
Introducción a la Sandbox HDP – Hortonworks Data Platform
0. Índice de contenidos.
1. Introducción.
En este tutorial vamos a tratar sobre la Sandbox de Hortonworks, una máquina virtual que se distribuye de forma abierta con un montón de aplicaciones para proyectos de Big Data. Todos los proyectos instalados en la máquina virtual tienen licencia de ASF – Apache Software Foundation. Hortonworks es una empresa fundada en 2011 y contribuidora del proyecto Apache Hadoop. Es uno de los principales proveedores de soluciones Big Data con el ecosistema de Hadoop que existen actualmente.
La Sandbox HDP es muy útil para tener instalado en una máquina de desarrollo una arquitectura Big Data con la que poder hacer pruebas de concepto o pequeños procesos de análisis y procesado de datos sin necesidad de tener que instalar, configurar y mantener este software con los costes que ello supone.
La base de HDP (Hortonworks Data Platform) es Hadoop y el sistema de archivos distribuidos HDFS. También vienen instalados el framework Pig para scripts de procesos MapReduce, Hive y HCatalog para lanzar queries sobre conjuntos de datos, Storm para el procesado de datos en real time, Kafka, Solr, Spark, HBase, Ambari, etc.
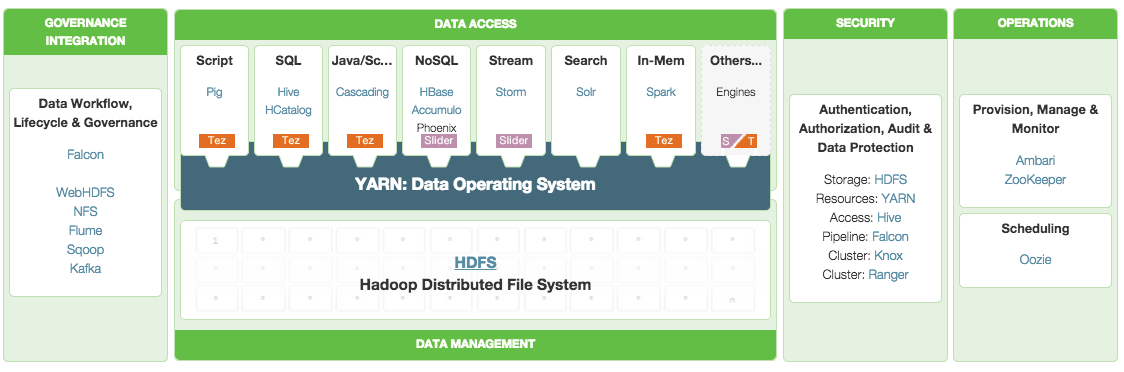
Fuente: Hortonworks
En este tutorial vamos a ver la forma de instalar la máquina virtual y a trastear un poco con las utilidades que vienen instaladas.
2. Entorno.
El tutorial se ha realizado con el siguiente entorno:
- MacBook Pro 15′ (2.4 GHz Intel Core i5, 8GB DDR3 SDRAM).
- VirtualBox
- Hortonworks Data Platform 2.2
3. Instalación
Lo primero será descargarnos la máquina virtual de la página oficial. Está disponible para VirtualBox , VMWare e Hyper-V.
Las características de la máquina virtual son:
- Arquitectura de 32 o 64 bits (Windows XP, Windows 7, Windows 8 y Mac OSX)
- 4Gb de RAM. Si arrancas Ambari o HBase se requiren 8Gb.
- 2 procesadores
- 8Mb de memoria de vídeo
- Sistema operativo Red Hat
Una vez descargada la abrimos, en mi caso con VirtualBox:
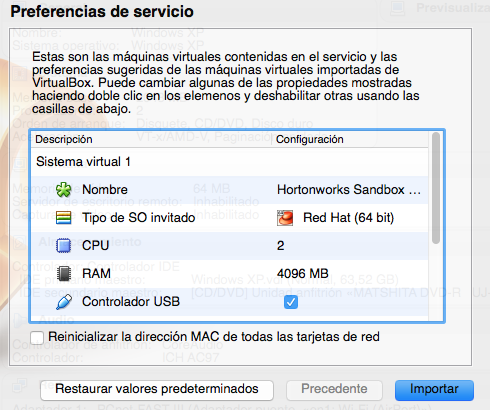
Paciencia que tarda un rato el proceso de instalación.
Y finalmente arranca mostrando lo siguiente.
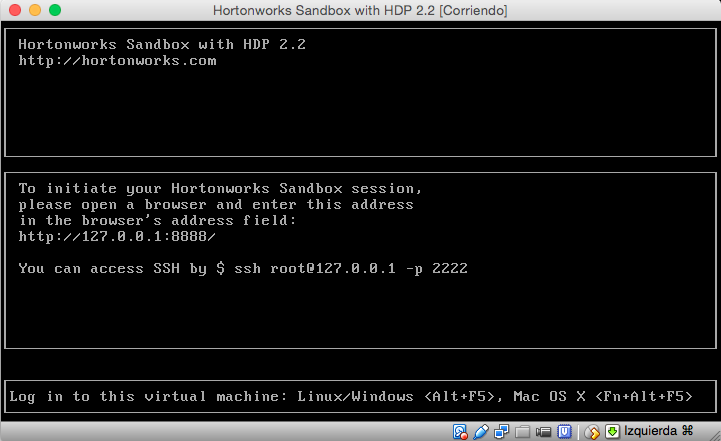
4. Herramientas de la Sandbox
La máquina virtual no tiene entorno gráfico. Levanta un servidor web en la URL http://127.0.0.1:8888/ para inicialiar la sesión en la Sandbox. Abrimos un navegador desde nuestra máquina anfitriona y entramos en dicha URL.
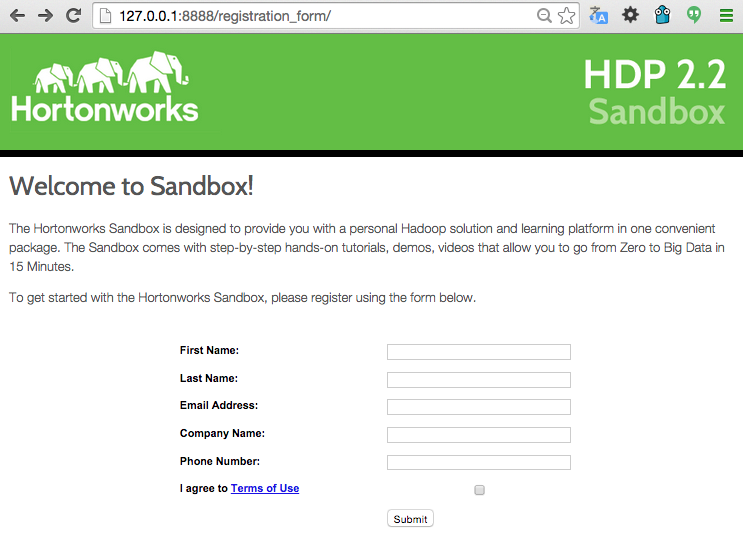
Nos pide una serie de datos de registro y una vez introducidos entramos en la Sandbox.

Aquí nos indica que la interfaz web para utilizar los servicios de la Sandbox está en la URL http://127.0.0.1:8000/. Usuario ‘hue’, password ‘1111’.
También podemos entrar por SSH, algo muy útil para poder ver la configuración de los distintos servicios y poder lanzar y gestionar las aplicaciones:
ssh root:127.0.0.1 -p 2222
Desde la interfaz web resulta sencillo ver los servicios disponibles como por ejemplo Hive o Pig. Con Hive podemos crear tablas estructuradas para cargar datos y proporciona un subconjunto de SQL para operar con ellos. Por debajo las queries que escribimos son convertidas a jobs MapReduce. Con Pig se hace algo parecido pero con una sintaxis propia más de scripts.
Comprobamos mediante el comando ‘jps’ los procesos Java levantados:
[root@sandbox ~]# jps 2269 Portmap 2778 RunJar 1761 DataNode 2673 ResourceManager 2271 Nfs3 3101 RunJar 3343 gateway.jar 1735 SecondaryNameNode 2071 Bootstrap 2533 RunJar 1737 NameNode 2040 QuorumPeerMain 2769 JobHistoryServer 15334 -- process information unavailable 2655 ApplicationHistoryServer 18166 Jps 4550 UnixAuthenticationService 1486 ldap.jar 2664 NodeManager 1180 EmbededServer 2942 Main
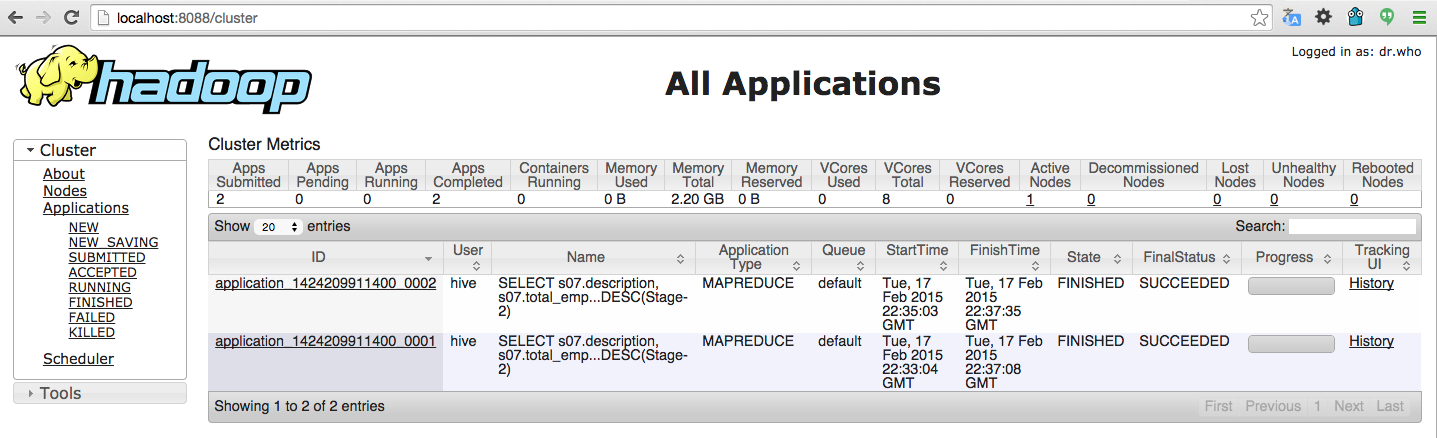
Para acceder al interfaz WebUI del cluster de Hadoop entramos desde un navegador de la máquina anfitriona a http://localhost:8088/cluster. Desde aquí podemos realizar el seguimiento de los jobs que se vayan ejecutando, los logs, el histórico de jobs ejecutados, la configuración de MapReduce, etc.
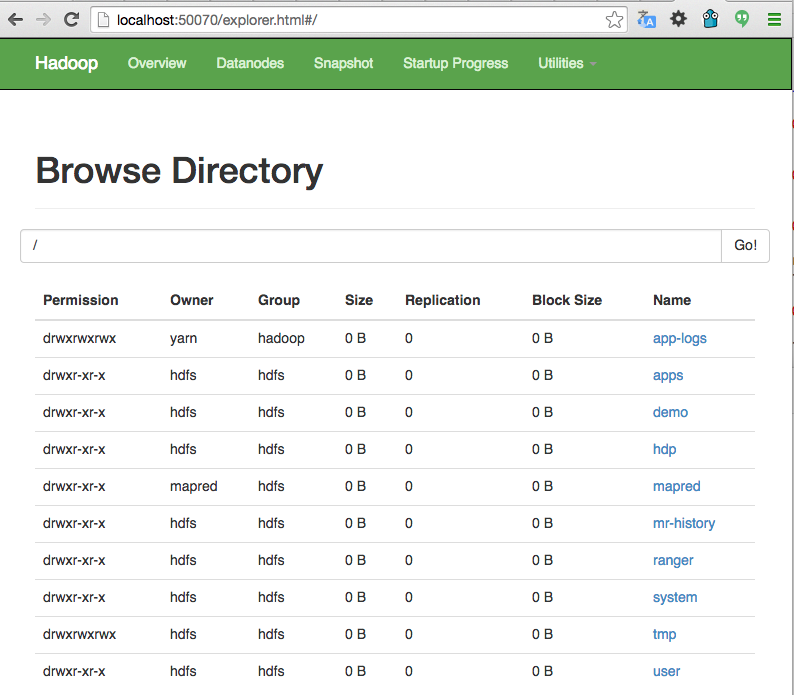
Otra interfaz muy útil para ver el filesystem HDFS es mediante http://localhost:50070/explorer.html#/. Desde aquí podemos ver el contenido del sistema de ficheros, tamaño de los archivos, permisos, información del NameNode, etc.
Por último mencionar que al tener acceso total a la máquina por ssh podemos arrancar, parar, configurar y en general utilizar todos los servicios disponibles de la máquina virtual lo que nos da una libertad total. Y si rompemos algo y no sabemos volver a hacerlo funcional, bastará con instalar una nueva máquina virtual 🙂
5. Conclusiones.
En este tutorial hemos visto la manera de tener un montón de herramientas instaladas y listas para utilizar de una forma muy sencilla. Si estás pensando en iniciarte en algunas de las herramientas más utilizadas para análisis de grandes volúmenes de datos y no quieres perder tiempo instalando y configurando, la opción de utilizar la Sandbox de Hortonworks es una buena recomendación. También si tienes que hacer alguna prueba de concepto sobre alguna de estas tecnologías y te da pereza montar una máquina con todo lo necesario.
Por otro lado se aprende mucho viendo los ficheros de configuración de las distintas herramientas en una máquina 100% operativa por si tuvieras que montar alguna vez un sistema parecido.
Espero que te haya sido de ayuda.
Un saludo.
Juan


Muy bueno, me fue de mucha utilidad, gracias.
Hola, muy bueno tu introducción sobre el tema, quisiera saber cuales fueron las características del pc físico para soportar la maquina virtual. Muchas gracias.