
Como intentar averiguar el juego de caracteres de un archivo
0. Índice de contenidos.
- 1. Introducción.
- 2. Entorno.
- 3. Requisitos previos.
- 4. Descripción de los juegos de caracteres.
- 5. Usando librerías para averiguar el encoding.
- 6. Conclusiones.
- 7. Referencias.
1. Introducción
Cuando recibimos un archivo, si queremos leerlo correctamente, debemos saber en que codificación se ha guardado para utilizar la misma codificación a la hora de leerlo. Si nos equivocamos de codificación, seguramente nos aparecerán caracteres extraños o no reconocibles.
El encoding es la correspondencia que damos a un carácter de un determinado juego de caracteres con un número que le identifica. Por ejemplo, si esogemos ASCII como juego de caracteres, vemos que para representar la letra A se utiliza el número 65. Los principales juegos de caracteres, o por lo menos los que con mayor frecuencia me he encotrado son: ISO-8859-1, UTF-8, MacRoman, ISO-8859-15, cp1252.
En este tutorial vamos a comentar muy brevemente los juegos de caracteres y mostrar un par de librerías de las que podemos hacer uso para intentar averiguar la codificación de un stream de bytes.
2. Entorno
- Mackbook Pro
- Intel Core i7 2Ghz
- 8GB RAM
- 500GB HD
- Sistema Operativo: Mac OS X (10.6.7)
3. Requisitos previos.
En este tutorial no hace falta ningún requisito previo
4. Descripcion de los juegos de caracteres.
En este apartado vamos a describir los principales rasgos o peculiaridades de los encodings que hemos comentado anteriormente.
- ASCII
-
Son las siglas de «American Standard Code for Information Interchange» y fue creado en 1963 por el comité estaunidense de estándares (que más tarde sería el instituto nacional estaunidense de estándares, ANSI).
El código ASCII utiliza 7 bits para representar los caracteres con lo que es capaz de representar 128 códigos distintos. Los 32 primeros códigos se utilizan para caracteres de control, por ejemplo, el carácter 27 representa la tecla escape (ESC).TRUCO: Si el stream que estamos leyendo no contiene bytes por encima del 0x7f, entonces está codificado en ASCII.
-
- ISO-8859-1
-
Es una extensión de ASCII que utiliza 8 bits que da soporte a otros idiomas como el caso del español. También se conoce como ISO Latin 1 . Esta codificación deja los primeros 128 caracteres intactos (los que componen a ASCII) y añaden valores adicionales por encima de los 7 bits. Estos valores son los caracteres diacríticos y letras especiales.
-
- ISO-8859-15
-
También es conocido como Latin-9. Es una revisión del ISO-8859-1 que incluyo el símbolo del euro. Puede representar inglés, aleman, francés, español, portugués, fines y estonio. Todos los caracteres imprimibles que existen en esta codificación también se encuentran en cp1252.
-
- MacRoman
-
Era un encoding usado principalmente por Mac OS, actualmente usa UTF-8
Los primeros 128 caracteres son identicos al ASCII por lo que es capaz de representar inglés
TRUCO: Si al leer el stream nos encontramos con los bytes 0x81, 0x8D, 0x8F, 0x90, 0x9D, podemos descartar cp1252 a favor de MacRoman.
-
- UTF-8
-
Incluye la especificación US-ASCII, por lo que cualquier mensaje ASCII se representa sin cambios. Utiliza simbolos de longitud variable (de 1 a 4 bytes). Si se produce un error al decodificar una cadena, nos mostrará el carácter U+FFFD.
TRUCO: Si el stream que vamos a leer empieza por 0xEF,0xBB,0xBF, podemos decir que está codificado en UTF-8, pero si no empieza por estos valores, no podemos descartar que no sea UTF-8
-
5. Usando librerías para averiguar el encoding.
Ahora vamos a describir par de librerias java que podemos usar para intentar averiguar el encoding.
-
juniversalchardet
Esta es la librería que mejor resultado me ha dado. Normalmente para averiguar el encoding necesita unas decenas de kilobytes.String detectCharset() { String encoding; try { final FileInputStream fis = new FileInputStream(file.getAbsolutePath()); final UniversalDetector detector = new UniversalDetector(null); handleData(fis, detector); encoding = getEncoding(detector); detector.reset(); fis.close(); } catch (IOException e) { encoding = ""; } return encoding; } private String getEncoding(UniversalDetector detector) { if(detector.isDone()) { return detector.getDetectedCharset(); } return ""; } private void handleData(FileInputStream fis, UniversalDetector detector) throws IOException { int nread; final byte[] buf = new byte[4096]; while ((nread = fis.read(buf)) > 0 && !detector.isDone()) { detector.handleData(buf, 0, nread); } detector.dataEnd(); } -
java.nio.charset
Esta librería no nos adivina el encoding, pero si podemos especificar un charset e intentar leer un stream de bytes y en caso de que encuentre un carácter que no pueda descodificar nos lanza una excepción. Este método no es efectivo 100%, ya que me he encontrado casos en los que al decodificar un stream no me ha lanzado una excepción y el charset obtenido no era el correcto. Cuanto mayor sea el stream, mayor probabilidad de acierto.String detectCharset() { for (String charsetName : avaliablesCharsets) { final Charset charset = detectCharset(file, Charset.forName(charsetName)); if (charset != null) { return charset.displayName(); } } return ""; } private Charset detectCharset(File f, Charset charset) { CharsetDecoder decoder = prepareCharsetDecoder(charset); return tryingCharset(f, decoder) ? charset : null; } private CharsetDecoder prepareCharsetDecoder(Charset charset) { return charset.newDecoder().reset(); } private boolean tryingCharset(File f, CharsetDecoder decoder) { try { final BufferedInputStream input = new BufferedInputStream(new FileInputStream(f)); final byte[] buffer = new byte[512]; boolean identified = false; while ((input.read(buffer) != -1) && (!identified)) { identified = identify(buffer, decoder); } input.close(); return identified; } catch (IOException ioException) { return false; } } private boolean identify(byte[] bytes, CharsetDecoder decoder) { try { decoder.decode(ByteBuffer.wrap(bytes)); } catch (CharacterCodingException e) { return false; } return true; } -
guessenc
Esta librería sólo es capaz de reconocer UTF-8, UTF-16LE, UTF-16BE, UTF-32, pero nos puede ser útil si sabemos que lo que vamos a recibir está codificado en uno de esos encodings.
Como experimento o prueba de concepto, escribí un pequeño programa que intenta averiguar el encoding de varios archivos haciendo uso de estas librerías.
El programa es un jar, que se llama aCharsetDetector que podéis bajaros de aquí.
El proyecto lo podéis bajar de aquí.
y aquí tenéis una captura de pantalla mostrando como funciona.
Primero vemos los ficheros con los que vamos a probar haciendo un ls -l en la consola, y a continuación ejecutamos el programa
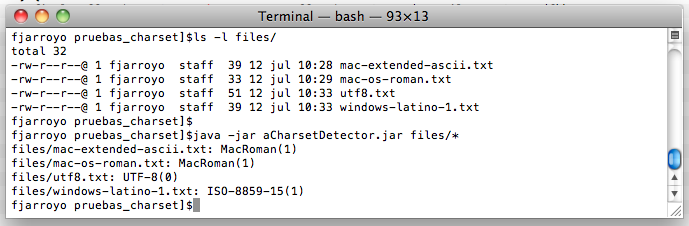
En la ejecución, se muestra el nombre del fichero seguido de dos puntos y el enconding que propone la aplicación.
El programa no es efectivo 100%, de hecho falla bastante con muestras pequeñas, pero como prueba de concepto creo que está bien ;).
6. Conclusiones
Si el tamaño de la muestra de la que queremos averiguar el enconding es suficientemente grande, hay bastantes posibilidades de que seamos capaz de adivinar el encoding usando las librerías que se muestran en el punto 5 del tutorial. Si por el encontrario, el tamaño es pequeño, se reducen drásticamente las posibilidades de adivinar el encoding porque mucha de las librerías que se pueden utilizar para adivinar el encoding de un archivo lo hacen a traves de estadísticas del lenguaje y de los juegos de caracteres.
Y con esto concluye el tutorial, si queréis preguntar cualquier cosa, no dudéis de utilizar el formulario que aparece al final de la página. Un saludo.
7. Referencias.
- http://www.utf8.com/
- http://es.wikipedia.org/wiki/UTF-8
- http://docs.codehaus.org/display/GUESSENC/Home
- http://download.oracle.com/javase/1.4.2/docs/api/java/nio/charset/package-summary.html
- http://code.google.com/p/juniversalchardet/
- http://es.wikipedia.org/wiki/ASCII
- http://en.wikipedia.org/wiki/Mac_OS_Roman

