
¿QUÉ SON EL CLOUD COMPUTING Y GOOGLE APP ENGINE?
1 Introducción
Sin duda alguna, y lo que es peor, sin
avisar, un nuevo término ha llegado para pasar a formar parte de
nuestro ya de por sí extenso vocabulario tecnológico. Un concepto
nuevo, o quizá no tanto, que se ha colado en multitud de sitios y
que se ha propagado por la red, por los portales de tecnología, por
la prensa escrita e, incluso, por la lista de tutoriales de
adictosaltrabajo. Me
refiero al cloud computing.
Pero, ¿qué es el cloud computing?, ¿a
qué nos referimos con eso de “la nube”?, ¿por qué tantas voces
predicen que es “el futuro”?, ¿es simplemente una técnica
comercial o realmente hay algo “detrás”?. El presente tutorial
trata de responder a todas estas preguntas centrándose en una nube
muy de moda, el Google
App Engine

Pero antes de explicar qué es el
Google App Engine y para qué sirve es necesario dar un repaso
teórico al concepto de cloud computing, la computación en la nube o
“la nube” a secas y, de este modo, saber qué es, de dónde viene
y dónde va.
2 ¿Qué es el cloud computing?
Hay tantas definiciones de la nube como autores han tratado de
definirla, y es que parte del problema de comprender qué es el cloud
computing es, precisamente, que no posee una definición concreta. En
este tutorial no nos inventaremos una enésima definición del
concepto y utilizaremos la de la wikipedia
como referencia:
“La computación en nube, del inglés cloud computing, es un
paradigma que permite ofrecer servicios de computación a través de
Internet. La nube es una metáfora de Internet.”
Esta definición, como podréis ver, es tan amplia que
prácticamente cabe cualquier cosa. Si yo en el trabajo conecto a
través de Internet con el ordenador de mi casa para ver cómo van
mis descargas, ¿estaría siguiendo el paradigma de la computación
en la nube?, me temo que no 🙂
¿Pero porqué no, si estoy accediendo a un servicio a través de
internet? La nube se apoya en tecnologías que llevan varias décadas
funcionando que seguramente no tengas en tu casa y que no son para
nada nuevas. De hecho el cloud computing es, en realidad, una
remodelación del concepto de grid computing.
2.1 Grid computing
Citando de nuevo a la wikipedia:
“La computación grid es una tecnología innovadora que
permite utilizar de forma coordinada todo tipo de recursos (entre
ellos cómputo, almacenamiento y aplicaciones específicas) que no
están sujetos a un control centralizado. En este sentido es una
nueva forma de computación distribuida, en la cual los recursos
pueden ser heterogéneos (diferentes arquitecturas,
supercomputadores, clusters…) y se encuentran conectados mediante
redes de área extensa (por ejemplo Internet)”
Nosotros, ingenuos usuarios, hacemos peticiones pensando que lo
que habrá “al otro lado” será un ordenador que se dedicará a
atendernos a nosotros, cuando en realidad nuestra petición es
dividida en varias tareas que serán atendidas por varias máquinas
dentro de una red donde puede haber cientos o miles de ordenadores.
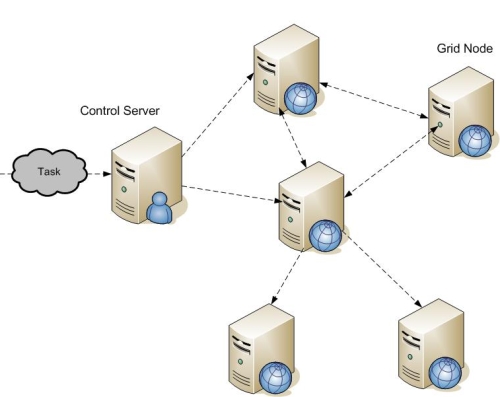
Las diferencias entre este enfoque y el clásico modelo
cliente-servidor son varias. En un modelo cliente-servidor clásico
hay uno o varios clientes que conectan con un único servidor de gran
capacidad. Gracias a la computación en grid lo que ponemos en el
lado del servidor no es un único ordenador con mucha capacidad sino
una red de ordenadores con varios cientos o miles de máquinas de
menor capacidad. Esta infraestructura tiene una serie de ventajas
entre las cuales destacamos:
-
Posibilita el funcionamiento de aplicaciones a gran
escala. De hecho para aumentar la capacidad tan sólo deberíamos
añadir nuevos ordenadores a la red. -
Facilita el acceso a recursos distribuidos desde
nuestros ordenadores. -
Consiguen una mayor disponibilidad, ya que en caso de
fallar una máquina del grid el resto de ellas siguen funcionando y
dando servicio.
Pero no todas las máquinas de la red se dedican a los mismos
usos. Hay máquinas especializadas en la realización de cálculos,
máquinas que contienen los datos de las bases de datos, máquinas
donde se albergan ficheros, etc.
Pero, ¿qué tiene que ver todo esto con el cloud computing? Muy
sencillo, que todas todas todas las aplicaciones que se
encuentran en “la nube” están funcionando sobre una arquitectura
basada en grid.
Entonces, ¿qué diferencia hay entre cloud computing y grid
computing?. Una vez hemos visto qué es el grid, vamos a ver las
distintas capas de la nube para encontrar nosotros mismos las
semejanzas y las diferencias entre ambos tipos.
2.2 Capas del Cloud Computing
Aunque otros autores suelen utilizar un número de capas menor,
nosotros vamos a utilizar el modelo de cinco capas. Las vamos a
colocar en forma de pirámide para recalcar el hecho de que las capas
inferiores poseen mayor número de elementos que las superiores.
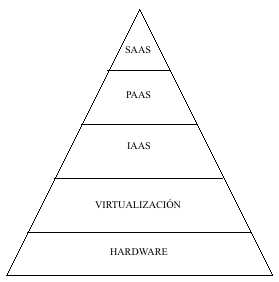
Como ya comenté en la introducción de este tutorial nos vamos
centrar en el Google App Engine así que explicaremos cada una de las
capas utilizando esta nube como ejemplo. Sin embargo tenemos que
tener en mente que hay otros tipos de nubes cuyas capas pueden tener
usos o funcionalidades diferentes.
Dicho esto, comencemos a explicar las capas.
2.2.1 Hardware
A la vista de la pirámide podréis ver que está en la parte
inferior y que es la más grande de todas. Como su nombre indica en
esta capa se encuentran todos los dispositivos físicos que hacen
funcionar a la nube: pasillos y pasillos con miles y miles de
ordenadores unos apilados encima de otros:

En el caso que nos ocupa todo este hardware se encuentra en los
datacenters de Google. Os recomiendo ver este vídeo para que os
hagáis una idea de lo que es uno sólo de los muchos datacenters que
Google tiene alrededor del mundo:
http://www.youtube.com/watch?v=zRwPSFpLX8I
Esta es la parte física del grid. Algunos de los ordenadores
estarán destinados a almacenar datos, otros a procesar información,
otros a almacenar archivos, etc. Todas nuestras búsquedas, nuestros
correos de gmail, nuestros calendarios y últimamente hasta nuestros
documentos se encuentran en esos ordenadores.
Todos ellos son fácilmente reemplazables y si queremos ampliar la
capacidad tan sólo deberemos añadir más ordenadores o construir
otro nuevo datacenter.
2.2.2 Virtualización
Como en todos los ordenadores y en todo tipo de dispositivos en
general nos encontramos con que justo encima de la capa hardware se
encuentra la del sistema operativo.
Otras nubes lo que hacen es instalar un sistema operativo muy
reducido sobre el hardware y sobre ese sistema operativo reducido
instalar máquinas virtuales con VMWare, VirtualBox, etc. Todo esto,
como es natural, conlleva una pérdida de rendimiento.
Google no hace eso. Google utiliza sistemas operativos linux
modificados con un sistema de ficheros propio: GFS (Google
File System).
http://labs.google.com/papers/gfs.html
Con ello no sólo no pierde rendimiento sino que además va más
allá de lo que un sistema de ficheros tradicional permite llegar, y
es que el sistema de ficheros de Google:
-
Es un sistema de ficheros distribuido en el que participan
cientos o miles de ordenadores. -
Se diseñó pensando que los fallos en el hardware no son la
excepción sino la norma. -
Generalmente maneja ficheros con tamaños de varios gigas que
pueden llegar a los terabytes. -
Al escribir datos en disco lo normal no es modificar los que
ya existen sino crear datos nuevos. -
Los ficheros, una vez escritos, sólo se leen y por lo
general de manera secuencial.
Como veis en ningún momento se menciona para nada la palabra
“borrar” :-). Es un sistema de ficheros en el que sólo guardas,
guardas y guardas, y además ficheros de tamaños enormes que se
encuentran distribuidos en varios ordenadores, que luego se leen
prácticamente de un tirón con lo que ahorras al disco el trabajo y
el tiempo de tener que buscar sectores en concreto.
De este modo GFS consigue un objetivo
claro: una capacidad de almacenamiento ilimitada.
2.2.3 IAAS (Infraestructure as a service)
Bueno, de momento tenemos una red enorme de ordenadores
organizados en datacenters que tienen un sistema operativo reducido y
un sistema de ficheros hecho a medida. El siguiente paso es
especializar a los ordenadores que se encuentren en esa red, de tal
modo que algunos de ellos se encarguen de almacenar ficheros, otros
de guardar bases de datos, etc, y de esta manera continuar
construyendo nuestra nube basada en una estructura grid.
Si Google quiere destinar un conjunto de ordenadores al
almacenamiento de ficheros lo tiene fácil, tiene máquinas y un
sistema de ficheros propio muy adaptado a sus necesidades.
Pero, ¿y si quiere dedicar máquinas a almacenar datos como si de
una base de datos se tratara? Si por algo es famoso Google es por sus
búsquedas, así que “algo” tendrá donde poder almacenar
información, ¿verdad?
Al igual que tiene su propio sistema de ficheros, también tiene
su propio sistema de almacenamiento de información. Este sistema NO
ES UNA BASE DE DATOS y se le conoce con el nombre de Bigtable
http://labs.google.com/papers/bigtable.html
Bigtable es un sistema de
almacenamiento de datos distribuido diseñado para almacenar
cantidades de datos del tamaño de ¡petabytes! en miles de
ordenadores. No sigue un modelo relacional, aunque los datos se
encuentran estructurados, y todas las relaciones entre elementos se
encuentran desnormalizadas.
En Bigtable, como en GFS, no se borra
nada, y además las actualizaciones suponen crear nuevos registros,
nunca actualizar los ya existentes. Pensad que los datos están
desnormalizados: cada vez que se actualiza algo se pueden estar
escribiendo muchísimos datos nuevos.
De este modo la estructura de Bigtable
consigue un objetivo claro: un tiempo de respuesta mínimo.
|
Una vez hemos llegado a este punto Tenemos alta disponibilidad, |
2.3 PAAS (Plataform as a Service)
Una vez hemos llegado hasta aquí,
¿qué hacemos con los recursos de los que disponemos?, ¿cómo
podemos utilizarlos?, ¿qué podemos hacer para explotarlos?
En este nivel aparece una capa que te
da acceso a la plataforma que hay por debajo pero ocultándote los
detalles. De este modo desarrollaremos aplicaciones utilizando
una capa que usará unos recursos hardware a los que nosotros nunca
podremos acceder. El almacenamiento infinito, los recursos
ilimitados, la alta disponibilidad, etc ya están garantizadas
gracias al grid, lo que nos encontraremos ahora serán facilidades y
recursos que nos permitirán utilizarlas.
En este sentido PAAS (plataforma como
servicio) actúa como una especie de API. Tus aplicaciones estarán
programadas para funcionar bajo un determinado marco que te permitirá
hacer cosas con esa increíble infraestructura que hay por debajo,
pero no podrás hacer cualquier cosa, tan sólo podrás hacer las
cosas que te estén permitidas hacer.
Y es aquí donde entra en juego el
Google App Engine:
Si usas Google App Engine:
-
Tus aplicaciones se ejecutarán
en los ordenadores de los datacenters de Google. -
Tus ficheros se almacenarán
usando GFS. -
Tus datos se guardarán en
bigtable.
Y además sin tener que
preocuparte de nada,
tan sólo de programar una aplicación que siga las reglas que exige
Google App Engine.
Esto que acabamos de comentar
sirve únicamente para poder ubicar a Google App Engine en su sitio y
para saber qué es realmente. Más adelante hablaremos de nuevo de
Google App Engine y generaremos más tutoriales a los que podréis
acceder, como de costumbre, en adictosaltrabajo.com
2.4 SAAS (Software as a service)
Y con esta capa llegamos a la parte
superior de la pirámide. Tenemos una infraestructura y una serie de
facilidades a nuestro alcance con un único objetivo: el de poder
crear aplicaciones que puedan ser utilizadas por nuestros usuarios
finales o nuestros clientes. Y es que si no tenemos ni usuarios ni
clientes que utilicen las aplicaciones no hay razón por la cual
crear la nube.
Para entender mejor qué es el SAAS
(software como servicio) vamos a intentar describir la situación
actual de las aplicaciones que se utilizan en muchas empresas.
Cuando una empresa contrata un
desarrollo a medida éste suele permanecer en un servidor que se
encuentra físicamente dentro del propio edificio de la organización.
Se contrata el desarrollo, éste se va haciendo, y cada cierto tiempo
algunas personas van a las instalaciones del cliente a instalar una
nueva versión del software en su servidor.
Para ello el cliente tiene en sus
instalaciones un servidor dedicado a albergar la aplicación y,
ocasionalmente, un segundo servidor en el que poder mantener la base
de datos con la información. También necesita tener a alguien
responsable de gestionar sus sistemas, aunque su modelo de negocio no
tenga nada que ver con la informática.
Este responsable de sistemas tendrá
que encargarse de realizar las copias de seguridad, de que los
equipos funcionen correctamente, de tener repuestos por si alguno de
los sistemas fallase, etc.
Suele ocurrir, además, que este tipo
de aplicaciones son utilizadas por empleados que posiblemente no se
encuentren en el mismo edificio en el que esté el servidor de la
aplicación, con lo que hay que mantener una conexión a Internet que
funcione constantemente, hay que disponer de un ancho de banda
adecuado, hay que tener una serie de medidas de seguridad, etc.
Y si la aplicación se hace más
grande, la base de datos crece mucho, o se empiezan a almacenar
muchos ficheros de gran tamaño posiblemente el servidor en el que
está funcionando la aplicación tenga que ser sustituido por otro.
El otro enfoque es el de SAAS, que
aprovecha las ventajas de la nube para eliminar todos estos
problemas. Dicho enfoque apuesta por hacer que tú como cliente no
tengas que tener sistemas dedicados a tener funcionando tu
aplicación, sido que te facilitan los medios necesarios en los que
poder hacer funcionar tu software.
De este modo el propio equipo
encargado de crear la aplicación puede ir actualizando el software
sin tener que desplazarse al edificio del cliente, y es el personal
de la nube quien se encarga de realizar las copias de seguridad, de
poner los medios para que no te quedes sin espacio en disco, de poner
las máquinas necesarias para que no tengas que cambiar de servidor,
etc. Aparte no te tienes que preocupar de tener una conexión a
internet que funcione constantemente con un ancho de banda grande.
El SAAS para los clientes supone
despreocuparse de las infraestructuras necesarias para hacer que la
aplicación funcione y de los problemas técnicos que éstas puedan
acarrear y, para la empresa desarrolladora de software, supone
disponer de un entorno conocido y accesible con el que es más fácil
poder publicar nuevas versiones del software y detectar posibles
errores.
3 Google App Engine
Como hemos visto, Google App
Engine es una plataforma
que nos permite acceder a los recursos de Google con el objetivo de
crear aplicaciones que funcionen en la nube.
Se sitúa por tanto en la capa PAAS de la pirámide.
http://code.google.com/intl/es-ES/appengine/
Dichas aplicaciones, por
naturaleza, funcionarán siguiendo el paradigma del SAAS (Software
como servicio) y dispondrán de una disponibilidad
asegurada en unos recursos
prácticamente infinitos.
http://code.google.com/intl/es/appengine/docs/whatisgoogleappengine.html
El tener nuestra aplicación en la
nube, como clientes, nos supondrá despreocuparnos por la
infraestructura que hace que funcione nuestra aplicación pero,
también como clientes, hará que nos planteemos algunas dudas, como
por ejemplo ¿qué costo tiene todo esto?, ¿puedo usarlo gratis?,
¿qué tamaño pueden tener mis aplicaciones antes de empezar a
pagar?
La última de las preguntas tiene su
respuesta en este enlaces:
http://code.google.com/intl/es-ES/appengine/docs/quotas.html
Como podéis ver el máximo gratuito
es muy muy alto:
-
1.300.000 solicitudes diarias o
7.400 por minuto. -
10 GB de subida y de bajada de
datos diaria o 56 MB por minuto. -
1 GB de almacenamiento en el almacén de datos (el datastore).
-
10.000.000 llamadas al almacén
de datos diarias o 57.000 por minuto. -
7.000 llamadas al API de correo
diarios o 32 llamadas por minuto. -
2.000 destinatarios de correo
electrónico diarios u 8 por minuto. -
…
Aparte, las aplicaciones desarrolladas con Java se encuentran con los siguientes límites:
http://code.google.com/intl/es-ES/appengine/docs/java/runtime.html#Quotas_and_Limits
-
Solicitudes máximas de 10 MB.
-
Respuestas máximas de 10 MB.
-
1000 archivos de aplicación como máximo.
-
1000 archivos estáticos como máximo.
-
10 MB como tamaño máximo de un archivo de aplicación.
-
10 MB como tamaño máximo de un archivo estático.
-
La aplicación completa debe ocupar, como mucho, 150 MB.
En caso de ser necesarios más
recursos estos se pueden contratar y así aumentar los límites, de
hecho las tarifas tienen unos precios económicos.
http://code.google.com/intl/es-ES/appengine/docs/billing.html
Como desarrolladores dispondremos de
una plataforma muy potente cuyo hardware no será accesible. En dicha
plataforma existen una serie de facilidades que nos permitirán poder
crear aplicaciones eliminándonos muchos problemas y facilitándonos
muchos servicios pero, a su vez, limitándonos en otros aspectos.
Los lenguajes con los que podremos
crear aplicaciones para el Google App Engine son Python y Java y los
servicios a los que podremos acceder desde el Google App Engine son
los siguientes:
-
Almacén de datos (el datastore),
donde podremos almacenar toda la información que nuestra aplicación
necesite para funcionar. -
Despliegues, con lo que podremos
poner a nuestra aplicación en funcionamiento. -
Cuentas de Google, que facilitará
la autenticación de usuarios. -
Extracción de URL, que permite
acceder a recursos de internet. -
Correo, ya que las aplicaciones
podrán enviar correos electrónicos. -
Manipulación de imágenes, para
poder rotarlas, recortarlas, ajustar su tamaño, etc. -
Memcache, que permite un acceso
muy rápido a datos que no se encuentren en el almacén de datos. -
Programación de tareas,
servicios que se vayan a a ejecutar a intervalos regulares.
http://code.google.com/intl/es/appengine/docs/whatisgoogleappengine.html
No nos tendremos que preocupar del
mantenimiento de estos servicios, únicamente de usarlos. Aparte
Google facilita un kit de desarrollo con el que facilitarnos el
desarrollar para su plataforma.
http://code.google.com/intl/es/appengine/downloads.html
Sin embargo la propia plataforma
define sus límites, los cuales al programar con Java son los
siguientes:
http://code.google.com/intl/es-ES/appengine/docs/java/runtime.html
-
Las aplicaciones se deben basar
únicamente en un principio de petición-respuesta. -
El tiempo máximo para procesar peticiones es de 30 segundos. Las operaciones que superen ese máximo no terminarán.
-
No se pueden utilizar ni hilos ni
grupos de hilos en las aplicaciones, al igual que tampoco se pueden
crear temporizadores. -
La aplicación no puede crear
nuevos ficheros dentro de su propio ámbito de aplicación. -
Hay métodos de la clase
java.lang.System que no hacen nada y cuya invocación es inútil. -
Se puede utilizar la reflexión en nuestras propias clases sin ninguna limitación, pudiendo mediante este mecanismo incluso cambiar los modificadores de acceso y ejecutar métodos privados. Sin embargo esto último no puede hacerse en las clases del JRE y del API. Puedes utilizar la reflexión contra esas clases pero no cambiar sus modificadores de acceso, con lo que no podrás ejecutar sus métodos privados.
Todo esto es debido a que Google
utiliza su propia versión de la JVM, la cual es compatible con Java
6 pero posee algunas restricciones.
En la siguiente dirección tenéis un
enlace a una pequeña aplicación creada con el Google App Engine:
4 Conclusiones
Una vez el CEO de Sun, JonathanSchwartz, comparó la
evolución del suministro eléctrico con la evolución del suministro
computacional. Hace mucho tiempo cada fábrica disponía de
generadores de electricidad propios con los que poder abastecer sus
necesidades industriales. Dichos generadores tenían que estar
encendidos todo el día, poseían una capacidad máxima que no podían
sobrepasar y ante cualquier avería la fábrica dejaba de funcionar.
Con el tiempo las centrales eléctricas
llegaron a las industrias y muchas fábricas abandonaron los
generadores para añadirse a la red eléctrica. Gracias a ella ya no
tenían que encargarse del funcionamiento y mantenimiento de los
generadores y podían demandar más energía si la necesitaban.
La computación posiblemente todavía
se encuentre en esa primera fase en la cual las empresas poseen
servidores con los cuales poder controlar su negocio. Esto supone
tener personal dedicado a mantenerlo, estar limitados a lo que el
hardware permita y tener que asegurarse de que desde fuera nuestros
empleados pueden utilizar el software.
La nube vendría a ser lo que es ahora
mismo la central eléctrica. Hay una parte que es muy importante para
mi negocio que tengo fuera, que puedo utilizar sin preocuparme por la
disponibilidad, que puedo ampliar fácilmente en caso de necesitarlo
y que no necesito mantener.
En este sentido, ¿es la nube el
futuro de la computación?. La tendencia actual parece indicar que
sí, ya que lo más sensato es no distraer nuestro negocio por
cuestiones tecnológicas y centrarnos en lo que tenemos que hacer,
dejando a otros la responsabilidad de velar por nuestras aplicaciones
y nuestra información. Actualmente hay medios y oferta para
conseguir que esto sea así, así que, ¿por qué no intentarlo?,
¿vamos a tener generadores en nuestras fábricas toda la vida?
5 Referencias
http://www.siliconewhisperer.com/index.php/2009/05/13/what-type-of-cloud-is-right-for-your-business/
http://google.dirson.com/post/3944-google-app-engine/
http://es.debugmodeon.com/articulo/introduccion-a-google-app-engine
http://www.error500.net/articulo/que-es-cloud-computing
http://www.error500.net/desarrollo/plataforma-como-servicio-paas-cloud-computing
http://www.error500.net/software/infraestructura-como-servicio-iaas-cloud-computing


Muy bueno.
buen resumen detallado, valgan las palabras biennn bkn
Hola. Muy completo tu informe que me permitió introducirme, sin muchos conocimientos, en la tecnología de Google. Soy Contador Público, radicado en Buenos Aires, y estoy evaluando la instalación de un ERP que funcione en la nube. Te agradecería si pudieras informarme a quien recurrir.
Muy buen tutorial
Excelente explicación es justo lo que buscaba.
Muy buena explicación, bien detallado y comprensible. Muchas gracias por la información brindada.