
Vamos a dar un pequeño paseo por el framework de computación paralela más popular del momento, Apache Spark.
Índice de contenidos
- 1. Introducción
- 2. Apache Spark y la ciencia de datos
- 3. Instalación del entorno Scala + Apache Spark
- 4. Jugando con Datasets y Spark-shell
- 5. Conclusiones
- 6. Referencias
1. Introducción
Con todo el revuelo que se está montando alrededor del mundo del Big Data y con la asistencia al evento técnico Big Data Spain 2015 del equipo de Autentia (del que ya hicimos dos entradas sobre nuestras impresiones: primer día y segundo día), nos ha parecido una buena idea investigar y cacharrear con las herramientas que más sonaron durante las conferencias.
Comenzamos con el ya rey de la computación paralela, Apache Spark, proyecto de la fundación Apache que más interés está suscitando en el mundo del Big Data.
2. Apache Spark y la ciencia de datos
Apache Spark es un framework computación en clúster de código abierto que se diferencia con Hadoop (el otro gran proyecto de este tipo) en el uso de operaciones en memoria divididas en varias fases de procesamiento. Hadoop, como es bien conocido, hace uso del clásico modelo de programación publicado por Google MapReduce.
Debido al cambio de contexto que está sufriendo la ciencia de datos, el nuevo enfoque de Apache Spark pasando del procesamiento en batch al streaming, permitiendo la exploración de datos ad hoc, así como la aplicación más sencilla de algoritmos de machine learning es el factor de diferenciación básico de este proyecto.
No es el objetivo de este tutorial ahondar mucho en el funcionamiento interno del framework, sin embargo cabe destacar que, en su versión out-of-the-box, lleva incluidas librerías específicas para tratar datos estructurados (Spark SQL), capacidades para el streaming de datos (Spark Streaming), machine learning (MLib) y computación sobre grafos (GraphX).
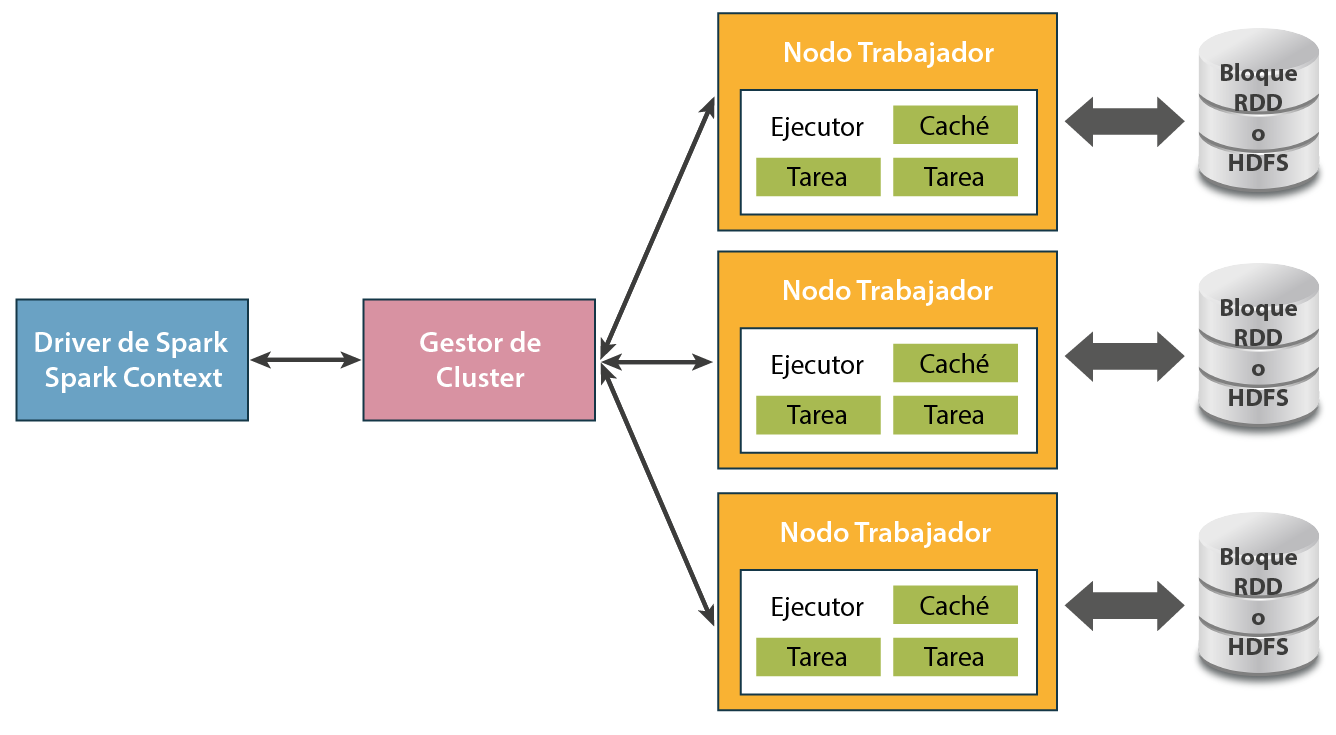
2.1. Arquitectura de la computación en clúster
Las aplicaciones para Spark se ejecutan como un grupo independiente de procesos en clústeres, coordinados por el objeto SparkContext. Más específicamente, SparkContext puede conectarse a gestores de clúster que son los encargados de asignar recursos en el sistema. Una vez conectados, Spark puede encargar que se creen ejecutores o executors encargados de la computación en los nodos del clúster. Los trozos de código propio de los que se encargan estos ejecutores son denominados tasks o tareas.
2.2. Conceptos clave
Repasemos a continuación los conceptos básico sobre los que se apoya Apache Spark para realizar su magia.
SparkContext
Se trata del context básico de Spark, desde donde se crean el resto de variables que maneja el framework. Sólo un SparkContext puede estar activo por JVM.
En la shell interactiva de Spark es creada automáticamente bajo el nombre sc, mientras que en otros entornos es necesario instanciarlo explícitamente. La configuración de SparkContext puede ser definida mediante un bundle específico llamado SparkConf.
RDDs
Viene de las siglas en inglés de Resilient Distributed Datasets o, en castellano, «conjuntos distribuidos y flexibles de datos». Según la propia documentación de Spark, representan una colección inmutable y particionada de elementos sobre los que se puede operar de forma paralela.
Dependiendo del origen de los datos que contiene, diferenciamos dos tipos de RDDs:
- Colecciones paralelizadas basadas en colecciones de Scala.
- Datasets de Hadoop creados a partir de ficheros almacenados en HDFS.
Son posibles dos operaciones bien diferenciadas sobre un RDD, dependiendo del resultado final:
- Transformaciones, que crean nuevos conjuntos de datos, como puede ser la operación map() que pasa cada elemento por una determinada función y devuelve un nuevo RDD con el resultado.
- Acciones, que devuelven un valor al driver del clúster después de llevar a cabo una computación sobre el conjunto de datos. Un ejemplo de este tipo es la función reduce(), que agrega todos los elementos de un RDD mediante una función y devuelve el resultado.
3. Instalación del entorno Scala + Apache Spark
3.1. Scala
Nosotros vamos a hacer esta introducción a Spark con Scala (también soporta Python, R y Java), por lo que deberemos descargarlo de la página oficial y moverlo a una localización de nuestra elección:
wget http://downloads.typesafe.com/scala/2.11.7/scala-2.11.7.tgz tar zxvf scala-2.11.7 sudo mv scala-2.11.7 /usr/local/scala-2.11.7 sudo ln -snf /usr/local/scala-2.11.7 /usr/local/scala echo "export SCALA_HOME=/usr/local/scala" >> ~/.bash_profile
El directorio $SCALA_HOME/bin debería ser añadido también al PATH del sistema para poder acceder a los binarios desde cualquier localización.
Comprobemos que la instalación se ha realizado correctamente:
$> $SCALA_HOME/bin/scala -version Scala code runner version 2.11.7 -- Copyright 2002-2013, LAMP/EPFL
3.2. Apache Spark
Nosotros vamos a bajarnos directamente el framework de Spark, aunque es posible (y preferible en entornos más serios) incluir el artefacto Maven en nuestro proyecto:
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.5.1</version> </dependency>
Vamos a la página oficial de descarga, eligiendo la última release. Aquí se nos presentan varias opciones:
- Código fuente listo para compilar por nosotros mismos que permite el uso de la versión de Hadoop que deseemos. Nosotros elegiremos esta opción por su flexibilidad.
- Pre-compilado a falta de la dependencia de Hadoop, que la debemos suministrar nosotros.
- Pre-compilado con diferentes versiones de Hadoop integradas.
Descargamos el fichero y lo descomprimimos:
wget http://d3kbcqa49mib13.cloudfront.net/spark-1.5.1.tgz tar zxvf spark-1.5.1.tgz
Lo movemos a la localización que deseemos como hicimos con Scala:
sudo mv spark-1.5.1 /usr/local/spark-1.5.1 sudo ln -snf /usr/local/spark-1.5.1 /usr/local/spark
Es hora de compilar el framework como nos dice en su fichero README.md:
sudo mvn -DskipTests clean package
Dependiendo del entorno en el que trabajemos, ésta compilación será más o menos costosa. En mi caso fueron unos 25 minutos. Por último, es conveniente declarar la variable de entorno $SPARK_HOME y añadir $SPARK_HOME/bin al $PATH del sistema, como hicimos en la instalación de Scala.
Para comprobar que todo se ha instalado de forma correcta, abramos una sesión en el REPL de Spark, que es con lo que trabajaremos durante todo el tutorial:
$> spark-shell
Using Spark's repl log4j profile: org/apache/spark/log4j-defaults-repl.properties
To adjust logging level use sc.setLogLevel("INFO")
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.5.1
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_79)
Type in expressions to have them evaluated.
Type :help for more information.
Spark context available as sc.
SQL context available as sqlContext.
scala>
4. Jugando con Datasets y Spark-shell
4.1. Procesado en batch
Algo que buscamos todos cuando se empieza a buscar información sobre Big Data son Datasets interesantes y grandes para jugar con ellos. En ésta pagina podéis encontrar una colección de enlaces a páginas con montones de datasets públicos listos para usarse.
Nosotros hemos elegido el de salarios de los empleados públicos de la ciudad de Chicago, en EEUU. Un vistazo rápido para saber con qué estamos trabajando (se ha formateado el fichero de CSV a TSV):
Name Position Title Department Employee Annual Salary AARON ELVIA J WATER RATE TAKER WATER MGMNT 88968.00 AARON JEFFERY M POLICE OFFICER POLICE 80778.00 AARON KARINA POLICE OFFICER POLICE 80778.00 AARON KIMBERLEI R CHIEF CONTRACT EXPEDITER GENERAL SERVICES 84780.00
Abramos una sesión del REPL de Spark, si no la tenemos abierta:
spark-shell
Lo primero que debemos hacer siempre es cargar el dataset en el contexto de Spark. Recordemos que SparkContext se instancia automáticamente bajo el objeto sc:
scala> val rawData = sc.textFile("Current_Employee_Names__Salaries__and_Position_Titles_formatted.csv")
rawData: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at textFile at <console>:21
Definiremos ahora una clase de Scala que represente un empleado:
scala> case class Employee(name: String, positionTitle: String, department: String, annualSalary: Float) defined class Employee
Ahora sí, carguemos un RDD con el dataset:
scala> val employees = rawData.map(_.split("\t")).map(r => Employee(r(0), r(1), r(2), r(3).toFloat))
employees: org.apache.spark.rdd.RDD[Employee] = MapPartitionsRDD[3] at map at <console>:25
Es fácil entender ésta última operación: con todos los datos crudos, dividimos mediante tabulaciones y mapeamos cada columna a su atributo correspondiente de la clase Employee.
Si estás siguiendo este tutorial a la vez que escribes en la spark-shell, comprobarás que ninguna operación está siendo llevada a cabo, si no que éstas órdenes se están añadiendo a un buffer que se ejecutará en cuanto sea necesario una computación sobre los objetos.
Contemos el número de registros en el RDD:
scala> employees.count() res0: Long = 32181
Es en las acciones cuando todas las operaciones dependientes son evaluadas. count() es una acción, así como reduce(), como hemos explicado en los conceptos clave.
Podemos jugar un poco más con este RDD. Por ejemplo, vamos a obtener el número de empleados que trabajan en un departamento con la palabra «FIRE» en el nombre:
scala> employees.filter(em => em.department.contains("FIRE")).count()
res1: Long = 4875
También podemos mostrar estos registros con la función collect():
scala> employees.filter(em => em.department.contains("FIRE")).collect()
res2: Array[Employee] = Array(Employee(ABBATEMARCO JAMES J,FIRE ENGINEER,FIRE,90456.0), Employee(ABDELLATIF AREF R,FIREFIGHTER (PER ARBITRATORS AWARD)-PARAMEDIC,FIRE,98244.0), Employee(ABDOLLAHZADEH ALI,FIREFIGHTER/PARAMEDIC,FIRE,87720.0), Employee(ABDULLAH DANIEL N,FIREFIGHTER-EMT,FIRE,91764.0), ....
4.2. Spark Streaming
Como hemos comentado antes, el core de Apache Spark viene con una serie de librerías para diferentes áreas de Big Data. Entre ellas se encuentra Spark Streaming, evidentemente para el manejo de streaming de datos.
Vamos a ilustrar un pequeño ejemplo de uso de ésta librería con el HelloWorld del mundo del Big Data: WordCount o conteo de palabras en un texto.
Como servidor de streaming, vamos a utilizar el binario de UNIX netcat en modo contínuo y emitiendo en el puerto 9999:
nc -lk 9999
En nuestra spark-shell en otra consola diferente del netcat escribiremos lo siguiente:
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val ssc = new StreamingContext(sc, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
Como se puede ver, hemos importado la librería de streaming. El contexto que necesitamos usar ahora es StreamingContext, con un ratio de muestreo de 1 segundo. A la instancia de este contexto es necesario pasarle un SparkContext; como estamos en la shell, será sc.
Por último, abrimos un socket de texto en localhost en el puerto 9999, que es donde se encuentra sirviendo el netcat.
Implementemos ahora el algoritmo de WordCount:
// Dividimos las palabras por espacios
val words = lines.flatMap(_.split(" "))
// Creamos pares clave-valor con cada palabra
val pairs = words.map(word => (word, 1))
// Agregamos todas las palabras coincidentes
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
Lo único que nos falta por hacer es comenzar el servicio de streaming y dejarlo a la espera:
ssc.start() ssc.awaitTermination()
Ahora podemos escribir lo que queramos en la consola del netcat y veremos el conteo funcionando en la spark-shell:
// En netcat lorem ipsum dolor sit dolor lorem amet // En spark-shell (sit,1) (ipsum,1) (dolor,2) (amet,1) (lorem,2)
5. Conclusiones
Hemos visto una introducción muy básica de cómo trabajar con Apache Spark, escribiendo nuestros aplicaciones en Scala, tanto en el batch processing más tradicional, así como en streaming. El siguiente paso podría ser crear un proyecto en Scala con Maven y conectarnos a una HDFS gestionada por Hadoop, o utilizar la API de streaming de Yahoo! Finance para análisis en tiempo real.
6. Referencias
- Spark Overview
- Apache Spark Documentation for Scala
- Recopilación de ‘Getting Started’ en Apache Spark


Hola , vi tu publicacion en internet sobre spark y quisiera consultarte algo si me das un comentario tuyo: Se podria integrar el SPARK a ROCKS CLUSTER o usar un metodo de integracion entre BIG DATA(Spark) con HPC(Oscar,Rocks)…. Muy gentil por tu colaboracion..
Por ejemplo para visualizacion de imagenes medicas de gran tamaño
Estaría bien que pusieras un link al fichero ya convertido para no tener que ir convirtiendolo, ya que la gracia es poder probar spark directamente sin preocuparte de formatos
Gracias por la introducción
Muchas gracias por el aporte, me sirvió mucho.