
Apache Cassandra, ¿Qué es esto que tanto ruido hace ?
Los fuentes
Lo primero es el enlace a los fuentes de este tutorial
Introducción
Apache Cassandra es una Base de Datos no relacional (NO SQL), distribuida y basada en un modelo de almacenamiento
de Clave-Valor, escrita en Java.
Cuando uno piensa en bases de datos, inevitablemente vienen a la cabeza palabras tales como tablas, primary keys,
foreign keys, integridades referenciales, índices, relaciones y cosas así.
Y cuando uno trata de pasar de un modelo entidad – relación al modelo relacional, piensa en normalización,
en evitar duplicidad de datos, ACID, etc…
Pero no todas las aplicaciones tienen las mismas necesidades de consistencia de datos. Y es que existe un
teorema que explica
que no podemos tener todo (Consistencia, Alta disponibilidad y Tolerancia a fallos) y que hemos de elegir dos.
Y no todas las aplicaciones tienen las mismas necesidades. En algunos casos, nuestras aplicaciones necesitan almacenar
gran cantidad de información que ha de ser accedida de manera casi instántanea y estar disponible 24×7. Pensad en aplicaciones
tipo facebook o twitter (no creo que sea necesario poner los enlaces).
Para este tipo de aplicaciones es donde entra en juego esta nueva forma de plantear los motores de bases de datos.
En este caso la forma de plantearse el modelo de datos es diferente. En un modelo relacional típico, uno crea
un esquema de datos normalizado que permite solicitar cualquier consulta y añade índices a las tablas que permitan acelerar
dichas consultas. En este nuevo esquema de datos, uno ha de plantearse primero que consultas va a realizar y crea el esquema en base
a conseguir el máximo rendimiento en los accesos a esa información y si es necesario duplica los datos para conseguir
mejor rendimiento. Se podrí decir que casi crea un «mapa» de datos apropiado para cada consulta que se vaya a realizar.
Os dejo una serie de enlaces interesantes acerca de Apache Cassandra que he ido encontrando y que aclaran un poco todo esto.
- Modelo de Arquitetura de Apache Cassandra:
-
Modelo o forma de plantear el almacenamiento de los datos:
- Explicación «Oficial»
- Explicación del API del cliente.
-
Thrift: Cliente de más bajo nivel:
- Home del Cliente
- Algunos ejemplos en varios lenguajes
Algunos clientes de alto nivel (wrappers sobre el anterior):
Preparando las herramientas
Antes de comenzar con algunos ejemplos, preparemos el entorno:
Para descargaros la base de datos: Versión 0.6.3 (versión release estable en este momento)
La instalación es muy sencilla, basta con descomprimirlo en algún directorio de vuestro equipo. Es conveniente que una vez descomprimido
configuréis una variable de entorno llamada CASSANDRA_HOME y que apunte a la raíz de la base de datos.
El modelo
Para el ejemplo voy a basarme en el modelo planteado en uno de los enlaces que os puse previamente, y que pretende almacenar información de un blog.
El fichero de configuración principal es «storage-conf.xml» y está en el directorio «conf» de la instalación.
Lo editamos y cambiamos algunas cosas para crear nuestro modelo:
... org.apache.cassandra.locator.RackUnawareStrategy 1 org.apache.cassandra.locator.EndPointSnitch ... 192.168.168.80 192.168.168.80 7000 ...192.168.168.80 9160 ...
El modelo cuenta con:
- Un lugar donde guardar autores: «Autores». Usaremos como clave el pseudónimo del autor (tendrá que ser único)
- Un lugar donde guardar Blogs: «Blogs». Usaremos como clave el título del blog. Entre sus columnas guardará el pseudónimo del autor
- Un lugar donde guardar las entradas de los blogs. Usaremos supercolumnas: La clave de la columna será el título del blog. El nombre de la supercolumna
será un timestamp que permitirá tener las entradas de los blogs ordenadas cronológicamente.
Es un buen momento para arrancar la base de datos y comprobar que la cosa va fina.
En «%CASSANDRA_HOME%\bin» ejecutamos «cassandra -f» y esperamos acontecimientos. Si todo va bien saldrá algo parecido
a:
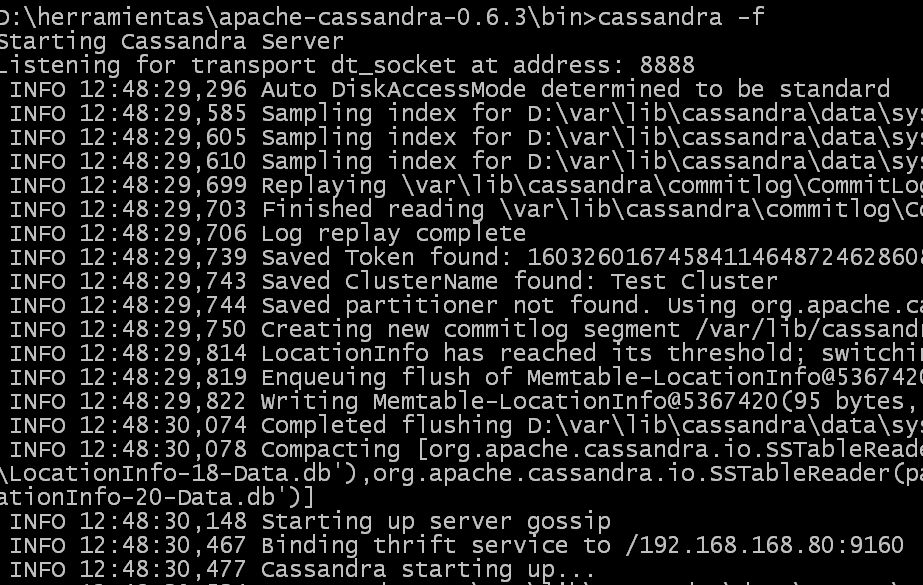
El ejemplo
Nos creamos un proyecto en el eclipse (Proyecto Java normal, no voy a usar Maven porque no aparecen las librerías de clientes
aún en repositorios de Maven).
Configurad en las propiedades del proyecto para incluir en el classpath las librerías de la base de datos.
Éstas están en: «%CASSANDRA_HOME%\lib
Además de estas librerías, he usado otra para generar UUIDs en base al tiempo que he descargado de:
aquí. No olvidéis incluirla también
Os tiene que quedar algo así:
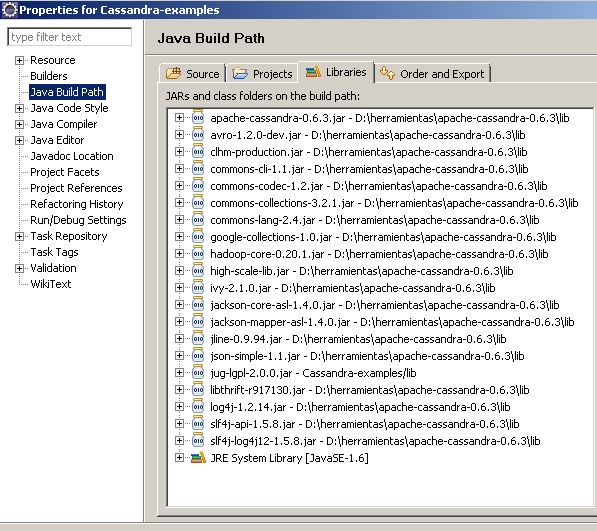
Vamos ahora a crearnos un cliente de prueba que use el API Thrift (de bajo nivel) para insertar y consultar Autores, Blogs y Entradas.
package com.autentia.tutoriales.cassandra;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.io.UnsupportedEncodingException;
import org.apache.thrift.transport.TTransport;
import org.apache.thrift.transport.TSocket;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.TException;
import org.apache.cassandra.thrift.Cassandra;
import org.apache.cassandra.thrift.Column;
import org.apache.cassandra.thrift.ColumnOrSuperColumn;
import org.apache.cassandra.thrift.ColumnParent;
import org.apache.cassandra.thrift.ColumnPath;
import org.apache.cassandra.thrift.ConsistencyLevel;
import org.apache.cassandra.thrift.InvalidRequestException;
import org.apache.cassandra.thrift.Mutation;
import org.apache.cassandra.thrift.NotFoundException;
import org.apache.cassandra.thrift.SlicePredicate;
import org.apache.cassandra.thrift.SliceRange;
import org.apache.cassandra.thrift.SuperColumn;
import org.apache.cassandra.thrift.TimedOutException;
import org.apache.cassandra.thrift.UnavailableException;
import org.safehaus.uuid.UUID;
import org.safehaus.uuid.UUIDGenerator;
public class ThriftClient {
public static final String UTF8 = "UTF8";
public static final String KEYSPACE = "AutentiaModel";
public static final String AUTORES_FAMILY = "Autores";
public static final String BLOGS_FAMILY = "Blogs";
public static final String ENTRIES_FAMILY = "Entradas";
public static void main(String[] args) throws TException,
InvalidRequestException, UnavailableException,
UnsupportedEncodingException, NotFoundException, TimedOutException {
// Poned aquí vuestra IP.
TTransport tr = new TSocket("192.168.168.80", 9160);
TProtocol proto = new TBinaryProtocol(tr);
Cassandra.Client client = new Cassandra.Client(proto);
tr.open();
inserting(client);
reading(client);
tr.close();
}
private static void inserting(Cassandra.Client client)
throws UnsupportedEncodingException, InvalidRequestException,
UnavailableException, TimedOutException, TException {
// Un pseudónimo
String keyAutorID = "torero";
// INSERTAMOS DATOS.
long timestamp = System.currentTimeMillis();
// UN AUTOR
ColumnPath colPathName = new ColumnPath(AUTORES_FAMILY);
colPathName.setColumn("nombre_completo".getBytes(UTF8));
client.insert(KEYSPACE, keyAutorID, colPathName,
"Francisco Javier Martínez Páez".getBytes(UTF8), timestamp,
ConsistencyLevel.ONE);
ColumnPath colPathEmail = new ColumnPath(AUTORES_FAMILY);
colPathEmail.setColumn("email".getBytes(UTF8));
client.insert(KEYSPACE, keyAutorID, colPathEmail,
"fjmpaez@autentia.com".getBytes(UTF8), timestamp,
ConsistencyLevel.ONE);
// UN BLOG
String keyBlogID = "Me gusta Cassandra";
ColumnPath colBlogName = new ColumnPath(BLOGS_FAMILY);
colBlogName.setColumn("autor".getBytes(UTF8));
client.insert(KEYSPACE, keyBlogID, colBlogName,
keyAutorID.getBytes(UTF8), timestamp,
ConsistencyLevel.ONE);
// Entradas al Blog
List blogEntriesColumns = new ArrayList();
blogEntriesColumns.add(new Column("comentario".getBytes("UTF8"),
"Me gusta el futbol, pero también me gusta cassandra".getBytes("UTF-8"), timestamp));
blogEntriesColumns.add(new Column("autor".getBytes("UTF8"),
"amigo_del_torero".getBytes("UTF-8"), timestamp));
UUID uuid = UUIDGenerator.getInstance().generateTimeBasedUUID();
SuperColumn superColumn = new
SuperColumn(uuid.toByteArray(), blogEntriesColumns);
ColumnOrSuperColumn cosc = new ColumnOrSuperColumn();
cosc.setSuper_column(superColumn);
List mutList = new ArrayList();
Mutation mut = new Mutation();
mut.setColumn_or_supercolumn(cosc);
mutList.add(mut);
Map> mapCF = new HashMap>(1);
mapCF.put(ENTRIES_FAMILY, mutList);
Map>> muts =
new HashMap>>();
muts.put(keyBlogID, mapCF);
client.batch_mutate(KEYSPACE, muts, ConsistencyLevel.ONE);
}
private static void reading(Cassandra.Client client)
throws InvalidRequestException, NotFoundException,
UnavailableException, TimedOutException, TException,
UnsupportedEncodingException {
String keyAutorID = "torero";
String keyBlogID = "Me gusta Cassandra";
ColumnPath colPathName = new ColumnPath(AUTORES_FAMILY);
colPathName.setColumn("nombre_completo".getBytes(UTF8));
// Leemos una columna (clave, valor y timestamp)
Column col = client.get(KEYSPACE, keyAutorID, colPathName,
ConsistencyLevel.ONE).getColumn();
System.out.println("--------- Leemos una columna ------");
System.out.println(new String(col.name, UTF8) + ":"
+ new String(col.value, UTF8) + ":" + new Date(col.timestamp));
// Leemos las filas completas de autores...
SlicePredicate predicate = new SlicePredicate();
SliceRange sliceRange = new SliceRange();
sliceRange.setStart(new byte[0]);
sliceRange.setFinish(new byte[0]);
predicate.setSlice_range(sliceRange);
System.out.println("--------- Leemos todas las filas de autores ------");
ColumnParent parent = new ColumnParent(AUTORES_FAMILY);
List results = client.get_slice(KEYSPACE,
keyAutorID, parent, predicate, ConsistencyLevel.ONE);
for (ColumnOrSuperColumn result : results) {
Column column = result.column;
System.out.print(new String(column.name, UTF8) + ":"
+ new String(column.value, UTF8) + ":"
+ new Date(column.timestamp)+" | ");
}
System.out.println("----------------------------");
// Leemos las entradas del blog
System.out.println("--------- Leemos todas los comentarios del blog ------");
parent = new ColumnParent(ENTRIES_FAMILY);
results = client.get_slice(KEYSPACE, keyBlogID, parent, predicate, ConsistencyLevel.ONE);
for (ColumnOrSuperColumn result : results) {
SuperColumn superColumn = result.super_column;
UUID uuid = new UUID(superColumn.name);
System.out.println(uuid.toString() + " [ ");
for (Column column : superColumn.columns) {
System.out.print(new String(column.name, UTF8) + ":"
+ new String(column.value, UTF8) + ":"
+ new Date(column.timestamp)+" | ");
}
System.out.println(" ] ");
}
}
}
Si ejecutamos el cliente (con la base de datos levantada…)
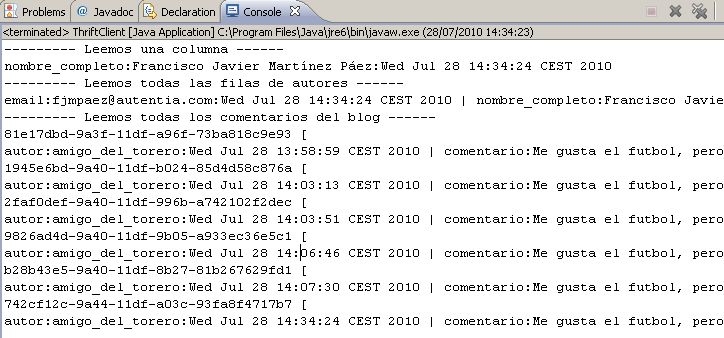
El cluster
En modo receta:
- Paramos la base de datos local y editamos el fichero «storage-conf.xml» para indicarle las
máquinas del cluster:192.168.168.80 192.168.168.7 - Descomprimimos en otra máquina la base de datos tal y como hicimos antes y sustituimos el fichero «storage-conf.xml» por el que ya tenemos.
- Modificamos las IPs siguientes en el fichero «storage-conf.xml» de la nueva máquina:
...
192.168.168.7 7000 ...192.168.168.7 9160 - Arrancamos las dos bases de datos: En «%CASSANDRA_HOME%\bin» de ambas máquinas ejecutamos «cassandra -f»
Al arrancar la máquina antigua dice:

Si queréis información del cluster, en «%CASSANDRA_HOME%\bin» ejecutad «nodetool -host localhost ring»
Ahora cambiad la IP del código del cliente y poned la nueva. Comentad también la parte de insertar. Mola ¿ no ?. Y sin pagar un duro.
Bueno, creo que es suficiente como primera aproximación. Espero que os haya servido para enteder un poco todo este tema que con tanta fuerza está entrando en nuestro mundillo.


¡Yo creo que este tema es muy interesante, y que el cambio de enfoque de datos ya iba siendo hora!
Gracias Paco y gracias a Apache.
Gracias! No conocía esta herramienta…
Saludos…
Muy buen tutorial, tengo aproximadamente 4 meses trabajando en cassandra.
es una herramienta poderosa la cual aun no conosco mucho…
hoy en dia tengo un duda con cassandra, estoy utilizando una estructura simple una familia de columna
ejemplo:
Blog:{
key:{
columna: valor
}
}
Quiero saber si existe alguna forma de si tengo una lista de keys, poder insertar un valor a la columna, sin tener que iterar. como en el ejemplo el key seria de blog, en mi caso tengo una lista de usuarios y quiero insertarle una columna a cada usuario.
trabajo en java, estuve viendo sobre batch_mutate pero no lo entendi del todo o creo que no es lo que busco porque especifican un solo key, en mi caso tengo una lista de keys con la misma columna, si me ayudara seria de gran favor para mi, gracias.
Gracias por el tutorial.
Saludos,