión»
y escribimos «/tutorial/categoria«.
Este es el aspecto del nuevo informe principal (tutorial-xml-subreport.jrxml)
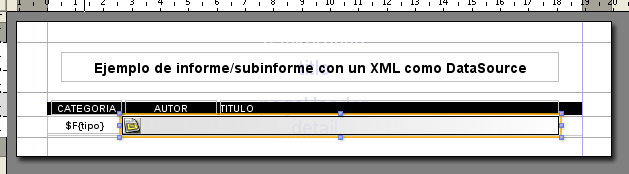
La estructura de este informe es muy sencilla. Hemos creado un
datasource a partir del mismo fichero xml pero esta vez hemos tomado
como «origen» el nodo representado por la expresión «/tutorial/categoria«.
Esto hará que el informe padre saque todas las categorías del
fichero xml, es decir, ejb y jsf. Con el subinforme
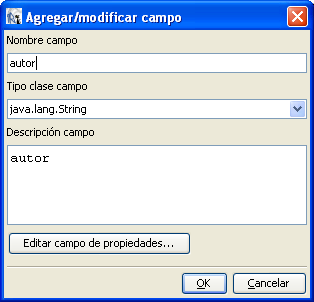
vamos a sacar todos los documentos (el campo «autor» y «titulo»)
de cada categoría.
Para ello tenemos que ir a las propiedades del subinforme, a la
pestaña «Subinforme» y en el apartado de «Conexión/Fuente
de datos» tenemos que seleccionar la opción de «Usar expresión
de fuente de datos» y poner ((net.sf.jasperreports.engine.data.JRXmlDataSource)$P{REPORT_DATA_SOURCE}).subDataSource(«/categoria/doc»)
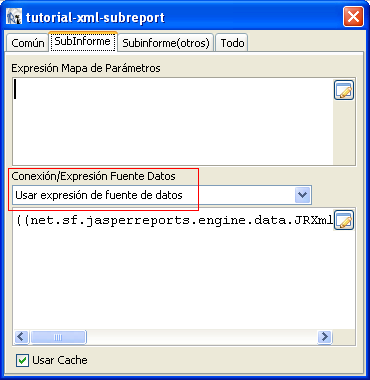
Esto creará un subdatasource para nuestro subinforme
a partir del nodo origen «/doc«. El aspecto de nuestro
subinforme (tutorial-xml-subreport_subreport0.jrxml)
es este:
![]()
Con los siguientes campos:
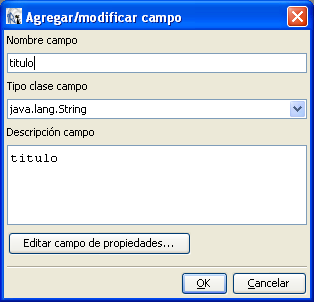 |
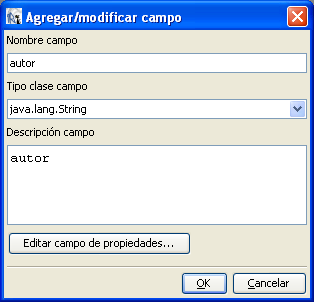 |
Una vez creado nuestro informe, subinforme, integrado en el informe
principal y configurado correctamente su «Conexión/Fuente de datos»
sólo nos queda probarlo todo…

En nuestro negocio podemos encontrarnos casos en que sea necesario
o mejor el uso de otras conexiones, por ello iReport soporta muchos tipos de
conexiones o fuente de datos además de JDBC, como pueden ser ficheros
XML, ficheros CSV, JavaBeans, EJBQL, etc…
En próximos tutoriales veremos algunas de ellas….


Buenas tardes una pregunta, y espero me puedan ayudar, estoy tratando de usar php y java con el puente de phpbridge para generar mis reports en ireport, usando sus manuales me sirvieron para poder hacerlo mediante conexion a la db, pero cuando intento leer un archivo xml con la informacion y eso mandarlo al ireport no puedo:
esto es lo q intento hacer:
$JRXml = new JavaClass(\\\»net.sf.jasperreports.engine.data.JRXmlDataSource\\\»);
$xmlconn = $JRXml->JRXmlDataSource(\\\»E:\\\\\\\\Reporttemp\\\\\\\\ventasxUsuario.xml\\\», \\\»/tutorial\\\»); //aca esta el error\\\»
$print = $jfm->fillReport($report, $params, $xmlconn);
pero me da este error:
Fatal error: Uncaught [[o:Exception]:\\\»java.lang.Exception: Invoke failed: [[c:JRXmlDataSource]]->JRXmlDataSource([o:PhpParserString], [o:PhpParserString]). Cause: php.java.bridge.NoSuchProcedureException: static JRXmlDataSource([o:PhpParserString]
si fueran tan amables de apoyarme, les agradecere mucho.
Compañero
Buena tarde,
Disculpa la molestia, fíjate que tengo un problemita… me han solicitado hacer unos reportes tipo contratos (ventas). Los datos como nombres, apellidos, dirección, cantidades, productos a adquirir, sean recogidos vía web. Y tienen que ser dinámicos y flexibles tanto como sea posible… dependiendo cuantos productos o que tipo, así será las partes que el reporte deba incluir (secciones de licencias, precios, clausulas, etc.), yo he estado trabajando ya por varios meses iReports pero nunca he podido hacer esto. (colocar dos o tres páginas con formatos diferentes), con sub-reportes si salen dos paginas diferentes pero no 3, aparte de eso elementos como las clausulas o texto obligatorio no quisiera quemarlos en el reporte sino que leerlos desde archivos de texto (xml, txt, o algo similar).
He buscado tutoriales o ayuda por Internet para hacer esto, pero no he tenido éxito. Será que tu amable persona tendrá una idea o solución a mi problema para implementarla?.
De antemano muchas gracias por el tiempo prestado y tu pronta respuesta.
Hola canzion23 deberias de ir «jugando» con el atributo «print when expression», aunque no comprendo muy bien lo que necesitas hacer.
Buenos dias, excelente tutorial. Sería posible algún ejemplo mostrando la transformación de un parametro xml (imagen que viene en texto plano) para mostrarlo en el informe como imagen ?
Gracias
Buenas tardes!!
Quiero ver si me pueden ayudar a realizar una conexión a mongoDB desde iReport 5.0, he tratado pero no lo he conseguido, espero puedan ayudarme.