
Introducción a Apache Solr.
0. Índice de contenidos.
- 1. Introducción.
- 2. Entorno.
- 3. Primeros pasos.
- 4. Indexación y recuperación de documentos.
- 5. Referencias.
- 6. Conclusiones.
1. Introducción
Apache Solr es un motor de búsqueda de código abierto que proporciona una capa
de abstracción sobre Apache Lucene. Solr se define como la «serverización» de Lucene.
Sus características son las siguientes:
- permite realizar peticiones HTTP para indexar o consultar documentos: se podría decir que tiene un api estilo REST, aunque no hace uso de todos
los verbos, sí permite la recuperación de documentos en formato XML y JSON, - incluye caches internas para devolver con mayor rapidez el resultado de las consultas,
- incluye una administración web que permite: consultar estadísticas de rendimiento, incluyendo el uso de cache, realizar búsquedas mediante un
formulario, navegar por los términos más populares del índice, visualizar un desglose detallado de las matemáticas de puntuación y las fases de
análisis de texto. Si habéis trabajado antes con Lucene se asemeja bastante a la aplicación Luke. - permite la configuración de la indexación y recuperación de documentos mediate ficheros de configuración xml: añade una librería de analizadores
textuales a los que provee por defecto Lucene, introduce el concepto de campo tipado, lo que permite introducir fechas y mejorar la ordenación, - añade mejoras a las consultas básicas de Lucene,
- incluye navegación por facetas en las búsquedas,
- integra el plugin de Lucene para la recuperación de contenido con resaltado de sintaxis en las coincidencias,
- dispone de un plugin de «spell check» o revisión gramatical, para realizar recomendaciones de búsqueda,
- dispone de un plugin de búsqueda de documentos similares,
- permite el manejo de documentos ricos (word, pdf, …) básandose en el proyecto Apache Tika, basado en el antiguo Lius,
- esta escrito en Java, se trata de una aplicación web que se puede desplegar en cualquier contenedor de servlets,
- esta preparado para su despliegue en alta disponibilidad.
Recientemente han liberado la versión 3.1, haciendo coincidir el número de versión con la última versión de Lucene y entre sus nuevas características
podemos encontrar:
- soporta geolocalización en los documentos, de modo que podemos realizar búsquedas con un filtro de distancia,
- soporta como formato de respuesta CSV,
- podemos restringir la navegación de facetas por rangos numéricos,
- incorpora un componente de autocompletado que denominan «suggester»,
- permite la ordenación de resultados haciendo uso de funciones,
- incorpora una web de ejemplo basada en plantillas de velocity que permite acceder a todas estas nuevas funcionalidades http://localhost:8983/solr/admin/,
En este tutorial vamos a mostrar cómo descargar y hacer correr la última versión de Apache Solr y cómo realizar una prueba de concepto indexando y recuperando sus documentos de prueba
a través de su propia interfaz de búsqueda.
2. Entorno.
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 17′ (2.93 GHz Intel Core 2 Duo, 4GB DDR3 SDRAM).
- Sistema Operativo: Mac OS X Snow Leopard 10.6.7
- Apache Solr 3.1.
3. Primeros pasos.
Lo primero es descargarnos Solr de la siguiente ubicación
http://www.apache.org/dyn/closer.cgi/lucene/solr/;
nos descargamos un fichero comprimido y lo descomprimimos en disco.
La distribución de Solr viene con un servidor jetty que nos permite arrancar una versión con un mínimo esfuerzo. Otra cosa será como instalar
Solr en producción, pero eso se escapa del objetivo de este tutorial.
Dentro de la distribución de Solr podemos encontrar un directorio example con un Solr instalado en un jetty, para arrancarlo basta con ejecutar
java -jar start.jar en dicho directorio. Si todo va bien tendremos una salida por consola con está última línea:
2011-04-25 11:57:29.218:INFO::Started SocketConnector@0.0.0.0:8983
Indicándonos el puerto para acceder al jetty que contiene la aplicación web de Solr.
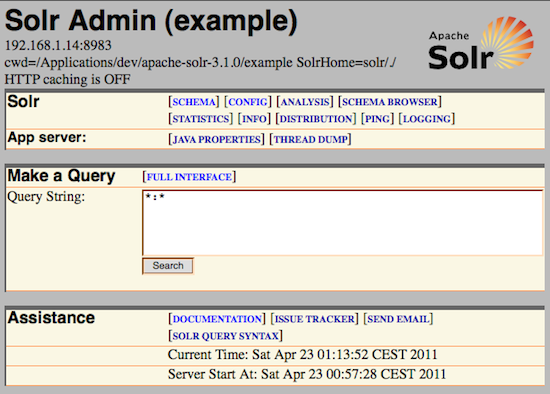
Para acceder a la adminsitración de Solr, basta con acceder a la siguiente url:
http://localhost:8983/solr/admin/
Para acceder a la nueva página de búsqueda de Solr, basta con acceder a la siguiente url:
http://localhost:8983/solr/browse/
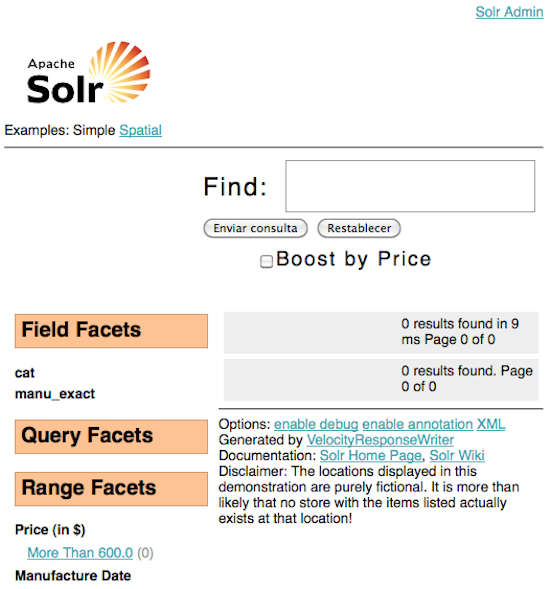
El índice esta vacío, con lo que lo primero es indexar documentos.
4. Indexación y recuperación de documentos.
Dentro del directorio example/exampledocs de la distribución de Solr podemos encontrar documentos para indexar y realizar pruebas. Para indexarlos
todos basta con ejecutar el script ./post.sh *.xml que se conecta al api REST de Solr y realiza un update del documento xml que contiene
cada uno de los ficheros.
<add><doc> <field name="id">MA147LL/A</field> <field name="name">Apple 60 GB iPod with Video Playback Black</field> <field name="manu">Apple Computer Inc.</field> <field name="cat">electronics</field> <field name="cat">music</field> <field name="features">iTunes, Podcasts, Audiobooks</field> <field name="features">Stores up to 15,000 songs, 25,000 photos, or 150 hours of video</field> <field name="features">2.5-inch, 320x240 color TFT LCD display with LED backlight</field> <field name="features">Up to 20 hours of battery life</field> <field name="features">Plays AAC, MP3, WAV, AIFF, Audible, Apple Lossless, H.264 video</field> <field name="features">Notes, Calendar, Phone book, Hold button, Date display, Photo wallet, Built-in games, JPEG photo playback, Upgradeable firmware, USB 2.0 compatibility, Playback speed control, Rechargeable capability, Battery level indication</field> <field name="includes">earbud headphones, USB cable</field> <field name="weight">5.5</field> <field name="price">399.00</field> <field name="popularity">10</field> <field name="inStock">true</field> <!-- Dodge City store --> <field name="store">37.7752,-100.0232</field> <field name="manufacturedate_dt">2005-10-12T08:00:00Z</field> </doc></add>
La estructura de documento xml hace referencia a nombres de campos y contenido de los mismos.
En la instalación de Solr de ejemplo vienen preconfigurados una serie de campos para nuestros documentos, comunes para todos, con una tipología.
Dichos campos los podemos encontrar en el documento xml de configuración example/solr/conf/schema.xml
Los campos susceptibles de formar parte de los documentos indexados se basan en esa definición de tipos de datos.
Las caracteristicas de los campos son las comunes en Lucene: indexed, stored, name,… pero además permite campos multivaluados,
permite la definición dinámica de campos, permite la copia del contenido de un campo en otro, para facilitar el uso de distintos
tipos de filtros textuales….
La definición de los analizadores o filtros se realiza en Solr a nivel de definición del tipo de dato.
Permite declarar una cadena de analizadores, los que provee de base Lucene y añade algunos otros.
Con el comando anterior lo que hemos hecho es insertar una serie de productos en Solr, podríamos insertar más, en formato xml y, como estamos
en versión 3.1, también en formato JSON.
Para recuperarlos, vamos a acceder primero a la opción de búsqueda de la página de administración de Solr. Podemos buscar por ipod
obteniendo, por defecto, este tipo de resultado.

La url que consultamos es esta: http://localhost:8983/solr/select/?q=ipod&version=2.2&start=0&rows=10&indent=on
Aunque también podemos cambiar el tipo de respuesta a JSON, añadiendo a la url el parámetro wt=json
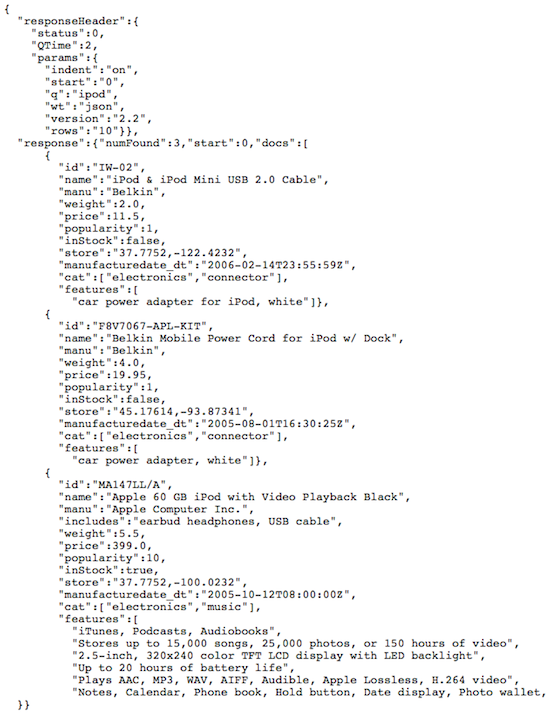
La url que consultamos es esta otra: http://localhost:8983/solr/select/?q=ipod&version=2.2&start=0&rows=10&indent=on&wt=json
Si probamos con wt=csv, el formato de respuesta será un CSV.
Si accedemos a la página de búsqueda decorada y facetada buscando por el mismo término, obtendremos los mismos resultados con la siguiente información
adicional y el siguiente formato:
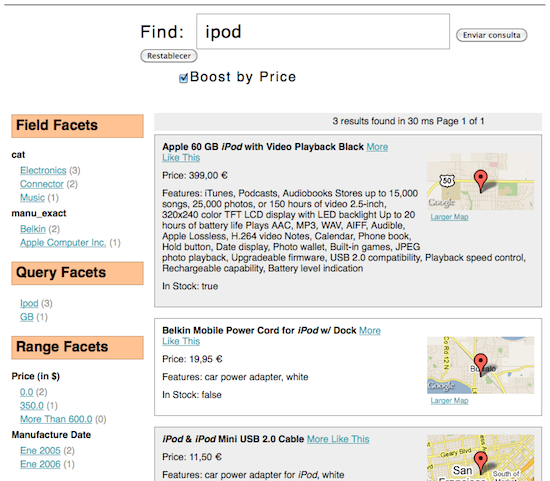
A resaltar:
- el listado de productos decorado con una miniatura generada haciendo uso del api de google maps para geolocalizar la ubicación de la tienda física,
- el resultado facetado por la categoría de producto y la manufactura, esto es, el fabricante,
- un ejemplo de facetado por rango de precio y de fecha de fabricación
5. Referencias.
6. Conclusiones.
La potencia de Lucene accesible como un servicio en red mediante un protocolo HTTP ligero, ¿qué más se puede pedir?, que soporte distintos analizadores
para un mismo campo a través de copias, que soporte distintos analizadores para indexación y búsqueda, que soporte búsqueda por facetas y además por
rangos, que soporte búsqueda por documentos similares, que soporte geolocalización y búsqueda con filtro de distancia… lo dicho ¿qué más se puede
pedir?
En breve veremos cómo indexar y recuperar documentos haciendo uso del api de java. Stay tuned!
Un saludo.
Jose


Muy interesante.
Como indexas PDFs o Docx?
Gracias
Solr es brutal lo que puede ofrecer,la capacidad de respuesta en búsquedas con cores de millones de registros son milesimas de segundo.
Muy bien explicado el tutorial, thx!!!
Gracias por la introduccion