
JRBeanCollectionDataSource: trabajando con arrays multidimensionales en Jasper Report.
0. Índice de contenidos.
- 1. Introducción.
- 2. Entorno.
- 3. Plantilla jrxml.
- 4. Generación del informe desde java.
- 5. Conclusiones.
1. Introducción
Despúes de exponer como trabajar
con colecciones de tipos básicos en iReport sin una fuente de datos definida, en este tutorial vamos a dar una vuelta de tuerca añadiendo
la complejidad de tener como parámetro en el informe un array multidimensional de tipos básicos, una nube de puntos.
Sin más, y tomando como referencia el tutorial anterior vamos a pintar la información anidada en listas dentro del informe.
2. Entorno.
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 15′ (2.4 GHz Intel Core i7, 8GB DDR3 SDRAM).
- Sistema Operativo: Mac OS X Lion 10.7.4
- iReport 4.7.1
- Jasper Report 4.7.1
3. Creación de la plantilla jrxml.
Con la plantilla vacía y sin asignar una fuente de datos «Empty Datasource»:
Creamos un parámetro, para ello «botón derecho» sobre «Parameters» > «Agregar Parameter»:
Le asignamos un nombre, en nuestro caso «nube_puntos»:
Y accediendo a la ventana de propiedades, le damos una tipología en «Parameter Class» > «java.util.Float[][]»,
un array multidimensional de floats,
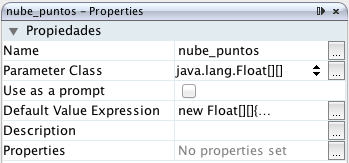
además pulsando sobre «Default Value Expression» podemos asignar algo
como lo siguiente para añadir un juego de pruebas:
Con ello, ya tenemos preparado nuestro parámetro para el entorno de pruebas y ahora vamos a añadir un componente visual de tipo
lista para iterar por su contenido y mostrar la nube de puntos.

Pulsando sobre icono anterior y arrantrándolo al area de la plantilla lo tendremos disponible para su edición:
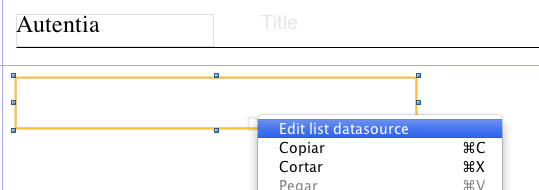
Una vez incluido en la sección correspondiente de la plantilla «botón derecho» > «Edit datasource» mostrará una ventana como la que sigue:
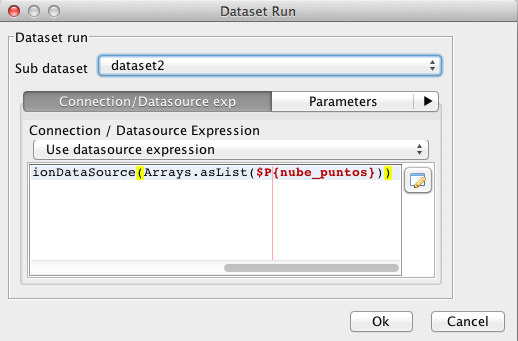
En este punto son importantes dos cuestiones:
- «Sub dataset» definirá los parámetros de entrada, campos, variables,… que vivirán en el ámbito de la lista y que, no tienen por qué coincidir
con los de la plantilla padre, ahí será donde definiremos un campo «ad hoc», - Connection / Datasource Expression: indica la fuente de datos para la lista que puede ser la misma fiente de datos que el informe padre u otra,
en nuestro caso definimos una expresión usando la clasenet.sf.jasperreports.engine.data.JRBeanCollectionDataSourcey pasando
como argumento al constructor una referencia al parámetro anteriormente definido.

Lo siguiente será definir un campo que haga referencia a cada uno de los items de la colección, si tuviéramos un objeto tipado,
añadiríamos los campos a mostrar de la clase o el bean en cuestión, como trabajamos con tipos básicos añadiremos un campo con la
palabra reservada _THIS, que hará referencia a cada una de las cadenas dentro de la iteración interna de la lista.
Sobre el dataset2, el que usa la lista, pulsamos «botón derecho» en «Fields» > «Agregar Field»
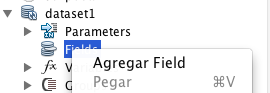
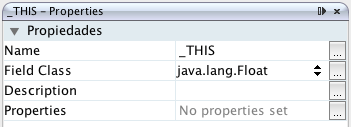
El nombre para nuestro campo es la palabra reservada _THIS y el tipo es un array de floats:
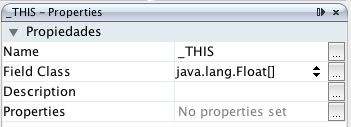
Con ello estamos accediendo a la primera dimensión, si queremos acceder a los puntos debemos incluir un nuevo componente de lista anidado

que estará asociada a nuevo dataset y tendrá la siguiente fuente de datos:
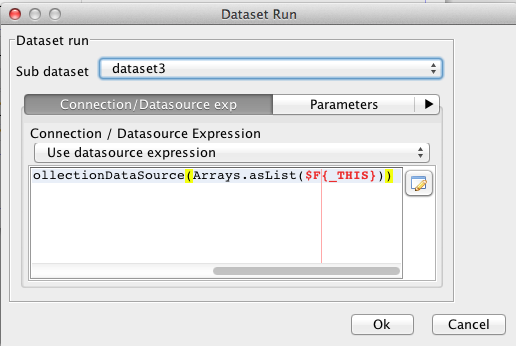
Este dataset tendrá un campo también con el nombre _THIS, pero del tipo java.lang.Float.
Con ello ya podemos incluir un campo $F{_THIS} en la lista anidada para hacer referencia a cada punto a imprimir:

El informe tendría una salida como la siguiente:

4. Generación del informe desde java.
Si el informe anterior lo tuviéramos que generar desde código bastaría hacer uso del servicio que vimos en el tutorial anterior de la siguiente forma:
private static Float[][] puntos = new Float[][]{
new Float[]{1.2f, 1.3f},
new Float[]{1.4f, 1.5f},
new Float[]{1.6f, 1.7f},
new Float[]{1.8f, 1.9f, 1.10f, 1.11f},
new Float[]{2.8f, 2.9f, 2.10f, 2.11f}
};
public static void main(String[] args) throws JRException {
final Map<String,Object> parameters = new HashMap<String,Object>();
parameters.put("nube_puntos", puntos);
final ReportExporter reportExporter = new ReportExporter();
reportExporter.toPDF("fichaEmpresa.jrxml", parameters);
}
El resultado será el mismo que el obtenido desde el entorno de iReport.
5. Conclusiones.
Que que comentábamos, lo ideal es trabajar con objetos tipados ;).
Un saludo.
Jose


Una pregunta como puedo trabajar(recibir mostrarlos en una tabla) cuando envio dos diferentes tipos de listas de objetos en los parametros
Dice Dataset2 y en la imagen esta Dataset1. Se presta a confusión. Necesito este ejemplo pero mejor explicado, por favor
No he podido ejecutar el ejemplo, hubo un error: Field not found: _THIS. ¿Qué debo hacer?
tambien tengo el mismo problema del field not founf _THIS