
JBOSS EN CLUSTER. EJEMPLO DE ALTA DISPONIBILIDAD
Entorno
Los ejemplos de este tutorial están hechos con el siguiente entorno de desarrollo:
- JBoss Eclipse IDE Milestone 5.
- JDK 1.4
- JBoss 4.0.5 GA
Introducción
Se pretende en este tutorial, y en posteriores tutoriales que tengo en mente realizar,
enseñar a todo aquel que esté interesado en este poderoso servidor de aplicaciones
las distintas posibilidades que ofrece JBoss para manejar temas de clustering, alta disponibilidad etc… en aplicaciones J2EE.
Además lo haré en base a ejemplos, que creo que es la forma más didáctica. Os propongo por lo tanto, el siguiente ejemplo.
Imaginaros que estáis trabajando para un concesionario de coches. El departamento de contabilidad, diariamente, ha de comunicar a la central el número de coches vendidos al día, al cierre del concesionario. El departamento de contabilidad os ha pedido estudiar la posibilidad de informatizar este proceso, y os comunica la importancia de que este proceso no falle. Sabemos además, que el departamento de informática de la empresa dispone de un webservice a través del cual se puede notificar esta información (no haremos esta parte, ya que no es el objetivo). De esta pequeña información podemos extraer las siguientes conclusiones:
- Necesitamos un proceso que se ejecute recursivamente a modo de cron. (Podríamos usar una tarea planificada de JBoss, es decir usar el servicio Scheduler).
- Sabemos, que nuestro proceso debe recoger la información de la base de datos (coches vendidos en el día) y enviar dicha información diariamente al cierre del concesionario. Si suponemos que nuestro concesionario cierra a las 20:00 horas y abre a las 10:00 horas, podemos suponer, que nuestra tarea recursiva debe conseguir enviar la información cada día durante el periodo de tiempo que va desde las 20:00 horas del día actual hasta las 10:00 horas del día siguiente. Una vez que lo consigue, rellena la información enviada en alguna tabla de base de datos indicando que ese día ya ha sido notificado. Toda esta parte la podemos resolver mediante un algoritmo sencillo.
- También nos han indicado la importancia que tiene que este proceso no falle. Evidentemente el departamento de contabilidad no sabe que lo que está pidiendo es que el proceso se realice en «alta disponibilidad». Es decir, necesitamos que el proceso se ejecute en dos máquinas distintas.
- Del apartado 3. Intuimos un problema. ¿ Podemos notificar dos veces a la central la misma información ? La respuesta ya os la digo yo…NO. Es necesario, que de alguna manera los procesos se sincronicen. Evidentemente, podríamos usar la base de datos como punto de sincronización y mediante algún algoritmo más o menos complejo lo conseguiríamos, pero… ¿ no existe alguna manera más sencilla ?. Ahí es donde entra la alta disponibilidad de JBoss . Realmente lo que nosotros necesitamos es que nuestra tarea planificada se despliegue en ambos servidores de aplicaciones, pero sólo uno de ellos debe estar activo, es decir en modo activo-pasivo, o mejor dicho «maestro-esclavo», lo que JBoss denomina HA-Singleton.
Ya tenemos la idea más o menos clara. Vamos a empezar a desarrollar nuestro ejemplo.
La Tarea Planificada
No me voy a detener a explicar el servicio Scheduler de JBoss.
Os dejo el enlace al tutorial:
http://www.adictosaltrabajo.com/tutoriales/tutoriales.php?pagina=jbossScheduler
Empecemos abriendo nuestro eclipse. Nos creamos un proyecto nuevo para nuestro ejemplo. (No olvidéis añadir las librerías de JBoss para poder compilar la tarea planificable)
Empezaremos creando un interfaz que llamaremos INotificadorCentral:
package com.autentia.tutoriales.jboss;
public interface INotificadorCentral {
/**
* Este método debe acceder a Base de datos para comprobar
* si el día ya ha sido notificado a la central
* */
public boolean diaNotificado();
/**
* Este método debe comprobar si estoy o no en periodo de
* notificación, es decir desde el cierre del concesionario del día
* de notificación hasta la apertura del concesionario al día siguiente
*/
public boolean isPeriodoNotificacion();
/**
* Este metodo accede a base de datos, recopila la información y
* envía mediante un webservice la información a la central y
* almacena en base de datos la información notificada si todo ha
* ido bien.
*/
public void notificayGuarda();
}
Nos crearemos ahora la clase NotificadorCentral:
package com.autentia.tutoriales.jboss;
import java.util.Date;
import org.jboss.varia.scheduler.Schedulable;
public class NotificadorCentral implements INotificadorCentral, Schedulable {
public boolean diaNotificado() {
System.out.println("COMPRUEBO SI EL DÍA YA HA SIDO NOTIFICADO");
return false;
}
public boolean isPeriodoNotificacion() {
System.out.println("COMPRUEBO SI ESTOY EN PERIODO DE NOTIFICACION");
return true;
}
public void notificayGuarda() {
System.out.println("RECOJO INFORMACIÓN DE BASE DE DATOS.");
System.out.println("NOTIFICO A LA CENTRAL.");
System.out.println("GUARDO EN BASE DE DATOS.");
}
public void perform(Date arg0, long arg1) {
if(diaNotificado())
return;
if(!isPeriodoNotificacion())
return;
notificayGuarda();
}
}
Crearemos a continuación el descriptor del servicio: (jboss-service.xml)
true com.autentia.tutoriales.jboss.NotificadorCentral NOW 15000 -1
Nos creamos el fichero «notificador.sar»:
- com/…
- META-INF/jboss-service.xml
Ahora ya tenemos nuestro servicio preparado y empaquetado.
Vamos a probar a ver si funciona correctamente en uno de los servidores. Lo voy a desplegar en default/deploy:
Y arrancamos el servidor en modo default (run.bat -c default) y mostramos la consola:

Una vez probado, empezaremos a probar las caracteristicas de alta disponibilidad.
Para ello, deberemos trabajar en modo «all». Arrancaremos nuestro servidor
de la siguiente manera: (run.bat -c all)
Configurando el Cluster
Lo primero que debemos hacer es configurar el cluster de nuestros servidores de aplicaciones.
En mi caso, yo tengo dos máquinas windows trabajando en una red local, cada una de ellas con el servidor de aplicaciones JBoss 4.0.5 instalado.
Las IPs de las máquinas son: 192.168.1.2 y 192.168.1.13
JBoss, para la comunicación entre las máquinas del cluster usa JGroups y se puede configurar de dos modos esta comunicación, por UDP o por TCP. Nosotros para nuestro ejemplo usaremos TCP.
Editaremos en ambas máquinas el siguiente fichero:
\server\all\deploy\cluster-service.xml
Buscaremos la etiqueta:
Y comentaremos la parte de configuración por UDP y descomentaremos la parte de configuración por TCP. La configuración por TCP quedará en la máquina 192.168.1.2 de la siguiente manera:
En la máquina 192.168.1.13 quedará:
Con esto ya tendríamos configurado el cluster. Recomiendo también configurar el cluster de Tomcat para evitarnos algunos errores en el arranque. Para ello, editaremos en ambas máquinas el siguiente fichero:
\server\all\deploy\tc5-cluster.sar\META-INF\jboss-service.xml
Buscaremos la etiqueta:
Y comentaremos la parte de configuración por UDP y descomentaremos la parte de configuración por TCP. La configuración por TCP quedará en la máquina 192.168.1.2 de la siguiente manera:
En la máquina 192.168.1.13 quedará:
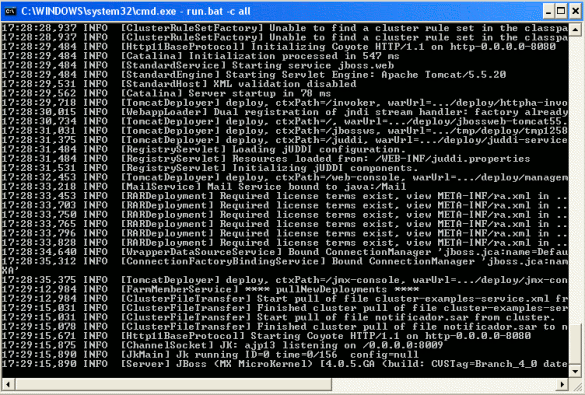
Ahora, lanzaremos ambos servidores para observar el arranque:
(si tenéis algún firewall, podéis tener problemas)
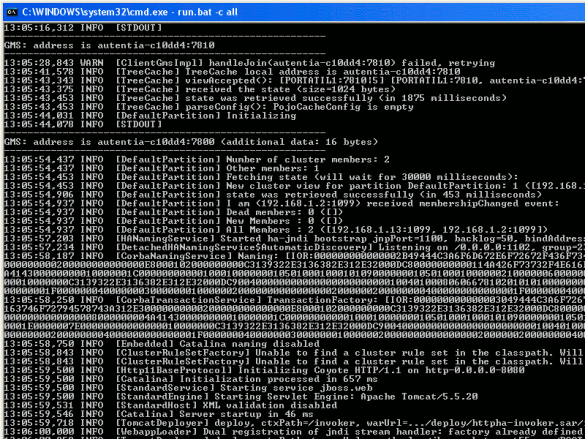
Podéis observar como ambos servidores están arrancados en cluster.
DESPLEGANDO EL SERVICIO EN DEPLOY:
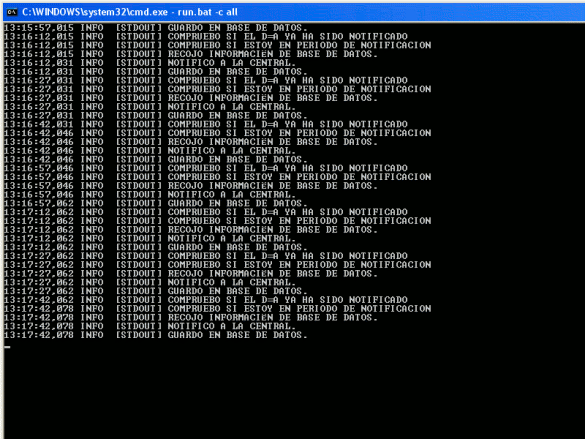
Lo primero que haremos será desplegar nuestro servicio de manera normal, es decir, en el directorio <ruta_instalacion_jboss> \server\all\deploy
de ambas máquinas. En este caso comprobaremos que funcionan ambas de manera independiente:
Mostramos la consola del primer servidor (192.168.1.2)
En la segunda máquina:
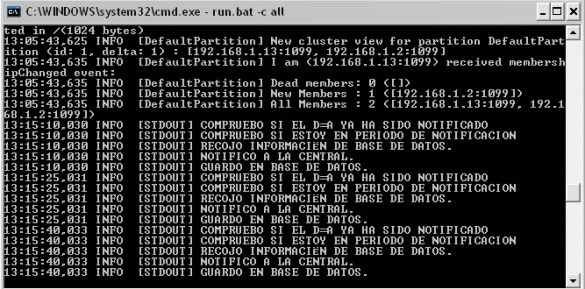
Comprobamos como los servicios trabajan de forma independiente.
DESPLEGANDO EL SERVICIO EN CLUSTER.
Bueno, ahora, aprovechemos la posibilidad que ofrece JBoss de desplegar un módulo en todos los nodos del cluster de una sola vez. Eliminaremos el fichero notificaciones.sar de los directorios «deploy» de ambas máquinas y lo copiaremos en el directorio: <ruta_instalacion_jboss> \server\all\farm de una de las máquinas y observemos lo que ocurre:
En la máquina donde hemos copiado el fichero:
- 1. Se intenta enviar a todos los nodos del cluster el fichero notificador.sar
«Start push of file notificador.sar to cluster» - 2. Se inicia el servicio.
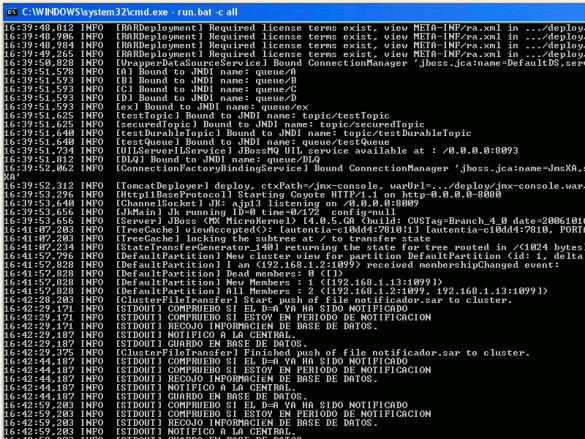
En la otra máquina del cluster:
- 1. Se recibe el fichero y se despliega en local:
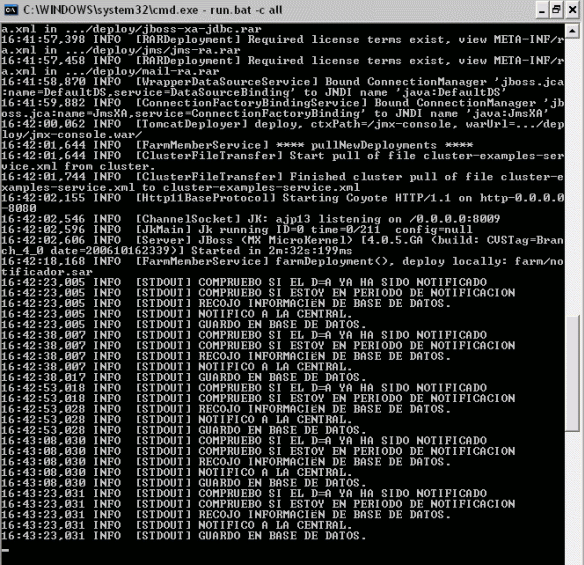
Hemos conseguido que únicamente tengamos que desplegar el fichero en una de las máquinas del cluster, pero aún no hemos consegudo nuestro objetivo de trabajar en modo HA-Singleton.
DESPLEGANDO EL SERVICIO EN MODO HA-SINGLETON.
Volvamos al descriptor de despliegue de nuestro Notificador (jboss-service.xml) y añadamos la siguiente dependencia:
jboss.ha:service=HASingletonDeployer,type=Barrier true com.autentia.tutoriales.jboss.NotificadorCentral NOW 15000 -1
Regeneremos el fichero notificador.sar y volvamos a desplegar el fichero en: <ruta_instalacion_jboss> \server\all\farm de alguna de las máquinas y observemos que ocurre.
En la máquina donde hemos copiado el fichero, no ha ocurrido ningún cambio con respecto a lo anterior:
- 1. Copia al cluster el fichero
- 2. Arranca de nuevo el servicio
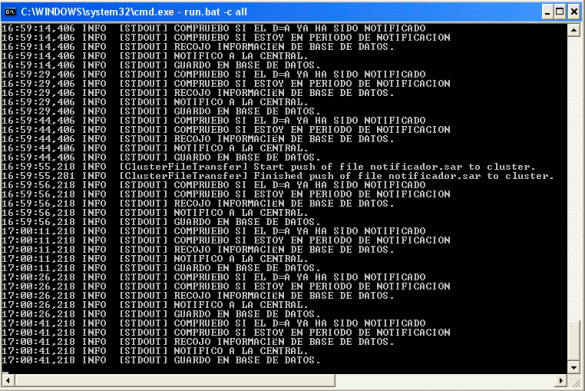
¿ Y en la otra máquina ?
Observemos la consola:
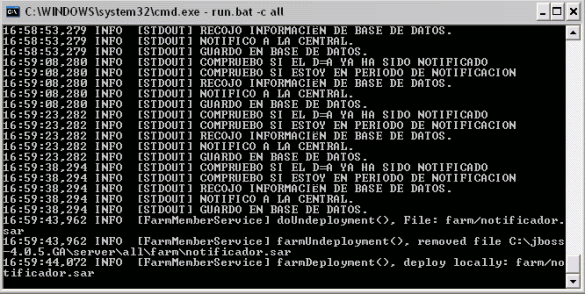
El servicio se ha desplegado pero…no ha arrancado. ¿Por qué?.
Al poner la dependencia anterior, hemos configurado el servicio para que sólo arranque en uno de los nodos (el maestro). Vamos a parar el nodo maestro (shutdown.bat -S), a ver que ocurre:
En la máquina maestra:
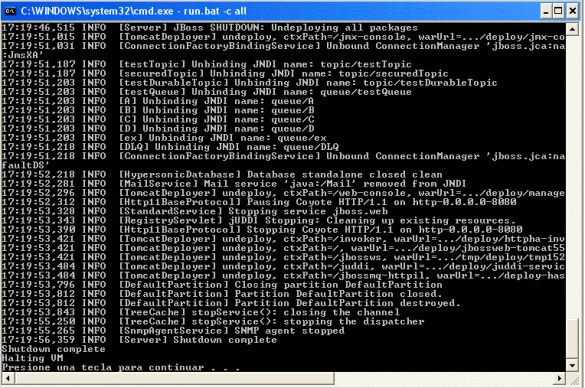
En la segunda máquina:
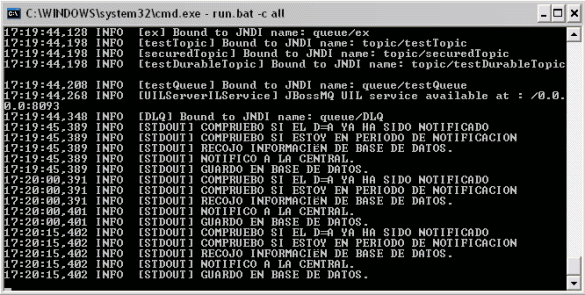
Vemos como se arranca el servicio, es decir, esta máquina pasa a ser la máquina maestra del cluster.
Volvamos a arrancar la máquina que hemos parado:
Vemos como el servicio no se arranca. ¿ Y en la otra máquina ?
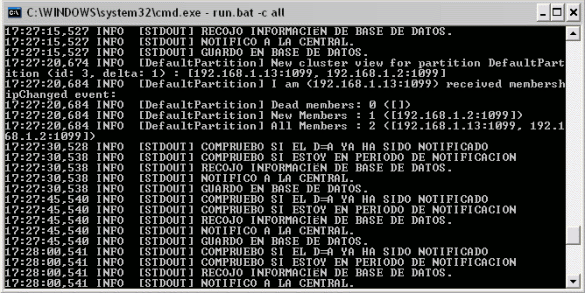
Vemos como se detecta el arranque del otro servidor, pero continúa la ejecución del servicio.
Bueno, pues podéis seguir haciendo pruebas de parar una máquina, arrancar la otra, etc…, pero creo que hemos conseguido lo que buscábamos.
Espero que os haya servido el tutorial, si queréis que os ayudemos ya sabéis:


Hola Francisco muy genial tu tuto, me podrías aclarar una para de dudas, si hago este despliegue en cluster, se podría hacer la replicación de sesión en los usuarios?,
Si despliego un proyecto .ear, en caso de que se desee hacer una actualización del mismo y no se quiera reiniciar el servidor o el clúster en si , sino hacer un republishing sin perder laas sesiones activas, los cambios los haría solo de manera automática?
Saludos
Buenos días Francisco
Lo primero de todo gran tutorial. Tengo un problema a ver si me puedes ayudar.
Tengo dos servidores en cada de uno de ellos tengo corriendo dos wildfly 11 uno configurado en modo maestro y otro como esclavo. El esclavo se registra en el maestro, desplieguo aplicaciones en el maestro y estas se replican al esclavo sin problemas.
Por encima de estos dos servidores, en el servidor maestro tengo un apache con mod_cluster configurado.
El problema que tengo es que no consigo la replicación de session, mod_cluster es capaz de balancear la carga entre los dos servidores (maestro y esclavo) pero si paro un servidor la sessión se pierde.
Por favor, me podrías ayudar.
Muchas gracias
Un saludo
Si estás hablando de una aplicación web, quizá necesites habilitarla como distribuida en el web.xml (distributable) de la misma.